ИНТЕГРАЦИЯ ИНФОРМАЦИОННОЙ СИСТЕМЫ СЕМОГРАФ И ВИЗУАЛИЗАТОРА SCIVI ДЛЯ РЕШЕНИЯ ЗАДАЧ ЭКСПЕРТНОГО АНАЛИЗА ЯЗЫКОВОГО КОНТЕНТА
К.В. Рябинин, Д.А. Баранов, К.И. Белоусов
Пермский государственный национальный исследовательский университет, Пермь, Россия
kostya.ryabinin@gmail.com, baranov@semograph.com, belousovki@gmail.com
Оглавление
2. Встраиваемая версия системы SciVi
3. Концепция интеграции с системой Семограф
4. Пополнение набора средств визуализации системы SciVi
Аннотация
В данной статье рассматриваются вопросы развития системы научной визуализации SciVi, разработанной авторами ранее. Эта система построена на основе методов и средств онтологического инжиниринга: её поведение управляется базой знаний, включающей в себя онтологии визуальных объектов, фильтров входных данных и основных синтаксических конструкций языков программирования, на которых могут быть написаны сторонние генераторы подлежащих визуализации данных. Такой подход позволяет быстро адаптировать систему SciVi к работе с произвольными источниками данных (включая программно-аппаратные решатели), а также к решению конкретных задач визуализации из любой предметной области. Процесс адаптации происходит посредством работы пользователя в высокоуровневом графическом интерфейсе. Добавление в систему новых средств визуального представления или предобработки данных производится путём пополнения соответствующих онтологий, без необходимости внесения изменений в исходный код ядра системы.
Архитектура системы SciVi построена на принципах клиент-серверного взаимодействия. Задачей сервера является сбор и предварительная обработка данных, подлежащих визуализации (а также частичный рендеринг, если быстродействие клиента недостаточно высоко). Клиент, в свою очередь, отвечает за отображение результата визуализации и предоставляет пользователю графический интерфейс.
Изначально система SciVi разрабатывалась как самостоятельное модульное приложение. Однако в ряде случаев полезно иметь возможность встраивания отдельных её модулей в сторонние по отношению к ней программные продукты.
В данной работе рассматривается выделение из системы SciVi настраиваемого модуля визуализации и встраивание его состав информационной системы графосемантического моделирования Семограф. Выделенный модуль, являясь, по сути, самостоятельным программным средством, тем не менее остаётся частью системы SciVi, наследуя от неё управляемость онтологической базой знаний о доступных графических объектах, типах сцен и семантических фильтрах. Как следствие, он имеет возможность расширения функциональности и гибкой настройки на различные задачи визуализации.
Модуль визуализации протестирован на задаче отображения результатов опроса Интернет-пользователей по тематическому картированию текста. Структура текста предстаёт в виде кругового графа, вершинами которого являются слова, расположенные в соответствии со своими порядковыми номерами в тексте. Рёбра графа фиксируют силу семантической связи между словами, проявляющуюся в количестве совместных вхождений слов в микротемы в реакциях информантов. Модулярность графа позволяет выявить в нём устойчивые микротемы, характерные для реакций каждой группы испытуемых.
Ключевые слова: научная визуализация, информационная система, графосемантическое моделирование, Web-приложение.
1. Введение
В процессе разработки информационных систем (ИС) часто возникает необходимость реализации в их составе средств визуализации (а иногда и визуальной аналитики). Причём, чем сложнее организация данных внутри создаваемых систем, тем выше потребности в визуализации, но и тем сложнее создать соответствующий графический инструментарий. Для максимально полного покрытия задач отображения данных зачастую не хватает функциональности готовых библиотек рендеринга и требуется либо серьёзно модифицировать их, либо даже разрабатывать собственные программные средства с нуля. В обоих случаях трудоёмкость требуемых доработок оказывается достаточно высокой, особенно если структуры данных, подлежащих наглядному изображению, нетривиальны.
Возможным вариантом экономии трудовых затрат является использование адаптивных систем научной визуализации [1] – специализированного программного обеспечения (ПО), взаимодействующего с разрабатываемой ИС по какому-либо стандартизированному протоколу (TCP/IP стек, общая база данных, текстовые файлы, в которые производится экспорт подлежащих визуализации данных и т. п.). Такой подход оказывается очень удобным в контексте работы с узкоспециализированными решателеями (англ. Solvers) и хранилищами данных, то есть со средствами, играющими роль исключительно источников данных.
Однако при построении сложных ИС, обладающих собственным многофункциональным интерфейсом обработки данных, использование сторонних приложений рендеринга оказывается недостаточно эргономичным: пользователю ИС в этом случае приходится прерывать работу с ней всякий раз, когда ему необходима визуализация. В лучшем случае прерывание состоит в простом переходе к другому приложению на уровне смены активного окна, а в худшем – в совершении каких-то подготовительных действий, например, экспорта данных.
С точки зрения эргономики значительно лучше оказывается включить визуализатор в состав самой ИС так, чтобы пользователь имел возможность совершать все интересующие его действия как по обработке, так и по отображению данных в рамках единого интерфейса.
Для обеспечения такой возможности авторами было принято решение доработать предложенную ранее концепцию построения адаптивных мультиплатформенных систем научной визуализации [1] с учётом поддержки встраивания этих систем как отдельных модулей в состав другого ПО.
