АВТОМАТИЗАЦИЯ НАСТРОЙКИ СИСТЕМ НАУЧНОЙ ВИЗУАЛИЗАЦИИ НА СПЕЦИФИКУ РАЗНООБРАЗНЫХ ИСТОЧНИКОВ ДАННЫХ
К.В. Рябинин, С.И. Чуприна, А.Ю. Бортников
Пермский государственный национальный исследовательский университет, Пермь, Россия
kostya.ryabinin@gmail.com, chuprinas@inbox.ru, a.yu.bortnikov@yandex.ru
Содержание
2. Общая характеристика системы SciVi
3. Механизм адаптации системы SciVi к сторонним источникам данных
4. Подсистема семантических фильтров
Аннотация
Данная статья посвящена новому способу настройки систем научной визуализации на специфику решаемых задач. Авторами предлагается модельно-ориентированный подход к разработке систем научной визуализации, основанный на методах и средствах онтологического инжиниринга. Такой подход позволяет нивелировать такие недостатки многих распространенных систем научной визуализации, как отсутствие высокоуровневой адаптации к сторонним источникам данных (таким как программные и программно-аппаратные решатели, хранилища данных и т. п.) и невозможность работы одновременно на различных платформах.
Рассматриваемый подход предполагает реализацию систем научной визуализации на основе технологий управления знаниями об отображаемых ими графических объектах, о специфике источников данных и о программно-аппаратных особенностях вычислительной среды. Такие знания хранятся в виде онтологий, представляющих собой формальные модели предметных областей, включающие множество понятий этих предметных областей с их определениями, множество связей между понятиями и множество аксиом, описывающих семантические ограничения и другие правила, вводимые для соответствующих понятий и связей. Управляемость системы научной визуализации знаниями дает ряд преимуществ: расширяемость набора графических объектов и сцен для представления данных, а также возможность высокоуровневой настройки на специфику решаемой задачи и конкретные источники данных без необходимости модификации ранее отлаженного кода. Кроме того, предлагаемая архитектура систем научной визуализации допускает настройку обратной связи с решателями, генерирующими данные для отображения. Обратная связь позволяет пользователям непосредственно при помощи графического интерфейса системы визуализации задавать входные данные для решателей, запускать и останавливать их (если это необходимо). Разработанные программные средства и использованные технологии обеспечивают мультиплатформенность систем научной визуализации с сохранением высокой эффективности рендеринга. Данный подход лежит в основе реализованной авторами универсальной мультиплатформенной клиент-серверной системы научной визуализации SciVi, которая была успешно использована для решения целого ряда практически-значимых научных задач.
В данной статье описываются новые возможности системы SciVi для обеспечения пользователя средствами предварительной обработки подлежащих визуализации данных и реализация тонкого Web-клиента.
Для предварительной обработки данных в рамках SciVi реализована подсистема семантических фильтров. Механизм обработки (фильтрации) данных осуществляется в два этапа: первичная обработка на стороне сервера и окончательная – на стороне клиента. На стороне сервера выполняется фильтрация, целью которой является удовлетворение наиболее общих потребностей пользователя в изменении данных, порождаемых решателем (например, выборка данных только за определённый период). На стороне клиента выполняется фильтрация с целью адаптации данных, полученных с сервера, для учёта индивидуальных потребностей пользователя. Для осуществления настройки системы визуализации на специфику конкретной задачи пользователю предлагается высокоуровневый визуальный интерфейс с использованием диаграмм потока данных.
Тонкий Web-клиент позволяет пользователю воспользоваться функциональностью системы SciVi с любого компьютера или мобильного устройства без установки дополнительного программного обеспечения.
Ключевые слова: научная визуализация, мультиплатформенность, онтологический инжиниринг, мобильные устройства, диаграмма потока данных, тонкий клиент, OpenGL, WebGL.
1. Введение
Общей проблемой большинства современных систем научной визуализации (таких, например, как TecPlot, Avizo, VizIt, ParaView, KiwiViewer и др.) является отсутствие высокоуровневых средств адаптации к специфике сторонних источников данных: программных и программно-аппаратных решателей (от англ. Solver), хранилищ данных и т. п. Как правило, системы визуализации имеют достаточно жёстко регламентированные форматы входных данных, что заставляет пользователей разрабатывать самостоятельно или заказывать промежуточное программное обеспечение для преобразования имеющихся у них данных, подлежащих визуальному анализу, к требуемому визуализаторами представлению. В результате этого затрудняется процесс автоматизированного создания высококачественных изображений, удовлетворяющих индивидуальным потребностям исследователей, что в свою очередь снижает эффективность их научной работы.
Кроме того, среди популярных систем научной визуализации мультиплатформенные решения, позволяющие осуществлять высококачественный рендеринг интересующих пользователя данных и на настольных компьютерах, и на мобильных устройствах. В контексте же работы в полевых условиях (например, в экспедициях) наличие мобильных версий систем визуального анализа научных данных является весьма актуальным.
