МОДЕЛЬ И СРЕДСТВА ИНТЕРАКТИВНОГО АНАЛИЗА ДИНАМИКИ И СВЯЗЕЙ ПОТОКОВ ПУБЛИКАЦИЙ НАУЧНОЙ ИНФОРМАЦИИ
Е.С. Горбун, Н.В. Максимов, К.В. Монанков, Ш.У. Низаметдинов
Национальный исследовательский ядерный университет «МИФИ», Москва
Содержание
2. Технологии построения дескриптивных описаний и поиска взаимозависимостей временных рядов
3. Методы сглаживания временных рядов
4. Практическая реализация методов анализа
6. Пример исследования взаимосвязи понятий во времени
Аннотация
Рассмотрены подходы и методы исследования взаимосвязи предметных областей, динамика развития которых представляется временными рядами потоков научных публикаций. Метод основан на приведении рядов к описательной форме, что позволяет свести задачу к поиску символьных последовательностей. Представлены интерактивные визуально-аналитические средства манипулирования выборками документов, используемые для формирования анализируемых пространств документов, отражающих динамику отдельных направлений и аспектов.
Ключевые слова: информационный поиск, временные ряды, малые выборки, аппроксимация, метод Ирвина, метод медианного фильтра.
1. Введение. О некоторых особенностях представления динамики научных направлений и поиска зависимостей
Методы анализа динамики публикационной активности многогранно и глубоко проработаны в наукометрии и библиометрии. Вместе с тем, для науки представляет интерес выявление сложившихся или потенциальных зависимостей направлений, обусловленных взаимосвязями этапов жизненного цикла, использованием обоснований и методов других отраслей, возникающей доступностью ресурсов, переносом технологий и т.п.
Приведем из [1] пример исследования взаимосвязи научных аспектов и терминов по теме «Исследование тория в атомной энергетике». В составе темы были выделены три аспекта – ФИЗИКА, МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ, ЭКСПЕРИМЕНТ – и для каждого из них сформированы поисковые запросы. По соответствующим запросам был проведен итеративный поиск в ретроспективной реферативно-библиографической базе данных INIS (МАГАТЭ) и для каждого из аспектов были построены временные ряды публикационной активности (рис. 1).
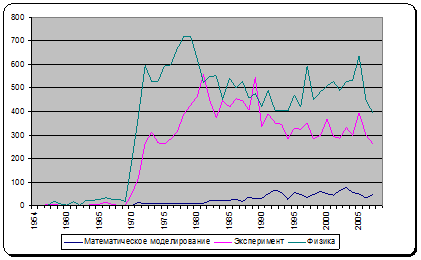
Рис. 1. Временные ряды публикационной активности по аспектам.
Особенности развития направлений, характеризующиеся приведенными на рис. 1 рядами, объясняются следующими факторами:
· интерес к внедрению тория в ядерную энергетику всегда возникает при прогнозировании бурного роста числа АЭС в мире и возможной нехватки природного урана для обеспечения АЭС топливом (1970-е и 2000-е годы). Это наиболее четко отражено динамикой публикаций аспекта ФИЗИКА;
· аспект ЭКСПЕРИМЕНТ имеет всплеск в 1970-х годах, но не имеет его в 2000-х годах (как в случае аспекта ФИЗИКА) вследствие того, что ядерные данные по торию к этому времени были уже хорошо изучены;
· всплеск в конце 1970-х - начале 1980-х годов (аспекты ЭКСПЕРИМЕНТ и МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ) связывается с появлением ПЭВМ и повсеместным ростом интереса к математическому моделированию физических процессов с помощью специальных программ.
На рис. 2 приведены временные ряды публикаций, связанных уже с отдельным понятием ТРАНСМУТАЦИЯ, построенные по каждому из аспектов.
