ВИЗУАЛИЗАЦИЯ СЕМАНТИЧЕСКИХ ОТНОШЕНИЙ В МУЛЬТИАГЕНТНЫХ СИСТЕМАХ
А.А. АРТАМОНОВ, Д.В. ЛЕОНОВ, В.С. НИКОЛАЕВ, Б.Н. ОНЫКИЙ, Л.В. ПРОНИЧЕВА, К.А. СОКОЛИНА, И.А. УШМАРОВ
Национальный исследовательский ядерный университет «МИФИ»
AAArtamonov@mephi.ru, DVLeonov@mephi.ru, VSNikolayev@mephi.ru, BNOnykij@mephi.ru, LVPronicheva@mephi.ru, KASokolina@mephi.ru, i.ushmarov@gmail.com
Оглавление
· 2. Визуализация мирового кластера источников тематической информации
· 3. Визуализация в виде семантических сетей
Аннотация
В статье рассматриваются вопросы визуализации данных в Мультиагентных информационно-аналитических системах по естественнонаучным и технологическим направлениям. Подробно рассмотрены две базовые модели визуализации – табличная и сетевая. Предметно рассматриваются задачи визуализации как объектов в базах знаний, так и различных типов отношений между ними.
Ключевые слова: информационные технологии, мультиагентные системы, корпоративные сети, семантические сети, облачные структуры.
В современных информационно-аналитических системах различного назначения все шире используются агентные технологии [1],[2],[3].
Здесь под агентной технологией понимается регулярный целевой автоматический поиск тематической информации в заданном кластере сайтов сети интернет. Агентом будем называть сетевую поисковую программу, управляемую следующими данными:
- имя владельца агента и его адрес для регулярной доставки заданной новостной тематической информации и обращений за инструкциями в нештатных ситуациях;
- поисковые предписания (ключевые слова) из тезауруса тематической области на заданных национальных языках;
- адреса сайтов в кластере сканирования;
- частота сканирования тематического кластера.
Это определение поискового агента и агентных технологий соответствует определению, принятому 11 комитетом по стандартизации IEEE Computer Society FIPA (Foundation for Intelligent Physical Agents).[4]
Обзор приложений агентных технологий [5] показывает, что большинство известных приложений связано с решением задач дистанционного контроля и управления, целевого сбора и упорядочивания данных из различных информационных источников, интегрирование данных по времени и в пространстве, маркетингового наблюдения и т.д.
Работа авторов относится к другому классу систем – «Мультиагентные информационно-аналитические системы по естественнонаучным и технологическим направлениям (МИАС)». В результате опытной разработки и экспериментальной эксплуатации такой системы в Национальном исследовательском ядерном университете МИФИ (Москва, Россия) авторы пришли, в частности, к следующему заключению. Основное назначение МИАС состоит в формировании, модификации и практическом использовании баз знаний по заранее заданным тематическим направлениям. Следовательно, МИАС должна обладать развитыми средствами визуализации не только различных типов объектов, но и различных типов отношений между ними.
На определенном уровне абстракции эту задачу можно рассматривать как задачу визуализации графовых моделей, отвлекаясь от физического смысла узлов и дуг графа [6]. Такой подход вполне оправдан только для разработки инструментальных программ визуализации графов или сетей. В тематических базах знаний МИАС по определению нельзя абстрагироваться от физической природы сетевой модели. «Семантические сети» рассматриваются как фрагменты знаний, к которым применимы все технологические этапы обработки данных: формирование, хранение, поиск, модификация данных внутри сети, операции над сетями.
В данной статье авторы описывают решение задач визуализации семантических отношений в форме таблиц и сематических сетей.
2. Визуализация мирового кластера
источников тематической информации
С развитием сети Интернет существенно увеличилось количество доступных пользователю источников научно-технической информации. К традиционным источникам добавились сайты университетов, научных центров, отдельных лабораторий, кафедр, неформальных рабочих групп и, наконец, сайты специалистов. Эти новые источники информации оказались привлекательными для специалистов в различных тематических областях, так как новостная информация на этих сайтах появляется на несколько месяцев раньше, чем в журналах, и возможен прямой диалог с авторами. Однако, наряду с увеличением потенциально доступных информационных ресурсов, происходит рассеивание информации и, как следствие, увеличивается время и трудоемкость её поиска.
Агентные технологии освобождают специалистов от этих трудозатрат. Мировые кластеры источников тематической информации отображаются в соответствующих базах данных, где в качестве атрибутов, в частности, указываются адреса сайтов для настройки поисковых роботов на конкретную область поиска.