Для комплексного решения указанных проблем авторами был предложен модельно-ориентированный подход к разработке систем научной визуализации, основанный на методах онтологического инжиниринга [1]. Суть этого подхода заключается в том, что работа системы научной визуализации полностью управляется знаниями об отображаемых графических объектах, о специфике источников данных и о программно-аппаратных особенностях вычислительной среды. Знания хранятся в виде онтологий – формальных моделей предметных областей, включающих в себя множество понятий этих предметных областей с их определениями, множество связей между понятиями и множество аксиом, описывающих семантические ограничения и другие правила, связанные со спецификой интерпретации соответствующих понятий и связей.
Использование принципов управления работой системы визуализации на основе знаний о её визуальных средствах, особенностях источников данных и окружающей вычислительной среды позволяет во многом упростить и автоматизировать следующие ключевые процессы в разработке и использовании системы:
1. Расширять новыми графическими возможностями посредством добавления поддержки отображения новых видов объектов и новых типов графических сцен на уровне графического интерфейса.
2. Осуществлять настройку на специфику решаемой задачи и конкретные источники данных без модификации способа представления данных на стороне источников.
3. Реализовать высокоуровневую обратную связь с источниками данных (например, автоматизированную генерацию графического интерфейса на стороне клиента для управления вычислительным процессом решателя напрямую из системы визуализации, без необходимости модификации исходного кода решателя).
4. Обеспечить мультиплатформенность с сохранением высокой эффективности рендеринга путём адаптации к особенностям конкретной программно-аппаратной платформы.
На базе предложенного подхода авторами была разработана универсальная мультиплатформенная клиент-серверная система научной визуализации SciVi [2], которая успешно использовалась для решения целого ряда задач рендеринга научных данных из различных предметных областей [3].
Архитектура системы SciVi нацелена на высокую эффективность визуализации и расширяемость функциональности. Опыт практического использования системы показал необходимость добавления в систему новых компонентов:
1. Удобной и интуитивно-понятной пользователям подсистемы фильтрации (предварительной обработки) данных.
2. Тонкого Web-клиента для организации работы с системой без необходимости установки на компьютер пользователя дополнительного программного обеспечения.
Описанию этих новых средств, в основном, и посвящена данная работа.
2. Общая характеристика системы SciVi
В основе системы научной визуализации SciVi лежит формальная модель, ранее предложенная авторами [4] и расширенная в рамках данной работы в соответствии с новым требованием обеспечения возможности фильтрации данных, подлежащих визуализации:
![]() ,
,
где ![]() – система научной визуализации,
– система научной визуализации,
![]() – онтология визуальных объектов и типов сцен,
– онтология визуальных объектов и типов сцен,
![]() – онтология семантических фильтров,
– онтология семантических фильтров,
![]() – онтология синтаксических конструкций
ввода/вывода языков программирования,
– онтология синтаксических конструкций
ввода/вывода языков программирования,
![]() – множество поддерживаемых элементов
управления,
– множество поддерживаемых элементов
управления,
![]() – множество поддерживаемых элементов управления
сценой,
– множество поддерживаемых элементов управления
сценой,
![]() – множество поддерживаемых команд пользователя,
– множество поддерживаемых команд пользователя,
![]() – оператор сглаживания границ объектов,
– оператор сглаживания границ объектов,
![]() – оператор визуализации,
– оператор визуализации,
![]() – оператор интерактивного взаимодействия,
– оператор интерактивного взаимодействия,
![]() – оператор порождения конвертеров,
– оператор порождения конвертеров,
![]() – оператор синтаксического анализа,
– оператор синтаксического анализа,
![]() – оператор порождения графического интерфейса
решателя.
– оператор порождения графического интерфейса
решателя.
Система SciVi организована в соответствии с принципами клиент-серверной архитектуры, что позволяет, с одной стороны, осуществлять доступ к источникам данных и решателям (на стороне сервера), а с другой – поддержать широкий спектр платформ, включая мобильные (на стороне клиента).
Сервер предназначен для работы на настольном компьютере под управлением ОС Windows, GNU/Linux или OS X. Он отвечает за взаимодействие с источниками данных (чаще всего – решателями, которые являются сторонними по отношению к системе визуализации) и предобработку данных, получаемых из этих источников, с целью конвертации их к пригодному для визуализации в конкретных условиях виду.
Нативные клиенты системы SciVi реализованы как для настольных компьютеров под управлением Windows, GNU/Linux и OS X, так и для мобильных устройств под управлением iOS и Android. Запущенный на конкретном оборудовании клиент производит измерение своей производительности и сообщает результат измерения серверу. На основании этих данных, руководствуясь набором эвристических правил, сервер автоматически переключает работу системы визуализации в один из трёх режимов:
1. Визуализация полного объёма данных на стороне клиента (наиболее предпочтительный вариант, так как обеспечивает наискорейший отклик системы на команды пользователя и наилучшее качество визуализации, однако требует от клиентской платформы достаточно высокое быстродействие).
2. Частичное упрощение данных сервером и их визуализация на стороне клиента (балансировка нагрузки клиента и сервера, способная обеспечить быстрый отклик системы на команды пользователя, требуя от клиента лишь базовой поддержки аппаратного ускорения графики).
3. Визуализация полного объёма данных на стороне сервера и передача клиенту только готового изображения (принцип, аналогичный технологии VNC, требующий от клиента лишь самых базовых возможностей для показа статичных изображений, однако потенциально имеющий значительную задержку отклика на команды пользователя).
Ключевыми особенностями системы SciVi являются:
1. Средства двумерной и трёхмерной визуализации. В перспективе возможно также добавление средств многомерной визуализации.