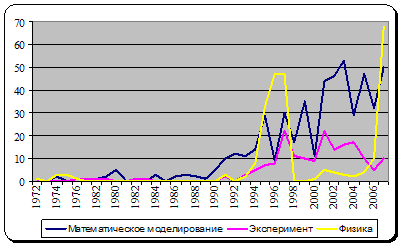
Рис.2. Распределение публикаций для термина ТРАНСМУТАЦИЯ по аспектам
Динамика временных рядов показывает, что интенсивное исследование физического явления трансмутации в 1990-х годах повлияло на динамику экспериментов. В 2000-е годы развитие этих аспектов происходит с запозданием примерно на год по сравнению с динамикой, отражаемой термином ТРАНСМУТАЦИЯ. Это обусловлено тем, что при стремительном изучении явления трансмутации нужно было некоторое время для создания нового оборудования и для подготовки к проведению экспериментов. То есть, теоретические знания повлияли на появление практических результатов со сдвигом во времени.
Приведенный пример иллюстрирует важную особенность, которую необходимо учитывать для выявления связей между направлениями: взаимосвязь определяется фрагментами рядов, которые не синхронны во времени и имеют разные амплитудно-частотные характеристики. То есть зависимость скорее имеет событийный характер, причем амплитуда и интервал фрагментов, соответствующих связанным событиям, могут быть не сопоставимы по величине.
Другая особенность состоит в том, что период развития научных направлений довольно короткий и, кроме того, науке свойственна междисциплинарность. То есть, при анализе приходится иметь дело с малыми выборками и с большим количеством временных рядов. Вследствие этого применение хорошо разработанных традиционных методов математической статистики [2] практически невозможно, хотя некоторые из них в той или иной степени учитывают эту специфику, в частности, вейвлет-анализ и гранулярные вычисления. Однако алгоритм вейвлет-анализа [3] является трудоемким в вычислительном плане, а гранулярные вычисления [4] позволяют объединять объекты в гранулы, исходя из их неразличимости, эквивалентности, сходства и близости, хотя при этом объединение объектов в группы – это неоднозначный и сложный процесс, требующий знаний конкретной предметной области. Но, главное, и вейвлет-анализ, и гранулярные вычисления не ориентированы на выявление взаимосвязей между рядами.
Проблемой является и собственно построение временного ряда для отдельного направления: часто направление науки не имеет четких границ, нет единых формальных методов идентификации принадлежности к направлению публикаций, имеющих междисциплинарный характер. Более того, наиболее интересными являются случаи, когда зависимости еще не стали фактом, а только формируются. Такие взаимосвязи принципиально не могут быть определены формальными методами, но они становятся очевидными эксперту, который по сходству/различию и логике направлений сравнительно легко выявляет зависимости при визуализации распределений, отражающих динамику совокупности направлений. Такими распределениями могут быть не только временные ряды публикаций, но и, например, распределения по тематикам и видам документов, распределения публикаций различных авторов или организаций. Распределения могут быть как двумерные, так и многомерные. Наиболее удобны для анализа двумерные и псевдотрехмерные представления, где помимо привычных координатных осей используется, например, цветовая дифференциация значений. Примером псевдотрехмерного представления результатов поиска является распределение числа документов, опубликованных в разные годы авторами, имеющими различные ученые степени.
В статье предложен метод, позволяющий найти взаимозависимости между различными научными областями на основе представления рядов в виде символьных последовательностей, отражающих их «поведенческие» характеристики, что позволит использовать классические механизмы документального дескрипторного поиска «по вхождению».
В статье также представлены интерактивные визуально-аналитические средства манипулирования выборками документов, используемые для формирования анализируемых пространств, отражающих динамику отдельных направлений и аспектов.
2. Технологии построения дескриптивных описаний и поиска взаимозависимостей временных рядов
Принимая во внимание «событийную» природу корреляции направлений, для построения дескриптивного представления временного ряда в виде символьной последовательности будем использовать характеристические свойства (особенности) динамики направлений анализируемой предметной области. Такими особенностями являются:
монотонность, означающая стабильность развития или угасания конкретной области науки и техники;
периодичность, проявляющаяся в долгосрочном периоде и могущая быть следствием технических причин (например, публикацией больших сборников трудов конференций, проводимых с таким же периодом);
пилообразность, означающая, что в научном направлении постоянно происходят существенные изменения, или что на отдельных временных отрезках поток информации не полон.
Временной ряд может иметь нулевые участки, происхождение которых может быть следствием и упомянутых выше причин.