Рассмотрим задачи визуализации подобных баз данных на примере базы данных «Мировые научно-исследовательские и технологические организации по Физике плазмы». Эта база данных была создана кафедрами «Физика плазмы» №21 и «Анализ конкурентных систем» №65 НИЯУ МИФИ при выполнении проекта по ФЦП «Научные и научно-педагогические кадры инновационной России». База данных зарегистрирована в Федеральной службе по интеллектуальной собственности, свидетельство о регистрации № 2014620346.
Заинтересованный читатель может получить её в полном объеме, обратившись к официальному сайту кафедры №65 «Анализ конкурентных систем» по сетевому адресу http://kaf65.mephi.ru.
Упомянутая база данных представляет собой структурированный архив сведений о мировых научно-исследовательских и технологических организациях и их подразделениях, занимающихся исследованиями в области физики плазмы. В этой базе данных приведены основные контактные данные и список источников для мониторинга сайтов организаций с целью получения актуальной новостной информации об исследованиях.
На рисунке 1 представлена макроструктура базы данных «Мировые научно-исследовательские и технологические организации по Физике плазмы»
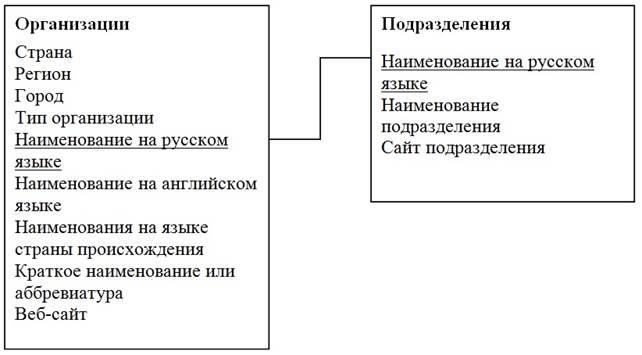
Рис. 1. Макроструктура базы данных «Мировые научно-исследовательские и технологические организации по Физике плазмы»
Из рисунка видно, что существующая база данных может естественным образом развиваться путем введения в неё объекта «специалист» и табличной визуализацией отношений с уже имеющимися объектами: «Организация», «Подразделение».
В таблицах 1 и 2 представлены типы данных, описывающих объекты «Организация» и «Подразделение». Таблицы наглядно показывают существенную особенность базы данных – мультиязычность.
Отсюда следует очевидное правило формирования поисковых предписаний для роботов – предписание должно быть составлено на языке анализируемого сайта.
Таблица 1. Типы данных объекта «Организация»
|
Наименование поля |
Тип данных |
Описание |
|
Strana |
mediumtext |
Страна |
|
Region |
mediumtext |
Регион |
|
Gorod |
mediumtext |
Город |
|
Tip |
mediumtext |
Тип организации |
|
Rusname |
text |
Наименование на русском языке |
|
Engname |
text |
Наименование на английском языке |
|
Forname |
text |
Наименование на языке страны происхождения (для зарубежных неанглоязычных организаций) |
|
Shortname |
mediumtext |
Краткое наименование или аббревиатура |
|
Website |
longtext |
Веб-сайт |
Таблица 2 Типы данных объекта «Подразделение»
|
Наименование поля |
Тип данных |
Описание |
|
Rusname |
text |
Наименование на русском языке |
|
Department |
text |
Наименование подразделения (физика плазмы) |
|
Depwebsite |
text |
Сайт подразделения |
Пример табличной визуализации объектов «Организация» представлен на рис. 2.
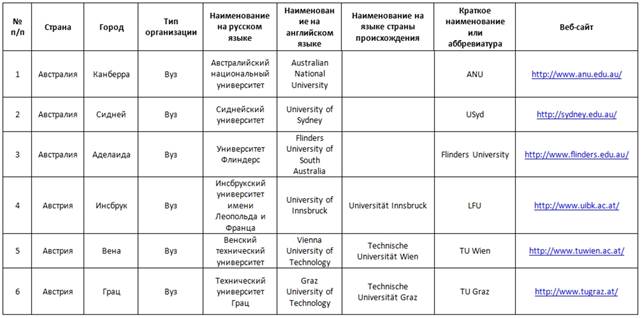
Рис.2. Фрагмент таблицы данных объектов «Организация»
На рис. 3 представлен фрагмент второй части базы данных – таблица «Подразделение». Веб-адреса подразделений содержат информацию по исследуемой тематической области (физика плазмы) и используются для настройки агентов.