2. Расширяемость набора визуальных объектов и типов графических сцен.
3. Автоматизированные средства настройки на специфику решаемой задачи и источника данных (в частности, программно-аппаратного решателя), основанные на методах онтологического инжиниринга.
4. Работоспособность на настольных компьютерах и мобильных устройствах (мультиплатформенность).
5. Средства для обеспечения высокой производительности и, одновременно с этим, высокого качества визуализации.
3. Механизм адаптации системы SciVi к сторонним источникам данных
Ключевой особенностью системы научной визуализации SciVi, отличающей её от аналогов, является наличие высокоуровневого механизма, автоматизирующего процесс адаптации (настройки) системы на специфику решаемой задачи и имеющегося у исследователя источника данных. Устройство этого механизма схематично представлено на рис. 1.
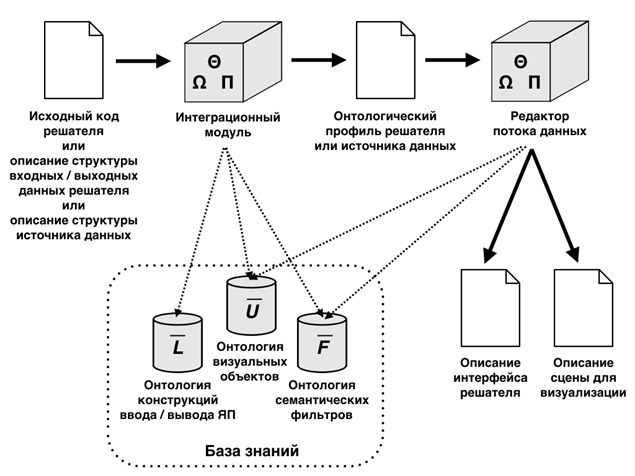
Рис. 1. Схема механизма адаптации системы научной визуализации SciVi к сторонним источникам данных
В основе механизма адаптации лежит пополняемая база знаний,
состоящая из трех онтологий: ![]() ,
, ![]() , и
, и ![]() .
.
Онтология ![]() используется для автоматической генерации
синтаксических анализаторов программного кода, предназначенных для извлечения
структур входных и выходных данных из программ, поданных на анализ. Если
источник данных для системы визуализации представлен программным решателем и у
пользователя есть доступ (на чтение) к его исходному коду, процесс настройки
системы визуализации на формат входных и выходных данных этого решателя
полностью автоматизируется.
используется для автоматической генерации
синтаксических анализаторов программного кода, предназначенных для извлечения
структур входных и выходных данных из программ, поданных на анализ. Если
источник данных для системы визуализации представлен программным решателем и у
пользователя есть доступ (на чтение) к его исходному коду, процесс настройки
системы визуализации на формат входных и выходных данных этого решателя
полностью автоматизируется.
Следует отметить, что для автоматического извлечения
структуры входных и выходных данных решателя в онтологии ![]() достаточно описать только
синтаксис конструкций ввода/вывода, объявления переменных и приведения типов
для языка программирования, на котором написан исходный код решателя. На
сегодняшний день поддерживаются языки C/C++, Fortran-90 и Java, но этот список
легко расширяем, так как трудоёмкость пополнения онтологии
достаточно описать только
синтаксис конструкций ввода/вывода, объявления переменных и приведения типов
для языка программирования, на котором написан исходный код решателя. На
сегодняшний день поддерживаются языки C/C++, Fortran-90 и Java, но этот список
легко расширяем, так как трудоёмкость пополнения онтологии ![]() не высока и сравнима с
написанием форм Бэкуса-Наура для соответствующих синтаксических конструкций.
не высока и сравнима с
написанием форм Бэкуса-Наура для соответствующих синтаксических конструкций.
В случае отсутствия исходного кода, пользователь должен описать структуру входных и выходных данных вручную при помощи высокоуровневого графического интерфейса.
Онтология ![]() используется для описания поддерживаемых
системой графических объектов и типов сцен. Пользователь при помощи
высокоуровневого графического интерфейса выбирает соответствующие специфике
решаемой задачи тип сцены и объекты, а также назначает соответствия элементов
структуры входных и выходных данных решателя свойствам этих объектов.
используется для описания поддерживаемых
системой графических объектов и типов сцен. Пользователь при помощи
высокоуровневого графического интерфейса выбирает соответствующие специфике
решаемой задачи тип сцены и объекты, а также назначает соответствия элементов
структуры входных и выходных данных решателя свойствам этих объектов.
Онтология ![]() описывает доступные в системе визуализации
семантические фильтры. О механизме фильтрации более подробно рассказано в
разделе 4.
описывает доступные в системе визуализации
семантические фильтры. О механизме фильтрации более подробно рассказано в
разделе 4.
Онтологии ![]() ,
, ![]() , и
, и ![]() не являются изолированными: они имеют общую
часть, описывающую поддерживаемые типы данных (рис. 2).
не являются изолированными: они имеют общую
часть, описывающую поддерживаемые типы данных (рис. 2).