В результате предыдущих исследований была создана адаптивная система научной визуализации SciVi [2], основанная на принципах онтологического инжиниринга [3, 4]. Её поведение гибко конфигурируется посредством пополнения и/или изменения онтологической базы знаний о языках программирования совместимых с ней решателей, поддерживаемых семантических фильтрах предобработки входных данных, визуальных объектах и типах графических сцен. Благодаря этому данная система может быть быстро настроена на решение задач визуализации из любой предметной области и на взаимодействие с широким спектром различных источников данных.
Параллельно с разработкой системы SciVi развивалась ИС Семограф [5]. Эта ИС предназначена для решения широкого спектра научных, образовательных и прикладных задач, связанных с обработкой и анализом языковых и текстовых данных. Типовыми задачами, решаемыми с помощью инструментария системы, являются: создание классификаторов и тезаурусов предметных областей, проведение психолингвистических, социолингвистических и пр. экспериментов (а также анализ полученных данных), создание и разметка выборок и корпусов текстов, построение информационных моделей предметных областей, и другие задачи, возникающие в ходе анализа текстового контента [6, 7].
Информационная система реализована как Web-приложение и в настоящее время состоит из модулей, обеспечивающих следующую функциональность:
1. Поиск (с помощью поискового робота и парсера, созданного на основе фреймворка Scrapy [8] на языке Python).
2. Импорт данных (с помощью поискового сервера на основе Apache Solr [9]; кроме того поддерживается импорт файлов формата CSV).
3. Экспорт результатов во внешние приложения, в частности, R [10] (статистическую среду анализа данных), Gephi [11] (средство построения и анализа графов), а также в табличные форматы.
4. Администрирование и организационная деятельность (добавление приглашённых пользователей системы к проектам, управление правами доступа, создание открытых проектов, коммуникация).
5. Исследование (набор инструментов проведения экспериментов, анализа языкового контента, разметки корпусов, классификационной деятельности и др.).
ИС Семограф имеет API, который может использоваться для работы с внешними приложениями или для разработки приложений на основе этой ИС с расширенной в каком-либо аспекте функциональностью.
Целью данной работы является интеграция систем SciVi и Семограф для создания отдельного модуля научной визуализации внутри ИС Семограф. Внедрение инструментария, позволяющего пользователям работать с языковыми и текстовыми данными, обогащёнными наглядной визуализацией, позволит реализовать возможность осуществления полного цикла исследования: от постановки проблемы до генерации отчёта по научному, образовательному или прикладному проекту.
2. Встраиваемая версия системы SciVi
Система научной визуализации SciVi состоит из серверной и клиентской частей. Сервер служит в первую очередь для связи с источником данных и их тяжеловесной предобработки (если таковая требуется при решении конкретной задачи визуализации). Клиент отвечает за связь с пользователем, предоставляя в первую очередь графический интерфейс системы визуализации. На данный момент активно развиваются толстый и тонкий (браузерный) клиенты. Рендеринг данных адаптивно распределяется между клиентом и сервером с учётом производительности клиентской машины, загруженности сервера и скорости сетевого соединения.
Для включения системы SciVi в виде отдельного компонента в состав стороннего по отношению к ней ПО требуется возможность объединения в рамках этого компонента необходимой функциональности сервера и клиента. Это позволит избавиться от внешних зависимостей и минимизировать накладные расходы на пересылку данных внутри итоговой ИС.
Сервер и клиент SciVi имеют модульную архитектуру. Их функциональные блоки полностью изолированы друг от друга и взаимодействуют между собой посредством вызова интерфейсных методов, использования функций обратного вызова (англ. Callback) и передачи декларативных описаний (онтологических профилей [12]) обрабатываемых сущностей. Благодаря этому сборка на основе системы SciVi встраиваемых компонентов визуализации оказывается возможной и не требует глубинных изменений реализованной и отлаженной ранее базовой функциональности, такой, например, как механизмы взаимодействия с источником данных, рендеринг графических сцен и т. п.
На рис. 1 представлена принципиальная схема внутреннего конвейера системы SciVi. Цветом выделены элементы и связи, перенесённые из системы во встраиваемый модуль визуализации.
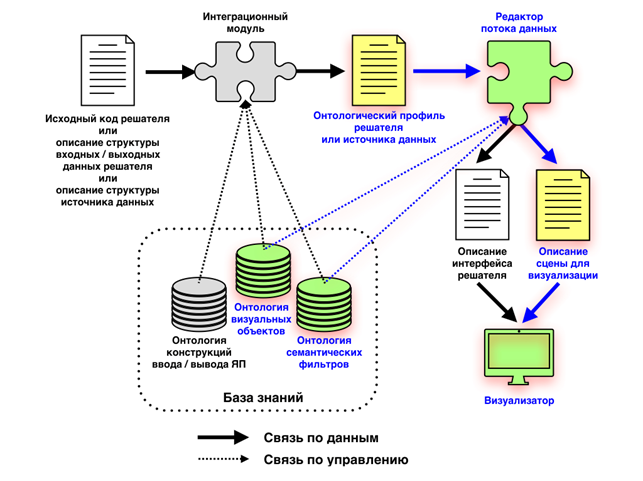
Рис. 1. Внутренний конвейер системы визуализации SciVi (цветом промаркированы элементы, вошедшие во встраиваемую версию)
Как можно видеть по рис. 1, во встраиваемую версию SciVi не вошли интеграционный модуль, отвечающий за настройку на специфику решателя, и онтология синтаксических конструкций ввода-вывода языков программирования, на которой основана работа интеграционного модуля. Эти элементы используются для адаптации системы визуализации к сторонним источникам данных и потому оказываются ненужными при включении SciVi в состав некоторой ИС, где работа происходит с одним фиксированным источником.