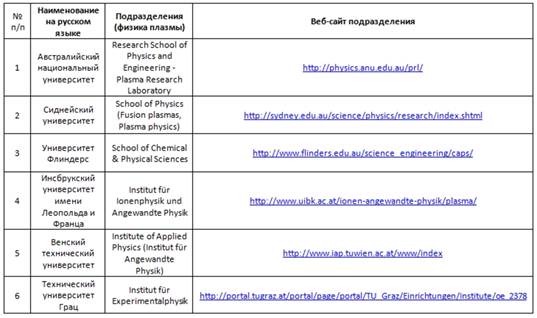
Рис.3. Фрагмент таблицы данных объектов «Подразделение»
Текущий объем базы данных или, другими словами, мировой кластер сайтов организаций, ведущих исследования и разработки по Физике плазмы составляет приблизительно 200 единиц. Обращение поисковых роботов к этим сайтам в процессе поиска новостной информации не всегда бывает успешным. В экспериментах, проведенных авторами только 50% сайтов, опрошенных поисковыми роботами, дали целевую информацию.
По этой причине оптимизация процедур агентного сканирования требует динамической классификации пространства сканирования и визуализации классов источников, например, по принципу светофора:
· зеленая подсветка - сохранение режима регулярного автоматизированного обращения к сайту;
· желтая подсветка - отказ от агентного взаимодействия по известной причине, например, получение информации требует предварительной оплаты и т.д.;
· красная подсветка - отказ от взаимодействия по неизвестным причинам.
Очевидно, что в каждом из рассмотренных случаев системный администратор должен принимать различные решения.
На рис. 4 изображен фрагмент модифицированного изображения таблицы «Подразделение» с добавлением столбца «Доступность сайта». Поле «ссылка» представляет собой веб-адрес новостной ленты соответствующего ресурса.
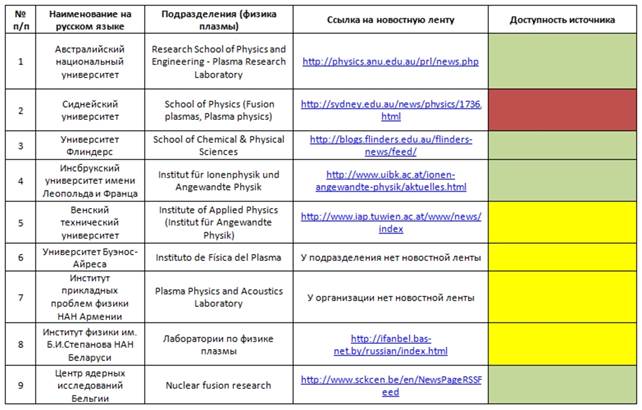
Рис.4. Модификация изображения таблицы «Подразделение» с добавлением «светофора»
Напомним, что сейчас мы реализуем задачу сокращения маршрутов сканирования. Для её быстрого решения оператору достаточно двух последних столбцов таблицы на рисунке 4, остальные столбцы сохранены для визуального контроля операций по отмене маршрутов.
Таким образом, «раскрашивание» оказывается простым и удобным способом визуализации таких семантических отношений как состояние объекта или принадлежность к некоторому классу и т.д.
При программировании визуальных интерфейсов всегда возникают вопросы – почему это изображено так, а не иначе. Например, почему «светофор» нельзя было бы наложить прямо на столбец с адресами сайтов. Это уже вопросы компьютерного дизайна, которые мы здесь не рассматриваем. В частности, в приведенном примере наложение полутонов снижает четкость текста и осложняет его восприятие.
3. Визуализация
в виде семантических сетей
Одним из способов визуализации знаний являются семантические сети. Такие сети имеют вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть любые реальные или виртуальные сущности, понятия, события, свойства, процессы и т.д. Краткость и одновременно емкость таких схем позволяют считать их одним из наиболее эффективных инструментов отображения информации для последующего анализа.
Рассмотрим данный тип визуализации с использованием базы данных «Мировые научно-исследовательские и технологические организации по Физике плазмы».
Между объектами базы (рис. 2, 3) можно установить следующие отношения:
· Страна – город (структурное отношение «общее-частное»);
· Город – организация (отношение принадлежности (привязка к территории);
· Организация – подразделение (структурное отношение «общее-частное»).
