ГРАФИЧЕСКИЙ ПОДХОД К ПРОБЛЕМЕ ПОИСКА ПОДОБНЫХ ТЕКСТОВ
В.Л. Евсеев, Г.Г. Новиков
Национальный исследовательский ядерный университет «МИФИ», Москва, Россия
VLEvseev@mephi.ru, GGNovikov@mephi.ru
Содержание
2. Анализ современного состояния разработок
4. Концепция предлагаемого метода
5. Общий вид поискового алгоритма.
5.2 Построение цепочек слов, образующих словарный домен
Аннотация
Данная работа посвящена одному из возможных подходов к разработке системы сравнения текстов возникшему при решении задачи сравнения текстов нормативно-правового характера.
Предложенный метод позволяет отыскать нормативные документы, фрагменты которых похожи на введенный пользователем запрос. Представлен анализ состояния разработок в области нечеткого полнотекстового поиска, из которого следует, что можно выделить следующие методы поиска, реализованные в информационно-поисковых системах разного типа: информационно-поисковые системы и системы выборки данных.
Для решения задачи текстового поиска по сходству было введено понятие «сравнение», которое сводится к отысканию документов находящихся в информационно-поисковой базе, части которых в той или иной мере сходны с исходным поисковым шаблоном. В основу предлагаемого метода положено предположение о том, что сходство документов определяется близостью их изображений в виде текстов без проведения семантического исследования их содержания. В результате, размерность решаемой задачи снижается на несколько порядков и попадает в сферу возможного для общедоступных средств вычислительной техники (персональных компьютеров). Разработана общая структура поискового алгоритма. Для решения задачи поиска похожих текстов построен поисковый словарь, подсловарь и домен образующих цепочек в задаче нечеткого полнотекстового поиска. Это позволило получить множество домен образующих цепочек слов пригодное для оценки релевантности исследуемого текста и поискового шаблона.
Ключевые слова: Сравнение текстов, текстовый поиск по сходству, язык запросов, поисковый шаблон, поисковая база, релевантность, поисковый алгоритм, поисковый словарь, подсловарь.
1. Введение
Необходимость и актуальность разработки метода сравнения текстов связаны с наличием в современной нормативно - правовой базе большого количества документов, особенно принятых в переходные периоды становления любого государства, регулирующих одни и те же правоотношения по-разному, а зачастую и противоречиво. Это создает существенные трудности в их систематизации и кодификации. В предложенном методе сравнения текстов целью является не поиск конкретного фрагмента текста или ключевого слова – это типичная задача поисковых систем, а предварительная сортировка документов по степени похожести друг на друга для дальнейшей экспертной оценки. Это позволяет значительно снизить требования к основным характеристикам персональных компьютеров, используемых для достижения вышеизложенной цели. В данной статье предложен один из возможных подходов к решению этой задачи, а именно - имитирующий беглый визуальный просмотр документов человеком. При таком просмотре текст воспринимается не как объект для чтения, а скорее как некоторое изображение, которое подсознательно сравнивается с воображаемым эталоном.
2. Анализ современного состояния разработок
Анализ состояния разработок в области нечеткого полнотекстового поиска показывает, что можно выделить следующие методы поиска, реализованные в информационно-поисковых системах разного типа: информационно-поисковые системы и системы выборки данных.
Один из наиболее фундаментальных обзоров задач информационного поиска и информационно-поисковых систем представлен в работах [1,2]. В дальнейшем будем использовать терминологию, принятую в этих работах.
В настоящее время информационные системы, работающие с электронными текстовыми документами, условно делят на две категории: информационно-поисковые системы (ИПС, в англоязычной терминологии они фигурируют под термином information retrieval systems) и системы выборки данных (СВД, data retrieval systems). Данная классификация условна и в её контексте многие современные информационные системы совмещают в себе свойства как систем выборки данных, так и информационно-поисковых систем. Базовые отличия систем выборки данных и информационно-поисковых систем, представлены в таблице 1.
Таблица 1 - Отличия систем выборки данных и информационно-поисковых систем
|
|
СВД |
ИПС |
|
Соответствие данных поисковому запросу |
Точное |
Частичное |
|
Классификация документов |
Детерминированная |
Вероятностная |
|
Язык запросов |
Искусственный |
Естественный |
|
Критерии выборки документов |
Булева функция релевантности |
Вероятностная функция релевантности |
|
Устойчивость к ошибкам в данных и запросах |
Неустойчивы |
Устойчивы |
Типичным примером систем выборки данных являются классические реляционные системы управления базами данных (СУБД), где в качестве языка запросов используется тот или иной диалект языка запросов SQL. Этот язык искусственный и позволяет задавать поисковые запросы лишь для поиска на точное соответствие или поиска по заданному шаблону. В современных системах выборки данных основной задачей является обеспечение высокой скорости выполнения поисковых запросов пользователей, а также надёжного и эффективного хранения данных. В свою очередь, информационно-поисковые системы предназначены для решения более общей задачи поиска, чем поиск на точное соответствие, где конечной целью поиска является выбор релевантной поисковому запросу информации, степень релевантности которой можно определить как степень её смысловой близости к поисковому запросу. А это, в свою очередь, ведёт к тому, что поисковые запросы в такого рода системах должны быть основаны на естественном языке, т.е. на том же языке на котором сформулирована исходная информация. Системы выборки данных и информационно - поисковые системы работают с некоторой коллекцией документов. Исходную коллекцию документов можно рассматривать как список записей (документов), где каждая запись содержит в себе некоторый список слов, состоящих из символов алфавита. В реальных информационных системах в исходном множестве документов может содержаться дополнительная информация, описывающая документы, которая так же может использоваться для осуществления поиска.