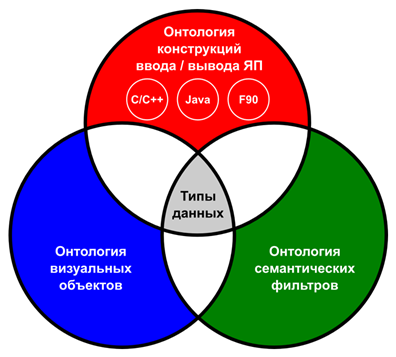
Рис. 2. Схематичное представление базы знаний системы научной визуализации SciVi в виде диаграммы Эйлера-Венна
В механизме адаптации выделяется два основных функциональных блока: интеграционный модуль и редактор потока данных.
Интеграционный модуль отвечает за построение так называемого «онтологического профиля» источника данных, представляющего собой описание структуры данных источника в терминах онтологии. Данный модуль может принимать на вход как готовое (созданное пользователем при помощи высокоуровневого графического интерфейса) описание структуры данных источника данных или решателя, так и исходный код решателя.
В первом случае заданные пользователем настройки
трансформируются в онтологический профиль источника данных. В случае
доступности исходного кода решателя, автоматически (по расширению
предоставленного файла) определяется язык программирования и, если описание
синтаксических конструкций этого языка присутствует в онтологии ![]() , для него автоматически
генерируется лексический анализатор. Этот анализатор вычленяет из
предоставленного кода описания структур входных и выходных данных, на основании
которых генерируется онтологический профиль решателя.
, для него автоматически
генерируется лексический анализатор. Этот анализатор вычленяет из
предоставленного кода описания структур входных и выходных данных, на основании
которых генерируется онтологический профиль решателя.
Редактор потока данных, принимая на вход, подготовленный
интеграционным модулем онтологический профиль, формирует для пользователя
палитру доступных визуальных объектов, сцен и семантических фильтров (взятых из
репозитория системы, где хранятся их описания в виде онтологий ![]() и
и ![]() , соответственно). Пользуясь
предоставленной палитрой, пользователь имеет возможность задать параметры
фильтрации для конкретных элементов структуры данных источника, установить их
соответствия свойствам визуальных объектов, а также объединить визуальные
объекты в сцены различных типов. В результате этих настроек автоматически генерируется
описание сцены для визуализации, представляющее собой шаблон, который в
процессе работы системы визуализации автоматически заполняется фактическими
данными, извлекаемыми из источника.
, соответственно). Пользуясь
предоставленной палитрой, пользователь имеет возможность задать параметры
фильтрации для конкретных элементов структуры данных источника, установить их
соответствия свойствам визуальных объектов, а также объединить визуальные
объекты в сцены различных типов. В результате этих настроек автоматически генерируется
описание сцены для визуализации, представляющее собой шаблон, который в
процессе работы системы визуализации автоматически заполняется фактическими
данными, извлекаемыми из источника.
При наличии исполняемого файла решателя возникает возможность настройки обратной связи системы SciVi с этим решателем так, чтобы в процессе визуализации пользователь мог при помощи автоматически сгенерированного графического интерфейса изменить входные данные и запустить процесс повторной генерации подлежащего визуализации результата («режим on-line»). При отсутствии исполняемого файла решателя возможна визуализация заранее подготовленных данных, сохранённых, например, в файле («режим off-line»).
4. Подсистема семантических фильтров
Онтологии ![]() и
и ![]() используются для настройки системы SciVi на
специфику предметной области и особенности решателя. Однако часто возникает
необходимость дополнительной настройки на специфику решаемой задачи, когда
пользователю требуется осуществить некоторую особую обработку (фильтрацию)
данных, выдаваемых решателем. Чтобы освободить пользователя от необходимости
вносить изменения в решатель или создавать промежуточное программное
обеспечение для такого рода фильтрации, было решено реализовать механизм
настраиваемой предобработки данных на стороне SciVi, добавив в её состав
подсистему так называемых семантических фильтров.
используются для настройки системы SciVi на
специфику предметной области и особенности решателя. Однако часто возникает
необходимость дополнительной настройки на специфику решаемой задачи, когда
пользователю требуется осуществить некоторую особую обработку (фильтрацию)
данных, выдаваемых решателем. Чтобы освободить пользователя от необходимости
вносить изменения в решатель или создавать промежуточное программное
обеспечение для такого рода фильтрации, было решено реализовать механизм
настраиваемой предобработки данных на стороне SciVi, добавив в её состав
подсистему так называемых семантических фильтров.
Семантический фильтр – это отображение ![]() вида
вида
![]() ,
,
где I – множество типизированных входов,
S – множество настроечных параметров,
O – множество типизированных выходов.
Набором фильтров, их свойствами и поведением в системе SciVi
управляют знания, формализованные в виде онтологии ![]() . Для каждого фильтра эта онтология
включает в себя описание следующих характеристик:
. Для каждого фильтра эта онтология
включает в себя описание следующих характеристик:
1. Роли фильтра (описание того, чем фильтр является в системе – оператором или константой).
2. Множества входных и выходных данных фильтра (интерфейса фильтра).
3. Множества допустимых полей и настроек фильтра (свойств фильтра).
4. Реализации фильтра (в виде программного кода на интерпретируемых языках JavaScript, Python или Lua, либо на компилируемом во время выполнения языке GLSL, либо в виде ссылки на модуль или библиотеку, реализующую фильтр).
Пример онтологического описания фильтра нормировки вектора представлен на рис. 3.