Таким образом, конкретный ряд публикаций отражает не только развитие собственно направления, но и действие различных факторов технического, организационного и другого рода, которые в общем случае невозможно точно определить и исключить из рассмотрения. Кроме того, если развитие науки в целом (и на протяженном отрезке времени) характеризуется устойчивыми закономерностями и количественными показателями, то динамика публикаций отдельного направления практически непредсказуема. Это определяется не только естественной для процесса познания спонтанностью, но еще и упомянутой выше условностью как отнесения публикации к конкретному направлению, так и факта её появления в конкретное время и в конкретном виде.
Для того чтобы в той или иной степени снизить влияние такого рода факторов при выделении закономерностей, необходимо используются методы укрупнения и нормализации (сглаживания).
Для формирования дескриптивных описаний, позволяющих свести поиск к случаю регулярных выражений, исследуются основные характеристики ряда, ряд сглаживается в зависимости от своих характеристик и далее формируется символьная последовательность, каждый символ которой отражает соответствующий тип развития (скачок, равномерность и т.д.). Каждый тип участка кодируется соответствующим символом:
«0» - участок неизменного состояния;
«+» - участок возрастания;
«−» - участок убывания;
«/» - участок сильного (аномального) возрастания;
«\» - участок сильного (аномального) убывания.
Таким образом, поиск «коррелирующих» (фрагментарно подобных) временных рядов будет проводиться не по параметрам и статистическим свойствам временного ряда, а по их дескриптивным описаниям, что сводит задачу к символьному поиску. Поиск можно провести с дополнительными настройками, например, регулируя совпадения краев при ручном редактировании регулярного выражения или используя поисковые операторы маскирования с указанием точных или допустимых расстояний между характеристическими фрагментами соотносимых рядов.
3. Методы сглаживания временных рядов
Как отмечалось ранее, для задач анализа и поиска временных рядов, построенных на малых выборках и не обладающих свойством стационарности, нет адекватных статистических методов обработки. Более того, технологические особенности их формирования предопределяют неточность и неполноту отображения ситуации в анализируемой предметной области (ПрО). Поэтому, исходя из принципа соответствия, примем стратегию применения наиболее подходящих математических методов в предположении, что необходимая определяющая информация о ПрО будет обеспечена со стороны эксперта. Эксперт, используя средства визуальной операционной среды, на основе неявных знаний (личных знаний о ПрО, которые не представлены в БД в явной форме) может в интерактивном режиме не только сформировать выборки действительно значимых документов, но и выделить в построенном системой дескриптивном описании действительно определяющие участки, изменить характер других участков (если ему известны соответствующие факты), выбрать степень обобщения и особенности соотнесения и т.д.
Анализ математического аппарата методов сглаживания показал, что для рассматриваемого случая наиболее предпочтительны метод Ирвина [5] и метод медианного фильтра [6], так как они не зависят от временных ограничений, чувствительны к резким выбросам и позволяют за счет изменения параметров учитывать характеристики рядов. Метод Ирвина позволяет диагностировать аномальные участки и сглаживать аномальные выбросы. Метод медианного фильтра хорошо подавляет импульсные помехи, уменьшая при этом количество аномальных выбросов. Для рядов с нулевыми точками и периодичной динамикой разработан комбинированный метод сглаживания.
Сглаживание временных рядов проводится в зависимости от их
динамических свойств, определяемых на основе позволяющего выявлять участки
аномальности коэффициента отклонения ![]() , величина которого
вычисляется для всех точек временного ряда [5].
, величина которого
вычисляется для всех точек временного ряда [5].
Сглаживание производится по следующим правилам:
- участки без всплесков (аномалий) сглаживаются методом медианного фильтра;
- ряды с интенсивной пилообразной динамикой и с большим числом всплесков сглаживаются методом Ирвина, в результате чего сгладятся участки аномального возрастания и убывания, обусловленные малыми выборками, монотонные же участки останутся неизменными;
- ряды с нулевыми значениями, причины которых могут иметь технический характер, сглаживаются методом, равномерно распределяющим публикации по нулевым участкам так, что сумма публикаций всего ряда остается неизменной;
- после проверки на периодичность ряды с интенсивной динамикой сглаживаются комбинированным методом, а ряды с неинтенсивной динамикой - методом медианного фильтра.
Чтобы управлять степенью обобщения (огрубление бывает полезно при визуальном анализе, когда эксперт может субъективно нивелировать влияние разных факторов), вводится коэффициент сглаживания, определяющий сильную, среднюю и слабую степень обобщения.