Онтологический профиль решателя (источника данных), который в обычном режиме работы SciVi генерируется интеграционным модулем, в данном случае создаётся однократно в процессе встраивания в целевую ИС и описывает точки взаимодействия с ней.
Редактор потока данных, отвечающий за построение цепочки семантической фильтрации и визуализации входных данных, вместе с управляющими его поведением онтологиями семантических фильтров и визуальных объектов, входит во встраиваемую версию SciVi с целью сохранения гибкости её настройки в рамках задач, решаемых целевой ИС. У пользователя сохраняется возможность определять алгоритм предобработки подлежащих визуализации данных, а также в широких пределах варьировать способы визуализации (в рамках визуальных объектов, знания о которых представлены соответствующей онтологией).
По результатам сделанных пользователем настроек редактор потока данных генерирует описание графической сцены. Построение финального изображения и демонстрация его пользователю производится визуализатором.
На данном этапе разработки во встраиваемую версию SciVi не вошли функции, связанные с организацией обратной связи с решателем (вследствие этого в конвейере встраиваемой версии отсутствует описание интерфейса решателя). Предполагается, что целевая ИС сама будет создавать вокруг окна визуализации все необходимые управляющие элементы, влияющие на её работу. Однако в будущем, при необходимости, этот механизм обратной связи может быть поддержан.
3. Концепция интеграции с системой Семограф
ИС Семограф реализована с использованием современных практик разработки Web-приложений. В основе лежит принцип SPA (англ. Single Page Application – одностраничное приложение), что означает отсутствие лишних переходов между страницами, характерных для большинства обычных сайтов. Вместо этого приложение подгружает необходимые данные по мере надобности с помощью AJAX (англ. Asynchronous Javascript and XML). Благодаря этому достигается высокая отзывчивость пользовательского интерфейса при минимальном использовании сетевого трафика.
В качестве ключевых решений для организации клиентской части используются библиотеки React [13] и Redux [14], для серверной – фреймворк Flask [15] и СУБД PostgreSQL [16]. Клиентская часть использует стандарт ECMAScript 6 [17] и при сборке преобразуется в ECMAScript 5 [18] с помощью пакета Babel [19]. Для сборки клиентской части используется Webpack [20]. Такой подход повышает скорость разработки, но накладывает ряд ограничений на используемые библиотеки, например, они должны поддерживать экспорт методов в формате CommonJS [21] или совместимом с ним. Укрупнённая схема взаимодействия модулей и компонентов ИС Семограф приведена на рис. 2. Данная схема включает как сторону клиента, так и сервера.
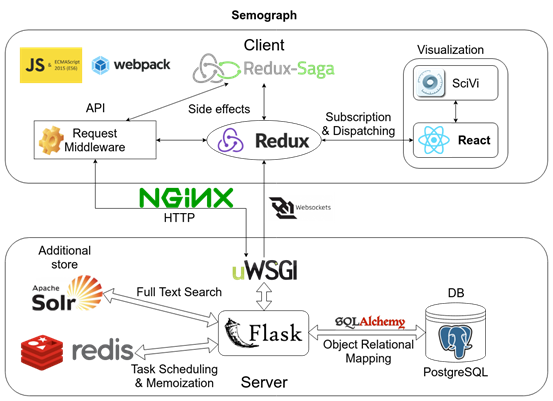
Рис. 2. Схема взаимодействия модулей и компонентов ИС Семограф
Для интеграции системы SciVi с ИС Семограф предполагается разработка компонента (в терминологии React), адаптирующего программный интерфейс тонкого клиента SciVi к стандартам приложений, разработанных с использованием React и Redux. При таком подходе данные будут следовать стандартному циклу ИС Семограф – загружаться по требованию с сервера через API системы Семограф, помещаться в состояние Redux, при необходимости обрабатываться и передаваться в новый компонент. Большим преимуществом в данном случае является отсутствие необходимости модифицировать сервер или его API, а также возможность использовать существующую систему контроля прав доступа.
Жизненный цикл компонента-адаптера должен включать конструирование, передачу данных и управление модулем визуализации на основе тонкого клиента SciVi. Также данный компонент должен обеспечить передачу управляющих команд от модуля визуализации в основное приложение посредством механизма функций обратного вызова. Таким образом, компонент должен реализовать как функции представления, так и контроллера (согласно паттерну проектирования, Model-View-Controller).
Полученный компонент может быть обособлен от ИС Семограф, унифицирован и собран в виде отдельного модуля, что позволит применять его в других приложениях, базирующихся на React и Redux.
