ВИЗУАЛИЗАЦИЯ БОЛЬШИХ ОБЪЁМОВ НЕСТРУКТУРИРОВАННОЙ ИНФОРМАЦИИ НА ОСНОВЕ СПЕЦИАЛИЗИРОВАННЫХ ТЕЗАУРУСОВ
Б.Н. Оныкий (orcid.org/0000-0003-2560-1761), А.А. Артамонов (orcid.org/0000-0002-9140-5526), Е.С. Третьяков (orcid.org/0000-0002-1051-8562), К.В. Ионкина (orcid.org/0000-0001-6850-2443)
Национальный исследовательский ядерный университет «МИФИ», Москва, Российская Федерация
Содержание
2.1. Разработка тезауруса по объектам мониторинга
2.2. Идентификация информационных источников
Аннотация
В данной статье описываются стадии формирования базы данных по тематике «Ядерные материалы и реакторы нового поколения», которая включает информацию из различных структурированных и неструктурированных источников. Для анализа объема, структуры и частных случаев полученных данных был применен метод визуализации полученной информации в виде ненаправленного графа. Данный метод позволяет осуществлять навигацию между узлами графа по релевантным ребрам, что открывает возможности для раскрытия скрытых связей между объектами базы данных.
Ключевые слова: Граф, тезаурус, ядерный реактор, информационный поиск, агенты, data mining
1. Введение
В современном обществе информация является стратегическим ресурсом для принятия решений по ключевым вопросам хода развития тех или иных технологии или исследований. Многим научно-исследовательским институтам, лабораториям, коммерческим организациям и отдельным научным и инженерным коллективам во всем мире необходимо получать информацию касательно развития их научно-технического направления [1].
Информация такого рода публикуется в огромном количестве международных журналов в качестве научных публикаций, на сайтах информационных агентств и сайтах профильных компаний и организаций в качестве новостных сообщений.
Доступ к данному кластеру информации, в современном мире, осуществляется посредством сети Интернет. В сети Интернет информация может быть размещена в различном виде, а количество всей информации, в том числе и непрофильной для научных организаций и коллективов, стремительно растет. Таким образом, ориентация во всем этом информационном пространстве без специальных инструментов, т.е. в диалоговом режиме, становится невозможным.
На сегодняшний день существует множество информационно-поисковых систем (ИПС), такие как Google, Yandex, Baidu, которые круглосуточно проводят индексацию информации в сети Интернет и предоставляют свой результат работы пользователям сети Интернет по всему миру [2]. Такие ИПС направлены на работу с большим сектором пользователей сети Интернет, т.е. среднестатистическим пользователем, который чаще всего формирует свои запросы для нахождения информации касательно товаров и услуг общего назначения.
Таким образом, для ориентации в сфере научных исследований стали разрабатываться и внедрятся реферативные и полнотекстовые базы данных, которые ведут учет публикаций из различных научных журналов, в качестве примера подобных баз данных можно привести реферативную базу данных – “Web of Science” (Web of Knowledge) и полнотекстовую базу данных – “ScienceDirect” [3],[4].
Такие базы данных являются эффективными при поиске научных публикаций определенного автора, однако, если необходимо найти кластер информации по специфическому направлению, приходится использовать расширенные запросы и прибегать к специальному синтаксису поискового инструмента, что, в итоге, не гарантирует получение пертинентной информации.
Решением проблемы поиска информации по специальному научному направлению могут быть информационно-аналитические системы (ИАС), которые при поиске информации в сети Интернет используют агентные технологии, так как агенты, в зависимости от своей специализации, способны агрегировать информацию из различных источников информации будь то источники неструктурированной информации – сайты университетов, институтов, коммерческих компаний и информационных агентств, так и источники структурированной информации – базы данных “Web of Science”, “ScienceDirect”.
Кроме проблемы сбора соответствующей информации, возникает проблема визуализации информации для проведения анализа пользователем. В статье рассматриваются вопросы сбора и визуализации информации по специальным тематическим направлениям, например, «Ядерные материалы и реакторы нового поколения».