Для монотонных участков ряда без всплесков, для которых величина коэффициента отклонения меньше табличного значения [5], сглаживание проводится путем замены значений точек ряда средним арифметическим соседних точек ряда с округлением до ближайшего целого числа. Это позволяет акцентировать внимание на участках ряда с интенсивной динамикой.
При сглаживании методом Ирвина значения точек ряда, для
которых величина коэффициента отклонения больше табличного значения, ![]() заменяются средним
арифметическим соседних точек ряда с учетом коэффициента сглаживания.
заменяются средним
арифметическим соседних точек ряда с учетом коэффициента сглаживания.
Сглаживание методом медианного фильтра [6] происходит путем замены исходного значения каждой точки ряда на значение медианы из соответствующей окрестности точек.
Сглаживание нулевых участков в том случае, когда нулевые участки появляются периодически, производится с учетом длины нулевого отрезка. В том случае, когда нет периодичности (трудно предположить причины возникновения нулевых участков), их следует сгладить, распределяя публикации по нулевым участкам, так, что сумма публикаций всего ряда остается неизменной.
Сглаживание комбинированным методом проводится путем сравнения трех рядов (исходного, сглаженного методом Ирвина и сглаженного методом медианного фильтра). Точке ряда, для которой оба оцененных значения одновременно больше или меньше исходного, присваивается значение, которое ближе к исходному. В противном случае (величина исходного находится в интервале между оцененными значениями) – точке присваивается среднее арифметическое трех значений с учетом коэффициента сглаживания.
На рис. 3 изображен пример сглаживания ряда с дескриптивным описанием «+++---+++-+++--/-0+++++--++-+-+--+-000+-+-+++-+++--».
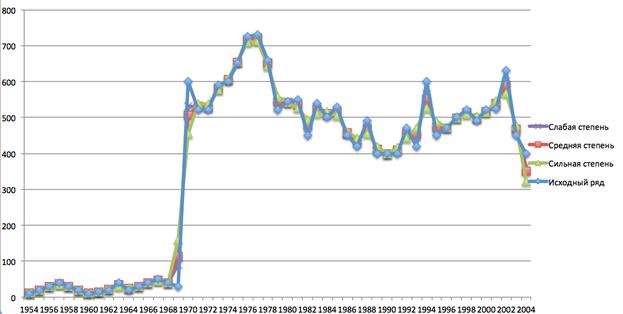
Рис. 3. Пример сглаживания ряда
Для оценки погрешности сглаживания используется относительная ошибка аппроксимации (сглаживания) [7]:
Для примера, представленного на рис. 3, относительная ошибка имеет следующие значения соответственно для разных степеней сглаживания:
![]()
4. Практическая реализация методов анализа
Методы интерактивного анализа динамики и связей документальных потоков (как программный компонент, имеющий специализированные визуальные формы) были реализованы в составе документальной информационно-аналитической системы xIRBIS [8], имеющей развитые механизмы поиска и интерфейсные средства управления взаимодействия пользователя с его информационным пространством. Основные функциональные возможности и визуальные решения организации пространства и управления процессами информационного поиска системы представлены в [9].
Процедурно модуль анализа получает данные путем фильтрования и грануляции элементов записей – документов, отбираемых в результате поисков в базах данных. Но, следует отметить, что и результаты анализа представляют собой не только визуализацию распределений, но сами являются инструментом поиска. Во-первых, от точки распределения можно перейти к документам им соответствующим и далее использовать метод поиска аналогов. Во-вторых, для выбранного временного ряда можно искать ряды (и соответственно, документы), динамика которых коррелирует с выбранным, что обеспечивает качественно новые возможности не только для исследования предметной области, но и для определения направлений поиска.
5. Управление данными
Пространство документов для анализа зависимостей может быть сформировано различными способами. Обычно анализируемые множества документов – это результаты поиска в базе данных по тематическим запросам, группируемые и идентифицируемые (именуемые) пользователем либо на этапе включения выборки в анализируемое пространство (далее по аналогии с OLAP-технологиями – гиперкуб), либо непосредственно при анализе, используя операции выборки и формирования среза. Срез представляет собой подмножество гиперкуба, полученное в результате фиксации значений одного или нескольких атрибутов документа (измерений гиперкуба). Таким образом, пользователь формирует некоторое персональное пространство документов для построения распределений и поиска похожих временных рядов.