4. Пополнение набора средств визуализации системы SciVi
Многие аналитические задачи, решаемые в ИС Семограф, предполагают работу с данными о связности различных сущностей. Такие данные нагляднее всего представимы в виде графов [22, 23].
Для обработки и отображения графов в систему SciVi были добавлены новые семантические фильтры (позволяющие по различным правилам вычислять положения вершин и характеристики рёбер графа) и визуальные объекты (позволяющие отображать именованные вершины и связи между ними). Добавление осуществлено путём пополнения соответствующих онтологий, входящих в базу знаний системы, а также путём подключения дополнительной библиотеки визуализации.
Каждая вершина визуализируемого графа характеризуется названием, идентификатором кластера, в который входит связанная с вершиной сущность, весом и номером. Кластеризация сущностей, отображаемых в виде графа, происходит на стороне ИС Семограф; на данный момент эта функциональность находится в стадии разработки.
Названия вершин отображаются в виде текстовых меток, повёрнутых под определённым углом, который для каждой вершины определяется вычисляющим её положение фильтром.
Принадлежность вершины к конкретному кластеру отображается цветом: каждому кластеру назначается свой определённый цвет из заданной по умолчанию таблицы; далее у пользователя есть возможность изменять эти цвета. Вершины располагаются радиально в порядке, определяемом их номерами.
Веса вершин отображаются в виде гистограммы, каждый столбец которой рисуется под текстовой меткой соответствующей вершины.
Каждое ребро графа характеризуется весом и отображается в виде квадратичной кривой Безье, толщина которой пропорциональна его весу. Цвет ребра определяется цветами соединяемых им вершин (если вершины имеют разные цвета, ребро окрашивается градиентом).
В дальнейшем набор атрибутов вершин и рёбер может быть расширен.
Визуализатор графов поддерживает выделение вершины (с автоматическим подсвечиванием более ярким цветом всех инцидентных ей рёбер и всех смежных с ней вершин) и отображение в специальной информационной панели связанной с вершинами информации.
Настройка конкретного способа визуализации осуществляется пользователем путём редактирования диаграммы потока данных средствами высокоуровневого графического Web-интерфейса [2]. Эта диаграмма определяет последовательность шагов предобработки данных (семантической фильтрации), а также связь данных с теми или иными атрибутами поддерживаемых системой визуализации графических объектов. Набор доступных для построения диаграммы вершин, олицетворяющих семантические фильтры, графические объекты и типы сцен, описан в соответствующих онтологиях системы.
На рис. 3 представлен пример диаграммы потока данных, задающей настройку визуализации графа с радиальным расположением вершин.
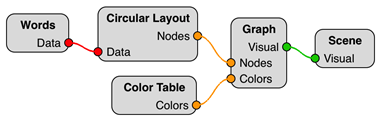
Рис. 3. Диаграмма потока данных, определяющая настройки визуализации графа понятий в системе научной визуализации SciVi
Результат визуализации графа, состоящего из 224 вершин и 26612 рёбер, показан на рис. 4. Входные данные представляют собой результаты опроса Интернет-пользователей по тематическому картированию текста. Информантам предъявляется текст и ставится задача определить его тему, выделить микротемы и к каждой микротеме отнести слова, представляющие её в тексте. Выполнение опроса проводится в ИС Семограф; одним из результатов исследования становится генерация семантической карты текста, представляющей собой матрицу n × n, где n – число слов в тексте. В ячейках отображаются значения совместной встречаемости двух слов во всех выделенных микротемах. Особенностью матрицы является фиксированный порядок столбцов и строк, отражающий порядок слов в анализируемом тексте.
Рис. 4. Визуализация графа понятий, построенного в системе научной визуализации SciVi по данным, извлечённым из ИС Семограф
Приведённая иллюстрация выполнена с использованием облегчённой версии программного модуля, используемого в ИС Семограф. С целью включения в текст статьи вся лишняя функциональность данного модуля была удалена, оставлены лишь непосредственно рендеринг и базовая интерактивность (при наведении курсора на вершину подсвечиваются все вершины, связанные с ней, а также все соответствующие рёбра; при клике выделение фиксируется). Подлежащие визуализации данные в целях демонстрации выгружены из ИС Семограф и сохранены в JSON-представлении в отдельный файл, подключаемый к отображающей граф Web-странице.
На текущий момент это единственный реализованный способ визуализации графов, однако в дальнейшем функциональность SciVi по отображению связанных и иерархических сущностей будет расширяться.
В результате экспериментов с визуализацией было выяснено, что приемлемой производительности (отклика быстрее, чем за 125 мс [24]) на желаемых объёмах данных удаётся достичь только используя аппаратное ускорение рендеринга. Так, например, использование для визуализации графа стандарта SVG (посредством библиотеки D3.js [25]) в браузерах Mozilla Firefox (версия 51) и Google Chrome (версия 56) на компьютере с процессором Intel Core i7 (4 ядра тактовой частотой 2 ГГц, без поддержки гипертрединга), объёмом оперативной памяти 8 Гб и видеокартой Intel Iris Pro с объёмом видеопамяти 1536 Мб перерисовка графа при перемещении курсора над текстовыми метками длится в среднем 1500 мс.