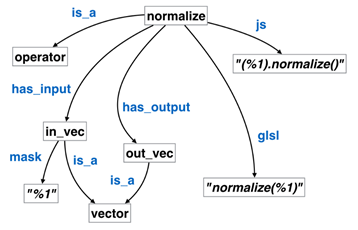
Рис. 3. Фрагмент онтологии семантических фильтров, описывающий фильтр нормировки вектора
В данном примере используются следующие типы связей:
1. is_a: родитель – потомок;
2. has_input: оператор фильтрации – его входные данные;
3. has_output: оператор фильтрации – его выходные данные;
4. mask: вход оператора фильтрации – маска подстановки;
5. js: оператор фильтрации – его реализация на языке JavaScript;
6. glsl: оператор фильтрации – его реализация на языке GLSL.
Приведённый фрагмент онтологии описывает следующие знания о фильтре «normalize»: этот фильтр является оператором, имеет один вход типа «vector» с маской подстановки «%1» и один выход типа «vector», а также имеет реализации на языках JavaScript и GLSL.
Если пользователь выберет этот фильтр из палитры инструментов и соединит его с какими-либо элементами описания структуры данных источника (решателя), система визуализации автоматически встроит программный код реализации этого фильтра в объемлющий код обработчика данных, на лету создав готовый к исполнению (или компиляции, как в случае с GLSL) модуль фильтрации. При этом переменная, которая согласно коду обработчика, содержит входные данные для фильтра, будет автоматически подставлена в код фильтра на место маски подстановки (в приведённом примере – «%1», присутствующая в обоих вариантах реализации фильтра). Таким образом нужные данные будут перенаправлены в выбранный пользователем фильтр.
Аналогично происходит обработка и более сложных фильтров, имеющих несколько входов и выходов. Каждая маска подстановки при этом содержит в себе номер входа, к которому она относится.
Предобработка данных посредством семантических фильтров осуществляется в два единообразно представляемых этапа: первичная обработка на стороне сервера и окончательная – на стороне клиента.
На стороне сервера выполняется наиболее общая фильтрация, которая настраивается вместе с регистрацией в системе очередного решателя и, как правило, изменяется достаточно редко. Цель этой фильтрации – удовлетворить базовые потребности пользователя в изменении данных, порождаемых решателем. На этот этап предлагается выносить вычислительно сложные операции, так как чаще всего компьютер, на котором выполняется сервер, превосходит по вычислительной мощности компьютеры клиентов.
В процессе работы системы клиенту отправляется онтологический профиль данных, получаемых в результате первичной фильтрации. Этот профиль представляет собой онтологическое описание структуры результирующих данных.
На стороне клиента выполняется фильтрация, адаптирующая получаемые им данные к решению частных задач. Настройка этой фильтрации может изменяться независимо от сервера.
Фактические данные, необходимые для визуализации, кешируются на стороне клиента, что даёт возможность решать некоторые частные задачи визуализации и анализа данных без участия сервера (в «режиме off-line»), одной лишь перенастройкой используемых механизмов фильтрации. Например, пользователь может изменять линейный масштаб на логарифмический, или отсекать часть нежелательных для визуализации данных при помощи некоторой оконной функции.
Настройка семантических фильтров для обоих этапов фильтрации осуществляется единообразно и представляет собой построение диаграммы потока данных (англ. Data Flow) [5] при помощи встроенного в систему SciVi визуального редактора графов. Вершины в этой диаграмме соответствуют фильтрам, а дуги – связям по данным. Каждая вершина, в зависимости от представляемого ей фильтра, может иметь несколько входов и выходов, а также несколько управляющих элементов (полей ввода значений, слайдеров, радиокнопок и т. п.), соответствующих параметрам этого фильтра.
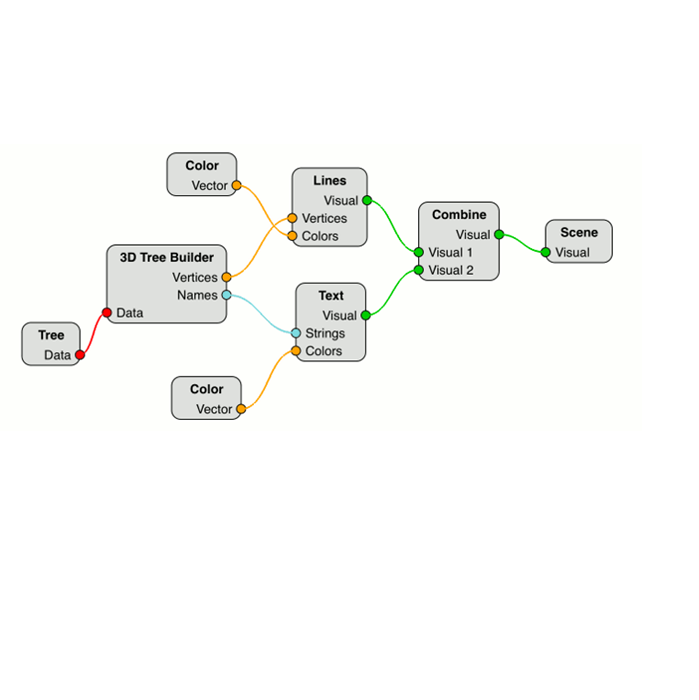
Для единообразия в виде узлов диаграммы потока данных представляются не только фильтры, но также и источники данных, визуальные объекты и графические сцены. Пример диаграммы потока данных, формируемой на стороне клиента, представлен на рис. 4. Для наглядности, роль каждого из представленных на иллюстрации узлов подписана.