Рассмотрим далее некоторые функции визуального аналитического компонента на примере темы «Исследование тория в атомной энергетике» в аспекте МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ. Для этого сформируем в БД INIS под управлением ИПС xIrbis [8] поток публикаций с помощью запроса
((NEUTRON* and REACTOR*CORES* and REACTOR*) and ((PROGRAM* or BENCH*) and REACTOR*) or ((NEUTRON*FLUX* or FLUX*DENSITY* or NEUTRON*TRANSPORT* or CROSS*SECTIONS*) and (calculation* or MATHEMATICAL*MODELS or uncertainty*data*values)))
результаты поиска по которому помещаются в протокол поиска (рис. 4).
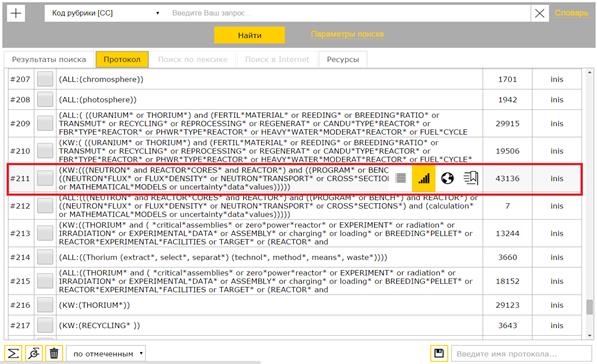
Рис. 4. Протокол поиска в ИПС xIrbis
Переход к функциям визуального аналитического компонента инициируется пиктограммой «Статистика» (выделена на рис. 4). Текущий поисковый результат формирует новый гиперкуб – новое подмножество в именованном пространстве (рис. 5 а), либо подмножество может быть добавлено к существующему гиперкубу (рис. 5 б).
Рис. 5. Объединение и идентификация анализируемых подмножеств
Таким путем можно сформировать несколько выборок (подмножеств) по различным аспектам и предметным областям для дальнейшего исследования их поведения и установления взаимосвязей. Для детализации или обобщения темы можно использовать операции выборки и формирования среза, а затем добавить эти полученные и именованные подмножества документов в гиперкуб анализируемой предметной области.
Построив пространство документов по теме и идентифицировав подмножества, отражающие различные аспекты - ФИЗИКА, МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ, ЭКСПЕРИМЕНТ, можно построить временные ряды потоков публикаций этих аспектов (см. рис. 6).
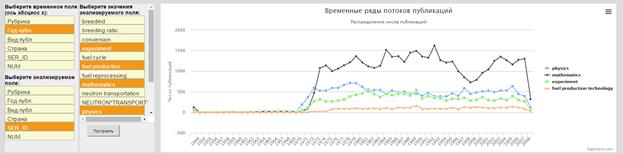
Рис. 6. Временные ряды аспектов по теме «Исследование тория в атомной энергетике»
Используя визуальные средства обработки временных рядов интерактивном режиме можно осуществить, например, отбор документов по годам (рис. 7). Или сформировать срез гиперкуба путем фиксации одного или нескольких атрибутов, например, построить распределения по видам публикаций для аспекта МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ (рис. 8).