В связи с этим для рендеринга графа было решено использовать библиотеку PixiJS [26], предоставляющую удобную в использовании обёртку над низкоуровневым графическим API WebGL. Однако использование данной библиотеки напрямую не привело к приемлемому результату.
Во-первых, из-за принятой в PixiJS по умолчанию политики непрерывной перерисовки сцены (англ. Continuous Rendering) имела место максимальная загрузка центрального и графического процессоров во время всего периода работы с Web-страницей (даже в условиях пассивного рассматривания пользователем результатов рендеринга). Это, в свою очередь, влекло за собой нерациональное использование ресурсов вычислительной системы (включая высокое энергопотребление, что актуально при работе от автономных источников питания, например, на ноутбуках).
Во-вторых, было обнаружено, что, хотя производительность PixiJS достаточно высока по сравнению с SVG, перерисовка кадра длится в среднем 800 мс, а начальная загрузка страницы – 11 000 мс. В результате анализа было установлено, что основным фактором, замедляющим перерисовку, является системный антиалиасинг множественной выборки (англ. Multisampling Antialiasing, MSAA), принятый в PixiJS как основное (и единственное) средство обеспечения сглаживания границ объектов на итоговом изображении. Медленная скорость загрузки страницы, в свою очередь, обусловлена тем, что для каждого объекта в PixiJS по умолчанию создаётся отдельный набор из вершинного буфера (англ. Vertex Buffer Object, VBO), индексного буфера (англ. Index Buffer Object, IBO) и буфера состояния (англ. Vertex Array Object, VAO). Совокупное число различных буферов, одновременно используемых на сцене, превышало 80 000. Аллокация этих буферов в WebGL достаточно затратна по времени.
В-третьих, в PixiJS отсутствуют встроенные средства отображения кривых, закрашенных градиентом от одного цвета к другому (что актуально в данной задаче, так как цвета вершин маркируют кластеры, к которым они принадлежат, а цвета рёбер для наглядности определяются цветами соответствующих вершин).
Тем не менее, PixiJS открывает широкие возможности использования аппаратного ускорения графики и, являясь библиотекой с открытым исходным кодом, допускает гибкое расширение и адаптацию под конкретные задачи.
Для решения возникших проблем был принят следующий комплекс мер (следует отметить, что кодовая база самой библиотеки PixiJS изменениям не подвергалась, желаемых результатов удалось добиться путём расширения библиотеки исключительно на уровне наследования её базовых классов и переопределения виртуальных методов).
1. Политика перерисовки сцены изменена на обновление по требованию (англ. On-Demand Rendering). Это позволило полностью разгрузить и графический, и центральный процессоры на периоды «бездействия» Web-страницы.
2. Системный MSAA отключен, а для обеспечения высокого визуального качества реализован локальный антиалиасинг кривых, основанный на разделении кривой в процессе триангуляции на «тело» и «край» [27] (см. рис. 5 (а)). Для примера на рис. 5 (а) показаны три сегмента аппроксимации кривой. «Тело», представленное вершинами внутреннего контура (v2, v6, v10, v14, v15, v11, v7, v3), рисуется базовым цветом путём выставления этим вершинам нужных значений {r, g, b, a} в качестве атрибутов. «Край» (представленный вершинами v1, v5, v9, v13, v14, v10, v6, v2 и v3, v7, v11, v15, v16, v12, v8, v4), в свою очередь, рисуется с нарастающей к внешней границе прозрачностью, что обеспечивается выставлением в атрибуты вершин внешнего контура (представленного вершинами v1, v5, v9, v13, v16, v12, v8, v4) значения а = 0. Увеличенный фрагмент результата визуализации кривых представлен на рис. 5 (б). Такой подход к сглаживанию границ позволил уменьшить время перерисовки кадра до 60–120 мс (прирост производительности примерно на порядок по сравнению с MSAA).
3. Реализована линейная интерполяция базового цвета вдоль кривой путём вычисления и установки нужного цвета для каждого поперечного сечения кривой. Это позволило поддержать цветовые переходы на рёбрах, соединяющих вершины разных кластеров.
4. Осуществлено объединение рёбер в «пакеты» так, чтобы в каждом пакете суммарно было не более 65536 вершин. Каждый пакет представлен своим набором из вершинного буфера, индексного буфера и буфера состояния. Максимальное число вершин выбрано исходя из того, что минимально возможная на сегодняшний день разрядность индексного регистра графического процессора составляет 16 бит (то есть гарантируется, что за один вызов отрисовки на графическом процессоре может быть адресовано не меньше 216 вершин). Объединение рёбер привело к десятикратному уменьшению числа требуемых для построения сцены буферов, что, в свою очередь, сократило время загрузки страницы до 2500 мс (прирост производительности более чем в 4 раза по сравнению с изначальным вариантом).
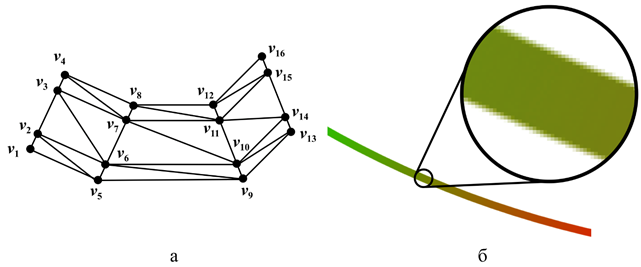
Рис. 5. Фрагмент триангуляции кривой (а) и фрагмент результата визуализации (б) кривой в системе SciVi
Благодаря вышеописанным программным решениям удалось удовлетворить требованиям, предъявляемым к производительности модуля визуализации.