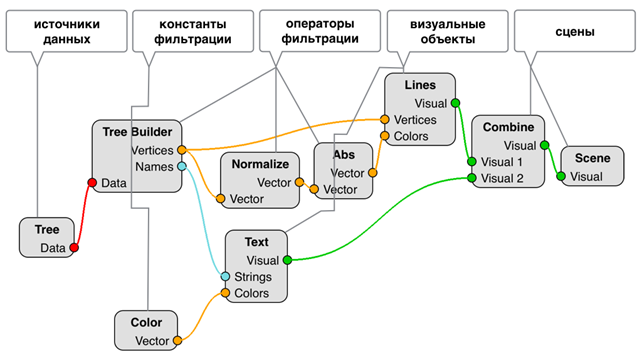
Рис. 4. Пример диаграммы потока данных, формируемой на стороне клиента системы научной визуализации SciVi
Рассмотрена задача построения трёхмерного филогенетического дерева (задача из области генетики), данные для которого генерирует решатель ClustalW [6], работающий на основе данных генетического материала, полученного в Институте экологии и генетики микроорганизмов УрО РАН (г. Пермь).
Согласно онтологическому профилю источника данных
формируется вершина «Tree» (исток графа потока данных). Далее пользователь из
автоматически сформированной по онтологиям ![]() и
и ![]() палитры инструментов выбирает необходимые
визуальные объекты, константы и операторы фильтрации, соединяя их входы и
выходы так, чтобы получилась схема обработки данных.
палитры инструментов выбирает необходимые
визуальные объекты, константы и операторы фильтрации, соединяя их входы и
выходы так, чтобы получилась схема обработки данных.
В приведённом примере создан фильтр данных «Tree Builder», который преобразует данные из источника в пригодный для построения трёхмерного дерева формат. На выходе этот фильтр имеет массив вершин («Vertices»), задающих узлы дерева, и массив соответствующих листьям дерева текстовых меток («Names») с их координатами в пространстве. Выход, соответствующий массиву вершин, соединён напрямую с соответствующим входом визуального объекта «Lines», отвечающего за отображение массива точек в пространстве в виде линий. Кроме того, массив координат вершин подвергается преобразованию при помощи операторов нормировки («Normalize») и взятия абсолютного значения («Abs»), и результат этого преобразования направляется на отвечающий за цвет вход визуального объекта «Lines». Тем самым пространственные данные из массива вершин интерпретируются не только как положение линий в пространстве, но, одновременно с этим, и как цвета.
Множество текстовых меток передаётся визуальному объекту «Text», который отвечает за отображение текста в привязке к позициям на трёхмерной сцене. Кроме того, вход, отвечающий за цвет у визуального объекта «Text» соединён с выходом фильтра-константы «Color», что позволяет задать одинаковый цвет сразу всем текстовым меткам.
Выходы визуальных объектов «Lines» и «Text» соединены со входами специального узла-комбинатора «Combine». Этот узел является элементом множества графических сцен и служит для комбинирования ровно двух различных визуальных объектов на одной сцене. При необходимости отображения большего числа объектов, несколько вершин типа «Combine» могут быть объединены в каскад.
Выход вершины «Combine» соединяется с вершиной-стоком «Scene», что символизирует окончание цепочки преобразования данных и вывод результата на экран.
Результат визуализации, соответствующей настройкам из рассмотренного примера, представлен на рис. 5.
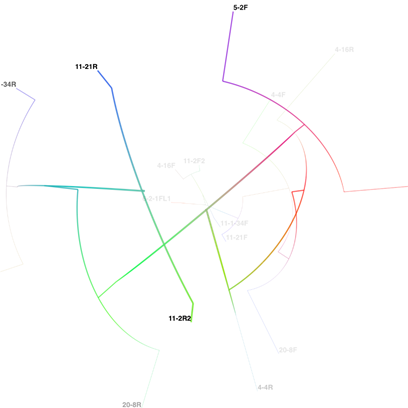
Рис. 5. Результат визуализации трёхмерного филогенетического дерева средствами системы научной визуализации SciVi
Различные настройки фильтрации и соответствующие им результаты визуализации показаны в виде gif-анимации на рис. 6.
Нажмите на изображение для проигрывания или остановки анимации
Рис. 6. Анимационная последовательность, демонстрирующая различные варианты отображения одних и тех же данных с разными настройками фильтрации в системе научной визуализации SciVi
Пример диаграммы потока данных, формируемой на стороне сервера, представлен на рис. 7.
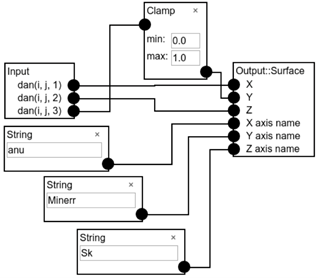
Рис. 7. Пример диаграммы потока данных, формируемой на стороне сервера системы научной визуализации SciVi
В приведённом примере элемент подлежащих визуализации данных dan(i, j, 3) подвергается воздействию фильтра Clamp, который имеет параметры min и max и реализует функцию отсечения (англ. Сlamping) входного значения относительно отрезка [min, max]. Результат визуализации с настройками, представленными в виде диаграммы потока данных на рис. 7, приведён на рис. 8. За основу взят решатель задачи оптимизации гибридных разностных схем Burgers2 [7].