2. Методология
2.1. Разработка тезауруса по объектам мониторинга
Поисковые мероприятия включают в себя процесс формирования тезауруса по объектам мониторинга на основе различных поисковых операций в информационно-поисковых системах (ИПС), таких как Google, Yandex, Duckduckgo, а также в условно закрытых базах данных, таких как Web of Science, Science Direct и Nexis. Формирование тезауруса по объектам мониторинга также включает в себя разработку поисковых образов.
Поисковый образ – это шаблон на языке регулярных выражений, который строится на основе термина из тезауруса объектов мониторинга и позволяет проводить точный поиск путем регламентации правил нахождения термина в тексте, например, учет морфологии, регистра, вхождения лексических единиц внутри составного термина.
Поисковые мероприятия также включают в себя процесс идентификации информационных источников по принципу вхождения в него релевантной и достоверной информации, а также алгоритмы сбора информации с различных информационных источников [5].
В ходе формирования тезауруса объектов мониторинга по тематике «Ядерные материалы и реакторы нового поколения» было обнаружено 379 терминов, которые включают в себя названия и аббревиатуры проектов, химических элементов, физических явлений составных частей реакторов по релевантному направлению. Каждый термин обладает своим уникальным поисковым образом, за счет чего достигается высокая точность обнаружения термина в тексте.
Тезаурус был сформирован исходя из анализа поисковой выдачи различных ИПС и баз данных после применения к ним, релевантных данному направлению, простых и сложных поисковых запросов.
Тезаурус интегрирован в базу данных и позволяет проводить полнотекстовый поиск и выделение фактографических данных из всей собранной информации по данному направлению (пример тезауруса приведен в таблице 1).
Таблица 1. Пример тезауруса объектов мониторинга по направлению «Ядерные материалы и реакторы нового поколения».
|
№ |
Объект мониторинга |
Поисковый образ |
Регистр |
|
1 |
accelerator driven system |
(?<!\w)accelerator(.{0,3}?|(\s?\w+\s){0,2})driven(.{0,3}?|(\s?\w+\s){0,2})system |
case_insensitive |
|
2 |
acid deficiency uranium nitrate |
(?<!\w)acid(.{0,3}?|(\s?\w+\s){0,2})deficiency(.{0,3}?|(\s?\w+\s){0,2})uranium(.{0,3}?|(\s?\w+\s){0,2})nitrate |
case_insensitive |
|
3 |
active magnetic bearing for helium blower |
(?<!\w)active(.{0,3}?|(\s?\w+\s){0,2})magnetic(.{0,3}?|(\s?\w+\s){0,2})bearing(.{0,3}?|(\s?\w+\s){0,2})for(.{0,3}?|(\s?\w+\s){0,2})helium(.{0,3}?|(\s?\w+\s){0,2})blower |
case_insensitive |
|
4 |
ADS |
(?<!\w)ADS |
case_sensitive |
|
5 |
ADUN |
(?<!\w)ADUN |
case_sensitive |
|
6 |
advanced lead fast reactor european demonstrator |
(?<!\w)advanced(.{0,3}?|(\s?\w+\s){0,2})lead(.{0,3}?|(\s?\w+\s){0,2})fast(.{0,3}?|(\s?\w+\s){0,2})reactor(.{0,3}?|(\s?\w+\s){0,2})european(.{0,3}?|(\s?\w+\s){0,2})demonstrator |
case_insensitive |
|
7 |
advanced sodium technological reactor |
(?<!\w)advanced(.{0,3}?|(\s?\w+\s){0,2})sodium(.{0,3}?|(\s?\w+\s){0,2})technological(.{0,3}?|(\s?\w+\s){0,2})reactor |
case_insensitive |
|
8 |
advanced sodium technological reactor for industrial demonstration |
(?<!\w)advanced(.{0,3}?|(\s?\w+\s){0,2})sodium(.{0,3}?|(\s?\w+\s){0,2})technological(.{0,3}?|(\s?\w+\s){0,2})reactor(.{0,3}?|(\s?\w+\s){0,2})for(.{0,3}?|(\s?\w+\s){0,2})industrial(.{0,3}?|(\s?\w+\s){0,2})demonstration |
case_insensitive |
|
9 |
ALCYONE |
(?<!\w)ALCYONE |
case_sensitive |
|
10 |
ALFRED |
(?<!\w)ALFRED |
case_sensitive |
2.2. Идентификация информационных источников
В ходе формирования базы информационных источников были проанализированы источники со структурированными и неструктурированными данными.