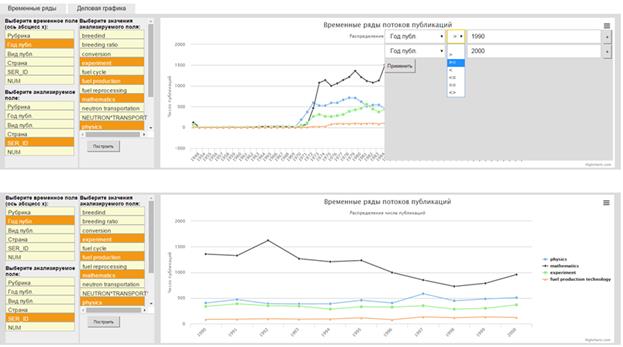
Рис. 7. Пример операции выборки документов по годам
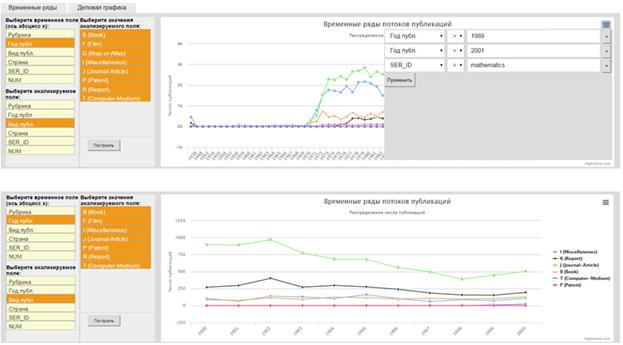
Рис. 8. Пример операции формирования среза
На полученном после применения описанных выше операций подмножестве документов можно построить аналитические распределения или провести поиск коррелирующих рядов.
Кроме того, графический интерфейс позволяет переходить от точки на графике к документам, соответствующим этой точке, что дает возможность непосредственно в процессе анализа развивать поисковый процесс, используя функции, ассоциированные с формой просмотра документа (рис. 9).
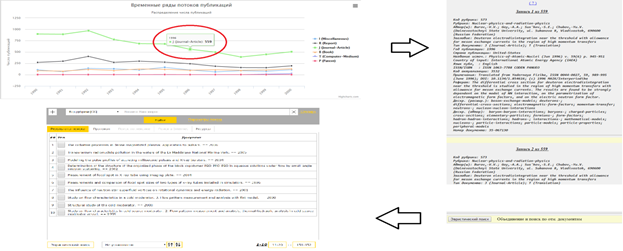
Рис. 9. Активизация просмотра документов и поиска из визуальной статистики
Преимущество описанного подхода состоит в том, что управление данными происходит в диалоговом режиме с помощью визуальных средств, не прибегая к составлению поисковых запросов, интерактивно взаимодействуя с графическими представлениями.
6. Пример исследования взаимосвязи понятий во времени
Рассмотрим публикационную динамику понятий по теме «Изучение солнечных пятен». Проведем поиск в реферативно-библиографической базе данных INIS по ключевым словам, встречающимся в научных публикациях по этой теме (всего 10 ключевых слов) и объединим результаты поиска в один гиперкуб. Построенные временные ряды потоков публикаций, содержащих рассматриваемые термины, приведены на рис. 10.
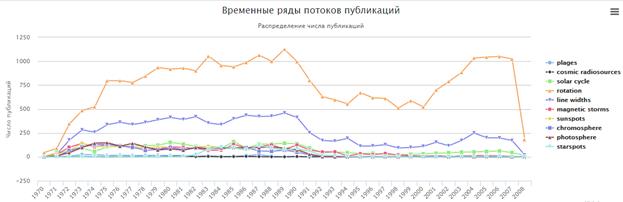
Рис. 10. Временные ряды потоков публикаций по теме «Изучение солнечных пятен»
Последовательно для каждого из терминов, используя функцию формирования дескриптивного описания, построим символьные описания и проведем поиск похожих временных рядов с помощью регулярных выражений.
Например, для временного ряда термина «sunspots» было построено следующее символьное описание «++/--+--+--++---+--+-----0+--+-+-++---» и проведен поиск похожих рядов, результат которого приведен на рис. 11.
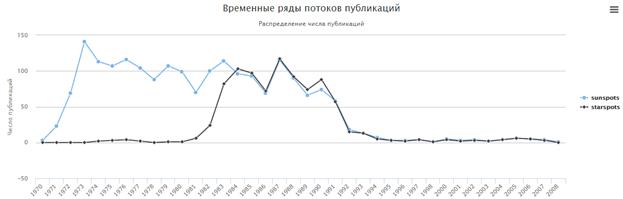
Рис. 11. Результат поиска похожих временных рядов для термина «sunspots»
Распределение показывает, что в 70-80-е годы наблюдается стабильный интерес к термину «sunspots», а термин «starspots» начинает интенсивно использоваться только в 80-е годы, причем после 1984 года термины «sunspots» и «starspots» развиваются практически синхронно. Это объясняется тем, что по мере перехода к изучению более далеких, чем Солнце, звезд с 1984 года контекст (и объем) термина изменились от частного случая (в контексте «sunspots») к более широкому - «starspots». То есть в научных областях, изучающих солнечные пятна, стали чаще отождествлять Солнце с другими звездами: произошло расширение предметной области от пространства солнечной системы до звездного пространства.