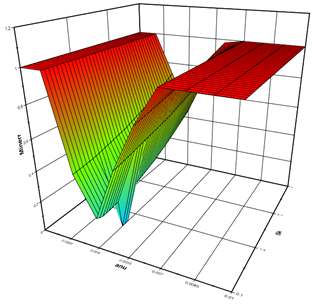
Рис. 8. Результат визуализации средствами системы SciVi зависимости ошибки численной схемы решения дифференциальных уравнений от настроечных параметров этой схемы
Принцип построения диаграммы потока данных на стороне клиента и сервера полностью идентичен. Онтологический подход к описанию и хранению фильтров позволяет расширять их набор без модификации ранее отлаженного программного кода клиента и сервера, легко адаптируя систему визуализации к новым задачам.
5. Тонкий Web-клиент
Для всех поддерживаемых платформ нативный клиент SciVi характеризуется высокой эффективностью реализации, так как его ядро написано на языке C++, и он напрямую выполняется на процессоре вычислительного устройства, что позволяет минимизировать накладные расходы на вызовы низкоуровневых функций. Однако, использование нативного клиента не всегда удобно, поскольку требует скачивания и установки на машину клиента.
Чтобы дать пользователю возможность гибкой и удобной работы с системой SciVi, было принято решение в дополнение к нативному клиенту реализовать также тонкий браузерный клиент, в котором средства визуализации основаны на стандарте WebGL. На сегодняшний день данный стандарт поддерживается почти всеми современными браузерами как для настольных компьютеров, так и для мобильных устройств. Таким образом, тонкий клиент, так же, как и толстый, является мультиплатформенным.
Предлагаемая схема клиентов системы SciVi представлена на рис. 9.
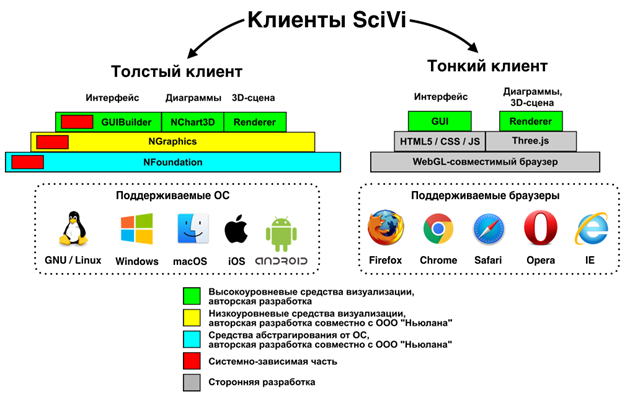
Рис. 9. Схема клиентов системы научной визуализации SciVi
В качестве графического движка, на основе которого работает тонкий клиент, было принято решение использовать Three.js [8] ввиду хорошей документированности и высокой стабильности функционирования приложений на базе этой библиотеки. Графический интерфейс пользователя (GUI) тонкого клиента разрабатывается с использованием HTML5, CSS и JavaScript.
Наличие тонкого Web-клиента позволяет пользователю без специальной подготовки быстро воспользоваться функциональностью системы SciVi с любого компьютера или мобильного устройства, даже без прав на администрирование, без установки дополнительного программного обеспечения.
При наличии постоянно функционирующего сервера, система SciVi может работать как полноценное SaaS (англ. Software as a Service) приложение.
Следует, однако, отметить, что тонкий клиент обладает несколько меньшей производительностью по сравнению с нативным, а также, в отличие от нативного, не может работать в автономном режиме (без подключения к сети Интернет). Более низкая производительность объясняется тем, что алгоритмы рендеринга реализованы на интерпретируемом языке JavaScript и исполняются в среде браузера. Наше решение предоставляет пользователю возможность выбора типа клиентской части приложения в зависимости от специфики решаемых задач и инфраструктуры программно-аппаратного обеспечения.
6. Заключение
В данной работе основное внимание уделено описанию новых возможностей адаптивной мультиплатформенной клиент-серверной системы научной визуализации SciVi, построенной на принципах онтологического инжиниринга: разработке подсистемы семантических фильтров и реализации тонкого клиента. Семантические фильтры позволяют гибко настраивать SciVi на специфику решаемой задачи, освобождая пользователя от необходимости изменять исходный код решателя в том случае, если требуется оперативно по некоторому алгоритму преобразовать генерируемые данные перед визуализацией (например, применить к ним некоторую оконную функцию, или изменить тип масштаба с линейного на логарифмический). Тонкий (браузерный) клиент позволяет использовать SciVi без установки на компьютер пользователя какого-либо специализированного программного обеспечения (требуется лишь наличие WebGL-совместимого браузера и подключения к сети Интернет).
Дальнейшее развитие системы SciVi предполагает расширение базы поддерживаемых способов визуализации и видов семантических фильтров для решения более широкого круга реальных научных задач из различных областей знания. Кроме того, планируется изучение вопроса адаптации SciVi к решателям, генерирующим сверхбольшие объёмы данных (англ. Big Data).