Последующее развитие базы путем введения в неё объекта «специалист» позволит ввести также отношение «Организация – специалист».
На рисунке 5 представлен фрагмент такой семантической сети.
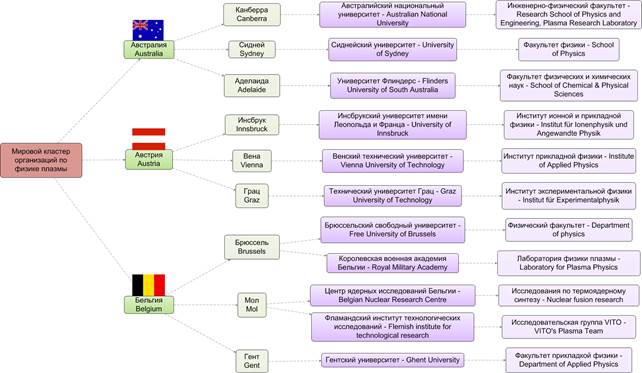
Рис.5. Фрагмент семантической сети «Мировые научно-исследовательские и технологические организации по Физике плазмы»
В визуальном представлении семантических сетей могут быть использованы различные цветовые дифференциации типов сущностей. Авторами принята следующая цветовая дифференциация:
· Красный – рубрика;
· Зеленый – страна (оттенки зеленого – территориальные области страны);
· Фиолетовый – организации (оттенки фиолетового – структурные подразделения);
· Голубой – событие;
· Серый – факт;
· Желтый – персона.
Результатом работы агентов по сканированию источников являются тематические статьи (текстовые документы), автоматически полученные из новостных лент организаций/подразделений.
В качестве примера рассмотрим статью из новостной ленты ITER (ITER Newsline - http://www.iter.org/newsline) на рис. 6.

Рис.6. Статья «День ITER в Москве»
Извлечение знаний из документов (объектов, фактов, связей между ними) также позволяет строить семантические сети. Так, визуализация знаний, полученных из вышеуказанной статьи, представляет собой схему на рис. 7.
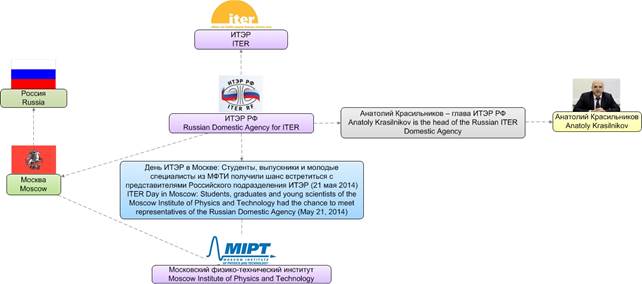
Рис.7. Визуализация знаний, полученных из тематической новостной статьи
Очевидно, что в таком виде информация представлена одновременно и просто для восприятия, и наглядно.
При постоянной обработке поступающих в базу данных статей количество объектов и связей возрастает. Это позволяет аккумулировать знания по тематической области (в данном случае – физика плазмы) совершенно различного характера и отслеживать цепочки связей между объектами. Очевидна также взаимодополняемость базы организация/подразделение и результатов работы агентов.
Полная схема связей в тематической области представляет собой объемный, быстро растущий массив данных. Поэтому необходима фильтрация объектов и их связей под конкретные аналитические задачи.
Например, на рис. 8 представлен фрагмент сети кооперационных связей в проекте ITER.
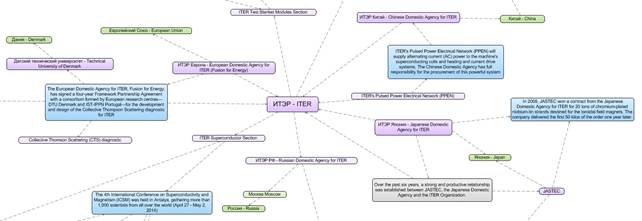
Рис.8. Фрагмент семантической сети «Кооперация в проекте ITER»
Ясно, что на рисунке 8 могли бы быть и другие объекты, например, поставщики ITER. Могут быть и другие типы отношений, например, счета поставщиков с раскрашиванием стрелок, полученные и оплаченные счета. Т.е. разнообразие семантических сетей, описывающих отношения между объектами тематической области, определяется прикладными задачами пользователей, а инструментарий построения и визуализации семантических сетей может оставаться неизменным.
Выше упоминалось, что к задачам визуализации информации в агентных интеллектуальных технологиях авторы пришли при разработке и экспериментальной эксплуатации МИАС – Мультиагентной информационно-аналитической системы по естественно-научным и технологическим направлениям.