Стек программных средств, используемых во встраиваемой Web-версии SciVi, представлен на рис. 6.
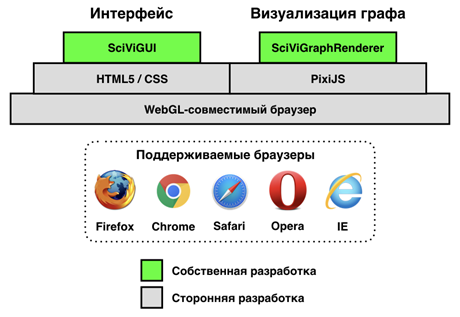
Рис. 6. Стек программных средств, использованных во встраиваемой в ИС Семограф версии SciVi
В настоящее время при визуализации графов основой для рендеринга выступает движок PixiJS, однако для решения других задач (например, при построении диаграмм и графиков, отображении каких-либо данных в привязке к географической карте, или при визуализации трёхмерных структур) могут быть выбраны и подключены иные программные средства. Основой графического интерфейса пользователя служат средства HTML5 и CSS. Полученное программное решение протестировано в среде браузеров Firefox, Chrome, Safari, Opera и Internet Explorer.
5. Заключение
В результате проделанной работы сформулирована концепция встраивания системы научной визуализации SciVi в сторонние по отношению к ней приложения. Концепция воплощена на практике на примере создания на базе SciVi подсистемы визуализации для ИС Семограф. Из тонкого клиента системы SciVi выделен автономный модуль, готовый к встраиванию в сторонние Web-приложения.
С целью решения актуальных для ИС Семограф задач визуализации, в систему SciVi добавлены новые средства отображения графов. В целях обеспечения высокой эффективности рендеринга, для такого отображения использованы механизмы аппаратного ускорения графики, основанные на API WebGL.
Работоспособность подсистемы визуализации успешно протестирована на реальных данных, извлечённых из ИС Семограф.
Полученный модуль визуализации может быть использован как автономное программное средство, но при этом остаётся составной частью системы SciVi. Это позволяет развивать его функциональность одновременно с развитием системы SciVi, тестировать новые средства визуализации, используя адаптационные механизмы этой системы, пополнять репозиторий доступных визуальных объектов, типов графических сцен и семантических фильтров путём расширения онтологий, составляющих базу знаний SciVi.
По мере необходимости созданный модуль визуализации будет пополняться новыми графическими возможностями. В частности, приоритетным является реализация средств отображения геоинформационных данных с поддержкой временных срезов.
6. Благодарности
Работа выполнена в рамках государственного задания Минобрнауки России (проект 34.1505.2017/4.6).
Список литературы
1. Ryabinin K., Chuprina S. Development of Ontology-Based Multiplatform Adaptive Scientific Visualization System. Journal of Computational Science. Elsevier, 2015. Vol. 10. P. 370–381.
2. Рябинин К.В., Чуприна С.И., Бортников А.Ю. Автоматизация настройки систем научной визуализации на специфику разнообразных источников данных. Научная визуализация. Национальный исследовательский ядерный университет МИФИ, 2016. К. 4, Т. 8, №4. С. 1–14.
3. Chuprina S., Nasraoui O. Using Ontology-based Adaptable Scientific Visualization and Cognitive Graphics Tools to Transform Traditional Information Systems into Intelligent Systems. Scientific Visualization. National Research Nuclear University "MEPhI", 2016. Q. 1, V. 8, No. 1. P. 23–44.
4. Чуприна С.И., Зиненко Д.В. ОНТОЛИС: адаптируемый визуальный редактор онтологий. Вестник Пермского университета. 2013. №3 (22). С. 106–110.
5. Баранов Д.А., Белоусов К.И., Влацкая И.В., Зелянская Н.Л. Система графосемантического моделирования [программа для ЭВМ] Свидетельство о государственной регистрации в Федеральной службе по интеллектуальной собственности, патентам и товарным знакам. Зарегистрировано в Реестре программ для ЭВМ № 20111617192 от 15.09.2011.
6. Belousov K. I., Baranov D. A., Zelyanskaya N. L., Karlina T. V. The Use of Economic Classifiers for the Indexing of Scientific Publications. Scientific and Technical Information Processing, 2015. Vol. 42, No. 4. P. 299–305.
7. Belousov K., Erofeeva E., Leshchenko Y., Baranov D. “Semograph” Information System as a Framework for Network-Based Science and Education. Smart Innovation, Systems and Technologies. Smart Education and e-Learning, 2017. P. 263–272.
8. Фреймворк сбора данных Scrapy [Электронный ресурс]. URL: https://scrapy.org/ (дата обращения: 19.10.2017).
9. Платформа полнотекстового поиска Apache Solr [Электронный ресурс]. URL: http://lucene.apache.org/solr/ (дата обращения: 19.10.2017).
10. Пакет математической статистики R [Электронный ресурс]. URL: https://www.r-project.org/ (дата обращения: 19.10.2017).