Список литературы
1. Рябинин К.В., Чуприна С.И. Адаптация систем научной визуализации к сторонним решателям. Труды Юбилейной 25-й Международной конференции GraphiCon2015. 2015. С. 127–131.
4. Рябинин К.В. Методы и средства разработки адаптивных мультиплатформенных систем визуализации научных экспериментов. дис. канд. физ.-мат. наук: 05.13.11. 2015. 207 с. URL: http://library.keldysh.ru/diss.asp?id=2015-ryabinin
8. Библиотека Three.js. URL: http://threejs.org/ (дата обращения: 05.05.2016).
AUTOMATED TUNING OF SCIENTIFIC VISUALIZATION SYSTEMS TO VARYING DATA SOURCES
K.V. Ryabinin, S.I. Chuprina, A.Yu. Bortnikov
Perm State National Research University, Perm, Russian Federation
kostya.ryabinin@gmail.com, chuprinas@inbox.ru, a.yu.bortnikov@yandex.ru
Abstract
This article describes the novel method to tackle challenges of scientific visualization systems’ adaptation to application domain phenomena. The authors suggest model-based approach to scientific visualization systems building based on ontology engineering methods. This approach enables to defeat such drawbacks of modern scientific visualization systems as a lack of high-level tools to adapt to varying third-party data sources (software and hardware solvers, data storages, etc.) and multiplatform portability. According to the suggested approach, the visualization system is driven by knowledge about graphical objects’ and scenes’ properties, specifics of the tasks being solved as well as hardware and software infrastructure. These different kinds of knowledge are stored as ontologies, which are formal models of application domains including a set of concepts with their definitions, a set of relations between the concepts and, if needed, a set of axioms describing semantic restrictions and laws imposed for concepts and relations. Using model-driven architecture enables to modify system behavior without changing of the source code. The suggested approach ensures a high-level tuning both of rendering and feedback to solver (allowing to start/stop the solver and to change its input data). Developed software and used technologies provide a multiplatform portability of the visualization system preserving a high efficiency of the rendering. The described approach has been used as a basis for implementation of multiplatform client-server scientific visualization system named SciVi, which has been successfully used to solve a number of practical and important scientific problems.
This article describes the new capabilities of the system SciVi, such as development of intuitive data filtering subsystem and thin Web-client.
SciVi data filtering subsystem enables to preprocess the data, which are to be visualized to suit the personal preferences of users, for example, sampling data for a certain period only. SciVi filtering mechanism has two parts: primary preprocessing on the server side and final preprocessing on the client side. The primary preprocessing goal is to satisfy most common user’s needs to change data generated by solver. The final preprocessing goal is to fine-tune data for special research cases. To tune the data filtering high-level graphical user interface based on data flow diagram is used.
Thin Web-client allows using SciVi on desktop computers and mobile device without any additional software installation.
Keywords: scientific visualization, multiplatform portability, ontology engineering, mobile devices, data flow diagram, thin client, OpenGL, WebGL.
References
1. Ryabinin K.V., Chuprina S.I. Adaptacija sistem nauchnoj vizualizacii k storonnim reshateljam [Scientific visualization systems adaptation to third-party solvers]. Proceedings of Annual 25th International Conference GraphiCon2015. 2015. Pp. 127–131. [In Russian]
2. Ryabinin K., Chuprina S. Development of Ontology-Based Multiplatform Adaptive Scientific Visualization System. Journal of Computational Science. Elsevier, 2015. Vol. 10. Pp. 370–381.
3. Ryabinin K., Chuprina S. Using Scientific Visualization Tools to Bridge the Talent Gap. Procedia Computer Science. Elsevier, 2015. Vol. 51. Pp. 1734–1741.
4. Ryabinin K.V. Metody i sredstva razrabotki adaptivnyh mul'tiplatformennyh sistem vizualizacii nauchnyh jeksperimentov [Methods and means for development of multiplatform systems for scientific experiments’ visualization]. PhD Thesis: 05.13.11. – M., 2015. – 207 p. URL: http://library.keldysh.ru/diss.asp?id=2015-ryabinin [In Russian]
5. Lee B., Hudson A.R. Issues in Dataflow Computing. Advances in Computers. Elsevier, 1993. Vol. 37. Pp. 285–333.
6. Larkin M.A., Blackshields G., Brown N.P., Chenna R., McGettigan P.A., McWilliam H., Valentin F., Wallace I.M., Wilm A., Lopez R., Thompson J.D., Gibson T.J., Higgins D.G. ClustalW and ClustalX version 2. Bioinformatics. 2007. Vol. 23. Iss. 21. Pp. 2947–2948.
7. Bondarev A.E., Bondarenko A.V., Galaktionov V.A., Mihajlova T.N., Ryzhova I.G. Razrabotka instrumental'nogo programmnogo sredstva Burgers2 dlja optimizacii gibridnyh raznostnyh shem [Design of Program Tool Burgers2 for Hybrid Finite Diference Schemes Optimization and Visualization]. Scientific Visualization. 2013. Vol. 5, No. 1. Pp. 26–37. [In Russian]
8. Three.js library. URL: http://threejs.org/ (last visited: 05.05.2016).