Построенные временные ряды для терминов «chromosphere», «photosphere» и «solar cycle» приведены на рис. 12.
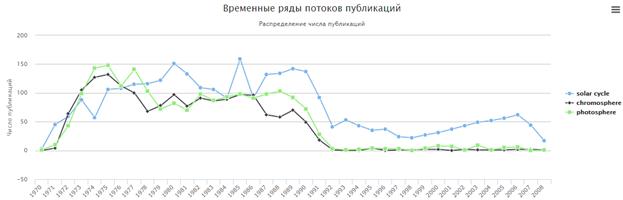
Рис. 12. Результат поиска похожих временных рядов для термина «solar cycle»
Термины «chromosphere» и «photosphere» имеют очень похожую динамику, некоторые расхождения предположительно определялись тем, какие научные наблюдения легче было производить. Наблюдается причинно-следственная связь динамики терминов «chromosphere», «photosphere» и «solar cycle». То есть повышение интереса к изучению хромосферы и фотосферы приводило к увеличению знаний о солнечном цикле, которое происходило с некоторой задержкой.
7. Заключение
Разработан математический аппарат анализа динамики и связей потоков публикаций, обеспечивающий приведение временного ряда к описательной форме, что позволяет проводить поиск похожих временных рядов не по параметрам и свойствам временного ряда, а по их символьным описаниям. То есть задача нахождения частичных совпадений временных рядов с возможными сдвигами во времени сводится к классическим методам документального дескрипторного поиска. Поиск можно провести с дополнительными настройками, например, «установлением» границ или участков при ручном редактировании регулярного выражения с использованием поисковых операторов маскирования с указанием точных или допустимых расстояний между характеристическими фрагментами соотносимых рядов.
Представленные в статье примеры иллюстрируют применение методов для анализа публикационной активности в научной сфере. Безусловно, разработанные методы и средства могут применяться как для анализа любых временных рядов, так и для анализа произвольных соотношений, когда обнаружение взаимосвязей распределений может указывать на наличие некоторой первопричины синхронного поведения визуализируемых распределениями процессов предметной области.
Визуальный интерактивный интерфейс позволяет не только просматривать документы, но и анализировать группы документов, взаимосвязи между группами. С помощью интерфейсных элементов пользователь может предметно выбирать ту часть полученного результата поиска, которая его интересует, например, путем фиксации значений отдельных атрибутов, что сокращает размерность анализируемого пространства без потери значимой для пользователя информации.
Таким образом, интерактивные человеко-машинные процедуры, в которых неточность математических методов (вследствие формальной неадекватность их применения) компенсируется вариантностью подготавливаемых системой выборок и представлений для экспертного анализа, которая в совокупности с предоставляемыми визуальными средствами манипулирования выборками и управлением процедурами их сопоставления при поиске обеспечивает общую эффективность анализа.
Список литературы
1. Голицына О.Л., Максимов Н.В., Строганов В.И., Тихомиров Г.В. Системы управления знаниями и среда информационной поддержки научно-исследовательских и образовательных процессов. Системы управления и информационные технологии, № 1.1 (43), 2011, с. 126-134.
2. Walter Enders. Applied econometric time series.- Wiley University of Alabam. DOI:978-0470-50539-7.
3. T. Subba Rao, S. Subba Rao, C.R. Rao. Handbook of Statistics: Time Series Analysis: Methods and Applications. Elsevier B.V. 2012, 978-0-444-53858-1.
4. Тарасов В.Б., Калуцкая А.П., Святкина М.Н. Гранулярные, нечеткие и лингвистические онтологии для обеспечения взаимопонимания между когнитивными агентами – М.:МГТУ им.Н.Э.Баумана, 2012. – 278 с.
5. Федосеев В.В., Гармаш А.Н., Дайитбегов Д.М., Орлова И.В., Половников В.А. Экономико-математические методы и прикладные модели: Учеб. пособие для вузов / Под ред. В. В.Федосеева. М.: ЮНИТИ, 1999, 392 с.