К источникам со структурированными данными относятся источники, располагающие информацией об объектах, которые имеют свою модель данных и которые хранятся в особой структуре, что позволяет проводить различные аналитические операции, например, полнотекстовый поиск по определенным атрибутам объекта. Примером таких источников могут служить базы данных Web of Science, Science Direct [3],[4].
К источникам с неструктурированными данными относятся полнотекстовые базы данных, в которых не предусмотрен поиск по отдельным атрибутам объекта, и веб-порталы, где информация об объекте представлена неструктурированным образом.
В ходе анализа неструктурированных источников информации было выявлено порядка 90 веб-порталов информационных агентств, веб-сайтов компаний и организаций по всему миру, также было принято решение о мониторинге базы данных средств массовой информации и бизнес-информации компании LexisNexis, которая ведет сбор информации с более чем 35 000 источников. Пример списка веб-сайтов, на которые настроен ежедневный сбор информации приведен в таблице Таблица 2.
Таблица 2. Веб-сайты по тематике «Ядерные материалы и реакторы нового поколения.
|
№ |
Название |
Страница мониторинга |
|
1 |
allthingsnuclear.org |
http://allthingsnuclear.org/ |
|
2 |
cnnphilippines.com |
http://cnnphilippines.com/news/ |
|
3 |
dailynewshungary.com |
http://dailynewshungary.com/ |
|
4 |
en.interfax.com.ua |
http://en.interfax.com.ua/ |
|
5 |
en.mehrnews.com |
http://en.mehrnews.com/archive?all=1 |
|
6 |
eng.belta.by |
http://eng.belta.by/ |
|
7 |
english.aawsat.com |
http://english.aawsat.com/ |
|
8 |
ahram.org.eg |
http://english.ahram.org.eg/ |
|
9 |
english.sina.com |
http://roll.news.sina.com.cn/s/channel.php?ch=28#col=298&spec=&type=&ch=28&k=&offset_page=0&offset_num=0&num=60&asc=&page=1 |
В ходе сбора информации с источников со структурированными данными формировались специализированные расширенные запросы. Помимо общих запросов по тематической области также формировались узкоспециализированные запросы по объектам мониторинга для увеличения коэффициента полноты поисковой выдачи. Для последующего анализа полученных данных с веб-порталов, были написаны собственные специализированные конверторы данных, которые способны конвертировать данные в необходимый для анализа модель данных.
Сбор информации с источников с неструктурированными данными осуществляется при помощи агентных технологий. Агент – это программа, приводимая в действие по заранее запланированному расписанию, обладающая определенным уровнем автономности для осуществления сбора информации в сети Интернет на заранее определенном информационном ресурсе. В целях мониторинга большого количества информационных ресурсов была разработана специализированная система, которая обладает функциями манипуляции агентов, а также хранения и обработки поступающей информации. В ходе сбора материалов для базы данных по тематике «Ядерные материалы и реакторы нового поколения» в первую неделю было собрано более 10 000 новостных сообщений, из которых всего 16 оказались релевантными, что говорит о низкой плотности публикации информации по данному направлению.