11. Визуализатор графов Gephi [Электронный ресурс]. URL: https://gephi.org/ (дата обращения: 19.10.2017).
12. Ryabinin K., Chuprina S. High-Level Toolset For Comprehensive Visual Data Analysis and Model Validation. Procedia Computer Science. Elsevier, 2017. Vol. 108. P. 2090–2099.
13. Фреймворк построения графических интерфейсов пользователя React [Электронный ресурс]. URL: https://reactjs.org/ (дата обращения: 19.10.2017).
14. Фреймворк управления состоянием Redux [Электронный ресурс]. URL: http://redux.js.org/ (дата обращения: 19.10.2017).
15. Фреймворк для создания веб-приложений Flask [Электронный ресурс]. URL: http://flask.pocoo.org/ (дата обращения: 19.10.2017).
16. СУБД PostgreSQL [Электронный ресурс]. URL: https://www.postgresql.org/ (дата обращения: 19.10.2017).
17. Стандарт ECMAScript 6 [Электронный ресурс]. URL: http://www.ecma-international.org/ecma-262/6.0/ECMA-262.pdf (дата обращения: 19.10.2017).
18. Стандарт ECMAScript 5 [Электронный ресурс]. URL: http://www.ecma-international.org/ecma-262/5.1/Ecma-262.pdf (дата обращения: 19.10.2017).
19. Компилятор Babel [Электронный ресурс]. URL: https://babeljs.io/ (дата обращения: 19.10.2017).
20. Система сборки модулей Webpack [Электронный ресурс]. URL: https://webpack.github.io/ (дата обращения: 19.10.2017).
21. Cистема модулей CommonJS [Электронный ресурс]. URL: http://requirejs.org/docs/commonjs.html (дата обращения: 19.10.2017).
22. Касьянов В.Н., Золотухин Т.А. Visual Graph – система для визуализации сложно структурированной информации большого объема на основе графовых моделей. Научная визуализация. Национальный исследовательский ядерный университет МИФИ, 2015. К. 4, Т. 7, №4. С. 44–59.
23. Касьянов В., Касьянова Е. Визуализация информации на основе графовых моделей. Научная визуализация. Национальный исследовательский ядерный университет МИФИ, 2014. К. 1, Т. 6, №1. С. 31–50.
24. Keval H., Sasse M.A. To catch a thief – you need at least 8 frames per second: the impact of frame rates on user performance in a CCTV detection task. Proceedings of the 16th ACM international conference on Multimedia. ACM, 2008. P. 941–944.
25. Библиотека визуализации D3.js [Электронный ресурс]. URL: https://d3js.org/ (дата обращения: 19.10.2017).
26. Графический движок PixiJS [Электронный ресурс]. URL: http://www.pixijs.com/ (дата обращения: 19.10.2017).
27. DesLauriers M. Drawing Lines is Hard [Электронный ресурс]. URL: https://mattdesl.svbtle.com/drawing-lines-is-hard (дата обращения: 19.10.2017).
INTEGRATION OF SEMOGRAPH INFORMATION SYSTEM AND SCIVI VISUALIZER FOR SOLVING THE TASKS OF LINGUAL CONTENT EXPERT ANALYSIS
K.V. Ryabinin, D.A. Baranov, K.I. Belousov
Perm State University, Perm, Russian Federation
kostya.ryabinin@gmail.com, baranov@semograph.com, belousovki@gmail.com
Abstract
This paper is devoted to the further development of scientific visualization system SciVi. The authors created this system during the earlier research as an extensible toolset for visual analysis of arbitrary scientific data. SciVi is based on ontology engineering methods and means: its behavior is controlled by knowledge base consisting of visual objects’ ontology, data filters’ ontology and ontology of input/output statements of programming languages the external data generators (solvers) are written in. This knowledge-driven approach enables to connect SciVi to arbitrary data sources (including software/hardware solvers) and to fine-tune it for purposes of particular visualization tasks from any application domain. The user is provided with the high-level graphical interface to set up the visualization system according his/her needs. Extending SciVi with new visualization tools or data filtering mechanisms is as easy as the extending of corresponding ontologies in its knowledge base; the source code of the system’s core remains untouched.
SciVi is organized as client-server software. The server is responsible to collect the data from data source and to preprocess them if needed (the preprocessing stage may include partial rendering in case the client has insufficient performance to render the entire scene). The client provides graphical user interface and displays the final rendering result to the user.
Initially SciVi was developed as a stand-alone application with modular architecture. However sometimes it is useful to be able to incorporate individual visualization modules into third-party applications.
The reported work covers the extraction of customizable visualization module from SciVi and integration of this module with Semograph graphosematic modeling system. While the extracted rendering module is treated as an independent software library, it still remains to be a part of SciVi and therefore is driven by ontology knowledge base, which contains knowledge about graphical objects, scenes’ types and semantic filters available. This module can be easily extended and set up for arbitrary visualization tasks.
The rendering module was tested on the task of thematic text mapping visualization. The mapping has been done by informants during the interview via Internet. The mapped text is displayed as circular graph. Nodes of this graph are words ordered according to their appearance in the original text. Edges represent the semantic connections between words manifested in the number of joint words occurrences in micro-topics in the informants’ reactions. Modularity of this graph makes it possible to identify the stable micro-topics, which are typical for the certain groups of informants.