6. Huang T.S., ed.; Eklundh J.-O., Huang T.C., Justusson В.I., Nussbaumer H.J., Tyan S.G., Zohar S. Two-Dimensional Digital Signal Processing II. Transforms and Median Filters. -Berlin-Heidelberg: Springer, 1981. DOI: 10.1007/BFb0057592
7. Карманов В.С. Анализ временных рядов. Новосибирск, 2007, 28 с.
8. Максимов Н.В. Документальная информационно-аналитическая система xIRBIS: Программа для ЭВМ. / Голицына О.Л., Максимов Н.В., Окропишин А.Е. и др. // Свидетельство о Гос. регистрации программ для ЭВМ №2014619640 от 17.09.2014.
9. Максимов Н.В., Голицына О.Л., Усенко А.Л. Структура и компоненты операционного визуального пространства интерактивного поиска научной информации. Научная визуализация, 2014, т. 6, № 4, с. 96-106.
MODEL AND TOOLS FOR INTERACTIVE ANALYSIS OF DYNAMICS AND RELATIONS OF SCIENTIFIC INFORMATION PUBLICATIONS FLOWS
E.S. Gorbun, N.V. Maksimov, K.V. Monankov, Sh.U. Nizametdinov
National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation
Abstract
This article describes the approaches and methods for the research of the interrelation of subject areas, the development dynamics of which is represented by time series of the scientific publications flows. The method is based on representing the time series in descriptive form, which allows to transform the statistical task to the task of character sequences seek. It presents interactive visual-analytical means for handling the document samples that are used to form the analyzed spaces of documents that reflect the dynamics of individual areas and aspects.
Keywords: information retrieval, time series, small samples, approximation, Irwin’s method, median filter method.
References
1. Golitsyna O.L., Maksimov N.V., Stroganov V.I., Tikhomirov G.V. Sistemy upravlenija znanijami i sreda informacionnoj podderzhki nauchno-issledovatel'skih i obrazovatel'nyh processov [Knowledge management systems the environment of information support of scientific research and educational processes]. Management systems and information technologies, № 1.1 (43), 2011, pp. 126-134.
2. Walter Enders. Applied econometric time series. - Wiley University of Alabam. DOI: 978-0470-50539-7.
3. T. Subba Rao, S. Subba Rao, C. R. Rao. Handbook of Statistics: Time Series Analysis: Methods and Applications. -Elsevier B. V. 2012, 978-0-444-53858-1.
4. Tarasov V.B., Kaluskaya A.P., Svyatkina M.N. Granuljarnye, nechetkie i lingvisticheskie ontologii dlja obespechenija vzaimoponimanija mezhdu kognitivnymi agentami [Granular, and fuzzy linguistic ontology in order to achieve understanding between cognitive agents]. Moscow: BMSTU, 2012, 278 p.
5. Fedoseyev V.V., Garmash A.N., Dayitbegov D.M., Orlova I.V. Polovnikov V.A. Jekonomiko-matematicheskie metody i prikladnye modeli: Ucheb. posobie dlja vuzov [Economic-mathematical methods and applied models: Educational textbook for Universities] / Under the edition of Vladimir Fedoseyev. Moscow: UNITY, 1999, 392 p.
6. Huang T.S., Eklundh J.-O., T. C. Huang, V. I. Justusson, H. J. Nussbaumer, S. G. Tyan, Zohar S. Two-Dimensional Digital Signal Processing II. Transforms and Median Filters. Berlin-Heidelberg: Springer, 1981. DOI: 10.1007/BFb0057592
7. Karmanov V.S., Time series analysis. Novosibirsk, 2007, 28 p.
8. Maksimov N.V. Dokumental'naja informacionno-analiticheskaja sistema xIRBIS: Programma dlja JeVM [Documentary information-analytical system xIRBIS: Software]. / Golitsyna O.L., Maksimov N.V., Okropishin A.E., etc. // The state registration сertificate of computer programs No. 2014619640 from 17.09.2014.
9. Maksimov N.V., Golitsyna O.L., Usenko A.L. The structure and components of the operational visual space for scientific interactive information retrieval. Scientific visualization, 2014, no. 4, vol. 6, pp. 96 – 106.