3. Результаты
Интегральная база данных по направлению «Ядерные материалы и реакторы нового поколения» была сформирована посредством обработки поисковых выдач баз данных структурированной информации Web of Science, Science Direct, Nexis и информационных сообщений с веб-сайтов с неструктурированной информацией. Всего интегральная база данных включает в себя 599 записей релевантных материалов. Помимо записей материалов по релевантной тематике в интегральную базу данных входит тезаурус объектов мониторинга, словарь жизненного цикла.
Все полученные сообщения прошли обработку в фактографическом процессоре – это надстраиваемый программный модуль, позволяющий в автоматизированном режиме извлекать факты первого и второго порядка. Для выделения фактографических данных программному модулю необходимо наличие тезауруса объектов мониторинга и словарь жизненного цикла, который включает в себя глаголы, указывающие на тот или иной уровень технологической готовности.
Алгоритм выделения фактов заключается в разделении поступающего текста на предложения, в которых ведется поиск объектов мониторинга, если такой объект в предложении был идентифицирован, то это предложение становится фактом первого порядка [6]. Для определения факта второго порядка необходима идентификации объекта мониторинга в паре с термином из словаря жизненного цикла.
В рамках проведения обработки данных вся полученная информация была приведена в общий формат, были выявлены фактографические данные, отобраны пертинентные записи базы данных.
На основе полученных 599 записей был построен граф с целью осознания пользователем масштабов и структуры обработанных данных, а также с целью предоставления пользователю функций кластеризации материалов на основе выделенных узлов и ребер. Граф был построен на основе алгоритма Фрухтермана Рейнгольда (Рисунок 1). При построении графа использовалось программное обеспечение Gephi.
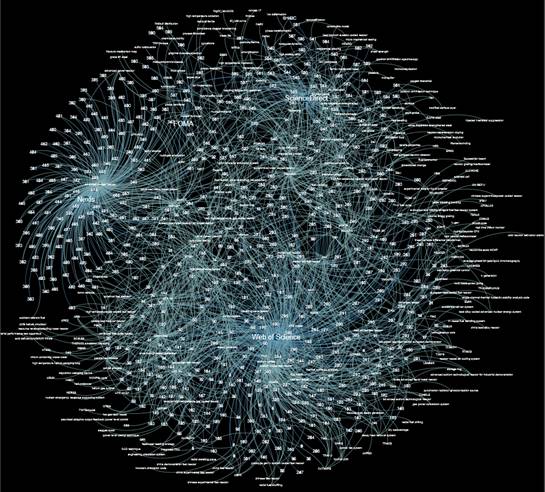
Рис. 1. Графовое представление информации на основе алгоритма Фрухтермана Рейнгольда.
Узлами графа являются три типа источника информации, ключевые слова из тезауруса по «Ядерным материалам и реакторам нового поколения», типы источников и идентификационный номер релевантного документа.
По данному представлению пользователь может осуществлять навигацию по всей коллекции документов. Представление позволяет пользователю определить, наиболее часто встречаемые понятия из тезауруса и их связь с источником.
Визуальный анализ графа позволяет сделать оперативные выводы о встречаемости ключевых слов из тезауруса – наименее встречаемые слова находятся на «внешней орбите», наиболее встречаемые слова концентрируются в центре; о материалах, в которых встречается наибольшее количество ключевых слов (смещены к центру) и об отношении материалов к источникам информации.
На рисунке 2 изображен фрагмент графа, на котором видно связи между ключевым словом «advanced nuclear reactor» и источником информации Nexis. На основе рисунка можно сделать выводы о принадлежности материала к источнику – Nexis и соответствующему ключевому слову – «advanced nuclear reactor».
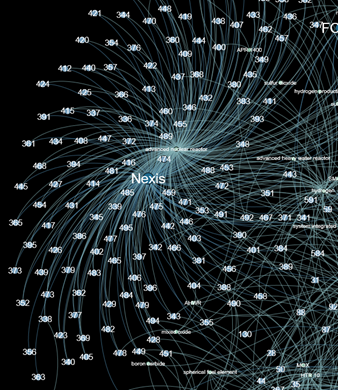
Рис. 2. Фрагмент графа.