Keywords: scientific visualization, information system, graphosemantic modeling, Web-application.
References
1. Ryabinin K., Chuprina S. Development of Ontology-Based Multiplatform Adaptive Scientific Visualization System. Journal of Computational Science. Elsevier, 2015. Vol. 10. P. 370–381.
2. Ryabinin K.V., Chuprina S.I., Bortnikov A.Yu. Automated Tuning of Scientific Visualization Systems to Varying Data Sources. Scientific Visualization. National Research Nuclear University "MEPhI", 2016. Q. 4, Vol. 8, No. 4. P. 1–14.
3. Chuprina S., Nasraoui O. Using Ontology-based Adaptable Scientific Visualization and Cognitive Graphics Tools to Transform Traditional Information Systems into Intelligent Systems. Scientific Visualization. National Research Nuclear University "MEPhI", 2016. Q. 1, V. 8, No. 1. P. 23–44.
4. Chuprina S.I., Zinenko D.V. Adaptable Visual Ontological Editor ONTOLIS. Vestnik Permskogo Universiteta. 2013. No. 3 (22). P. 106–110.
5. Baranov D.A., Belousov K.I., Vlatskaya I.V., Zelyanskaya N.L. Graphosemantic Modeling System [Computer program]. Certificate of state registration in the Federal Service for Intellectual Property, Patents and Trademarks. Registered in the Register of Computer Programs No. 20111617192 of 15.09.2011.
6. Belousov K.I., Baranov D.A., Zelyanskaya N.L., Karlina T.V. The Use of Economic Classifiers for the Indexing of Scientific Publications. Scientific and Technical Information Processing, 2015. Vol. 42, No. 4. P. 299–305.
7. Belousov K., Erofeeva E., Leshchenko Y., Baranov D. “Semograph” Information System as a Framework for Network-Based Science and Education. Smart Innovation, Systems and Technologies. Smart Education and e-Learning, 2017. P. 263–272.
8. Scrapy Scraping and Web Crawling Framework [Electronic resource]. URL: https://scrapy.org/ (last visited: 19.10.2017).
9. Apache Solr Search Platform [Electronic resource]. URL: http://lucene.apache.org/solr/ (last visited: 19.10.2017).
10. R Software Environment for Statistical Computing and Graphics [Electronic resource]. URL: https://www.r-project.org/ (last visited: 19.10.2017).
11. Gephi Graph Visualizer [Electronic resource]. URL: https://gephi.org/ (last visited: 19.10.2017).
12. Ryabinin K., Chuprina S. High-Level Toolset For Comprehensive Visual Data Analysis and Model Validation. Procedia Computer Science. Elsevier, 2017. Vol. 108. P. 2090–2099.
13. React Graphical User Interface Framework [Electronic resource]. URL: https://reactjs.org/ (last visited: 19.10.2017).
14. Redux State Managing Framework [Electronic resource]. URL: http://redux.js.org/ (last visited: 19.10.2017).
15. Web Framework Flask [Electronic resource]. URL: http://flask.pocoo.org/ (last visited: 19.10.2017).
16. PostgreSQL Database Management System [Electronic resource]. URL: https://www.postgresql.org/ (last visited: 19.10.2017).
17. ECMAScript 6 Standard [Electronic resource]. URL: http://www.ecma-international.org/ecma-262/6.0/ECMA-262.pdf (last visited: 19.10.2017).
18. ECMAScript 5 Standard [Electronic resource]. URL: http://www.ecma-international.org/ecma-262/5.1/Ecma-262.pdf (last visited: 19.10.2017).
19. Babel Compiler [Electronic resource]. URL: https://babeljs.io/ (last visited: 19.10.2017).
20. Webpack Module Bundler [Electronic resource]. URL: https://webpack.github.io/ (last visited: 19.10.2017).
21. CommonJS Module System [Electronic resource]. URL: http://requirejs.org/docs/commonjs.html (last visited: 19.10.2017).
22. Kasyanov V.N., Zolotuhin T.A. Visual Graph – A System for Visualization of Big Size Complex Structural Information on The Base of Graph Models. Scientific Visualization. National Research Nuclear University "MEPhI", 2015. Q. 4, Vol. 7, No. 4. P. 44–59.
23. Kasyanov V., Kasyanova E. Information Visualization on the Base of Graph Models. Scientific Visualization. National Research Nuclear University "MEPhI", 2014. Q. 1, Vol. 6, No. 1. P. 31–50.
24. Keval H., Sasse M.A. To catch a thief – you need at least 8 frames per second: the impact of frame rates on user performance in a CCTV detection task. Proceedings of the 16th ACM international conference on Multimedia. ACM, 2008. P. 941–944.
25. D3.js Visualization Library [Electronic resource]. URL: https://d3js.org/ (last visited: 19.10.2017).
26. PixiJS Rendering Engine [Electronic resource]. URL: http://www.pixijs.com/ (last visited: 19.10.2017).
27. DesLauriers M. Drawing Lines is Hard [Electronic resource]. URL: https://mattdesl.svbtle.com/drawing-lines-is-hard (last visited: 19.10.2017).