В работе использовался инструментальный программный комплекс компании «Аналитические бизнес решения» объединенный в систему «Семантический архив»[6].
Любая технология информационно-аналитической работы, независимо от степени автоматизации процедур обработки данных, в конечном счете, требует представления результатов пользователю. При этом оказывается одинаково важным и быстрый просмотр большого объема сложноорганизованной информации свернутой в семантическую сеть, и детальный анализ фрагментов баз данных, представленных таблицами.
Авторы старались построить систему, позволяющую рационально сочетать эти два подхода, сохраняя смысловые и количественные значения данных в разных моделях.
Авторы выражают благодарность физикам Национального исследовательского ядерного университета МИФИ профессору В.А.Курнаеву, заведующему кафедрой «Физика плазмы»; профессору А.А. Петрухину, руководителю центра «НЕВОД»; доценту В.Н.Петровскому, руководителю центра лазерных технологий за содержательные консультации по своим научным тематическим направлениям и представление необходимой информации для стартовой настройки поисковых роботов.
1. Tim Berners-Lee, 2001, The Semantic Web (A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities), Scientific American: May 2001
2. В.И. Будзко. Д.В. Леонов, В.С. Николаев, Б.Н. Оныкий, К.А. Соколина. Развитие информационно-аналитической поддержки научно-технической деятельности в Национальном исследовательском ядерном университете «МИФИ» //Системы Высокой доступности. 2011. №4, т.7, стр. 4-17.
V.I. Budzko, D.V. Leonov, V.S. Nikolayev, B.N. Onykiy, K.A. Sokolina. Development of Information and Analytical Support for Scientific and Research Activities in the National Nuclear Research University «MEPHI» // Highly available systems. 2011. №4, vol.7, p. 4-17.
3. Lieberman H., Selker T. Agents for the user interface // Handbook of Agent Technology. – 2003. – С. 1-21.
4. Решение 11 комитета по стандартизации IEEE Computer Society FIPA http://www.computer.org/portal/web/sab/foundation-intelligent-physical-agents
5. В. Касьянов, Е. Касьянова. Визуализация информации на основе графовых моделей // Научная визуализация. 2014. Квартал 1. №1, т.6, стр. 31-50
V. Kasyanov, E. Kasyanova. Information Visualization on the Base of Graph Models // Scientific Visualization. 2014. Quarter 1, №1, vol.6, p. 31-50
6. Официальный сайт компании «Аналитические бизнес решения» http://www.anbr.ru/
VISUALIZATION OF SEMANTIC RELATIONS IN MULTI-AGENT SYSTEMS
A.A. ARTAMONOV, D.V. LEONOV, V.S. NIKOLAEV, B.N. ONYKIY, L.V. PRONICHEVA, K.A. SOKOLINA, I.A. USHMAROV
National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation
AAArtamonov@mephi.ru, DVLeonov@mephi.ru, VSNikolayev@mephi.ru, BNOnykij@mephi.ru, LVPronicheva@mephi.ru, KASokolina@mephi.ru, i.ushmarov@gmail.com
Abstract
The paper reviews issues of data visualization in Multi-agent information analysis systems on scientific and technological areas. Two basic models of visualization – tabular and network – are reviewed in detail. The paper focuses on issues of visualizing database objects as well as different kinds of relations between them.
Keywords: information technologies, multi-agent systems, corporate networks, semantic networks, cloud structures.
1. Tim Berners-Lee, 2001, The Semantic Web (A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities), Scientific American: May 2001
2. V.I. Budzko, D.V. Leonov, V.S. Nikolayev, B.N. Onykiy, K.A. Sokolina. Development of Information and Analytical Support for Scientific and Research Activities in the National Nuclear Research University «MEPHI» // Highly available systems. 2011. №4, vol.7, p. 4-17.
3. Lieberman H., Selker T. Agents for the user interface // Handbook of Agent Technology. – 2003. – P. 1-21.
4. IEEE Computer Society Foundation for Intelligent Physical Agents Standards Committee Policies & Procedures http://www.computer.org/portal/web/sab/foundation-intelligent-physical-agents
5. V. Kasyanov, E. Kasyanova. Information Visualization on the Base of Graph Models // Scientific Visualization. 2014. Quarter 1, №1, vol.6, p. 31-50
6. Analytical Business Solutions Ltd. official website http://www.anbr.ru/en