Использование графа, как визуальное представление базы данных позволяет пользователю определить наиболее интересные для него материалы и ознакомится с ними непосредственно в интегральной базе данных.
4. Выводы
В качестве результатов проведенных мероприятий по формированию базы данных материалов по тематическому направлению «Ядерные материалы и реакторы нового поколения» была сформирована соответствующая база данных. Для анализа контента базы данных был применен метод визуализации информации на основе построения графа. Данный метод открыл возможности для анализа скрытых связей между объектами на основе осуществления переходов между узлами графа, а также позволил произвести кластеризацию данных на основе ключевых слов.
Список литературы
1. Onykiy B.N., Artamonov A.A., Ananieva A.G., Tretyakov E.S., Pronicheva L.V., Ionkina K.V., Suslina A.S. Agent Technologies for Polythematic Organizations Information-Analytical Support. Procedia Computer Science. Vol. 88. 2016. pp 336-340
2. Salton, G., McGill, M.J. Introduction to Modern Information Retrieval. (1986)
3. Abstract database Web of Science URL: https://webofknowledge.com/ (Date of access: 30.08.2017)
4. Abstract database Scopus URL: https://www.scopus.com/ (Date of access: 30.08.2017)
5. Artamonov A.A., Leonov D.V., Nikolaev V.S., Onykiy B.N., Pronicheva L.V., Sokolina K.A., Ushmarov I.A. Visualization of semantic relations in multi-agent systems. Scientific Visualization. 2014. Vol. 6. No. 3. pp 68-76.
6. Onkiy B.N., Tretyakov E.S., Pronicheva L.V., Galin I.Yu., Ionkina K.V., Cherkasskiy A.I. Methodology of Learning Curve Analysis for Development of Incoming Material Clustering Neural Network, Proceedings of the First International Early Research Career Enhancment School on BICA and Cybersecurity (FIERCES 2017). 2017. pp 133-138
VISUALIZATION OF LARGE SAMPLES OF UNSTRUCTURED INFORMATION ON THE BASIS OF SPECIALIZED THESAURUSES
B.N. Onykiy, A.A. Artamonov, E.S. Tretyakov, K.V. Ionkina
National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation
Abstract
The database on “Nuclear materials and Advanced nuclear reactors” development stages are described in this paper. The database comprises items from various information sources of structured and unstructured types. The approach of received data visualisation development as an unoriented graph was conducted in order to analyze the volume, structure, and particular cases of the data obtained. This method enables user to navigate between graph’s nodes through its edges in order to reveal unavowed relations between database items.
Keywords: Graph, thesaurus, nuclear reactor, information retrieval, agents, data mining
References
1. Onykiy B.N., Artamonov A.A., Ananieva A.G., Tretyakov E.S., Pronicheva L.V., Ionkina K.V., Suslina A.S. Agent Technologies for Polythematic Organizations Information-Analytical Support. Procedia Computer Science. Vol. 88. 2016. pp 336-340
2. Salton, G., McGill, M.J. Introduction to Modern Information Retrieval. (1986)
3. Abstract database Web of Science URL: https://webofknowledge.com/ (Date of access: 30.08.2017)
4. Abstract database Scopus URL: https://www.scopus.com/ (Date of access: 30.08.2017)
5. Artamonov A.A., Leonov D.V., Nikolaev V.S., Onykiy B.N., Pronicheva L.V., Sokolina K.A., Ushmarov I.A. Visualization of semantic relations in multi-agent systems. Scientific Visualization. 2014. Vol. 6. No. 3. pp 68-76.
6. Onkiy B.N., Tretyakov E.S., Pronicheva L.V., Galin I.Yu., Ionkina K.V., Cherkasskiy A.I. Methodology of Learning Curve Analysis for Development of Incoming Material Clustering Neural Network, Proceedings of the First International Early Research Career Enhancment School on BICA and Cybersecurity (FIERCES 2017). 2017. pp 133-138