Наиболее близкими по своему смыслу к решаемой задаче являются методы нечеткого поиска фрагментов текста часто используемые при решении задачи антиплагиата [3]. Из них наиболее известны и получили широкое распространение методы использующие шинглы, MinHash, семантические сети и ряд других.
Алгоритм шинглов.
Алгоритм часто применяется для веб-документов и используется в целях борьбы с интернет-плагиатом.
Этапы алгоритма:
1. Канонизация текста.
Включает в себя очистку текста от форматирования и приведение его к нормальной форме по средствам исключения предлогов, союзов, знаков препинания, веб-форматирования (HTML-теги). Иногда удаляются прилагательные.
2. Разбиение на шинглы (рисунок 1).
Чтобы выделить из текста шинглы (от английского «чешуйка») сначала определяются с длиной последовательностей слов. Чаще всего длина шинглов лежит в районе 2-8 слов. Последовательности слов берутся не стык в стык, а внахлест, например, предложение «Кот хотел запрыгнуть на стул, но промахнулся» после первого этапа будет выглядеть как «кот хотел запрыгнуть стул промахнулся», а после разбиения на шинглы (возьмем размер шингла - 3 слова) так: {кот хотел запрыгнуть; хотел запрыгнуть стул; стул промахнулся}, либо так: {кот хотел запрыгнуть; хотел запрыгнуть стул; запрыгнуть стул промахнулся}. То есть, нахлест может быть равным как одному слову, так и большему числу слов [4].
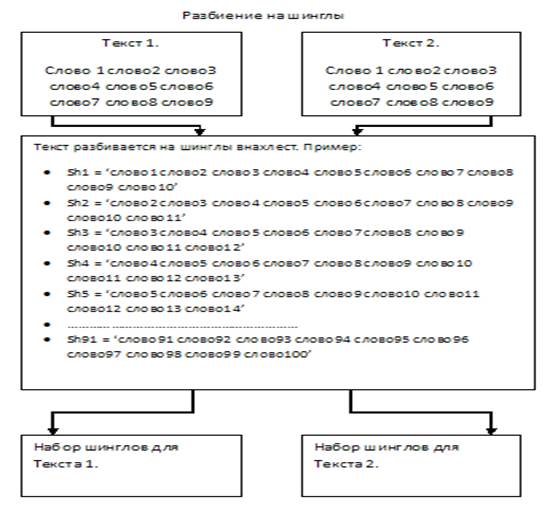
Рис. 1. Разбиение на шинглы
3. Алгоритм шинглов (вычисление хэшей шинглов, случайная выборка контрольных сумм, сравнение и определение результата).
Необходимо для каждого шингла рассчитать контрольную сумму. Обычно используется алгоритм хэширования. Для каждого шингла рассчитывается 84 значения контрольной суммы через разные функции (например SHA1, MD5, CRC32 и т.д., всего 84 функции). Итак, каждый из текстов будет представлен в виде двумерного массива из 84-х строк, где каждая строка характеризует соответствующую одну из 84-х функций контрольных сумм (рисунок 2).
Из полученных наборов, случайным образом будут отобраны 84 значения для каждого из текстов и сравнимы между собой в соответствии функции контрольной суммы, через которую каждый из них был рассчитан (рисунок 3). Таким образом, для сравнения будет необходимо выполнить всего 84 операции.
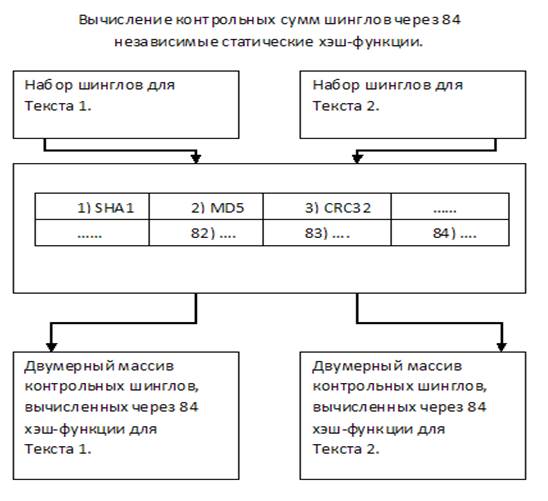
Рис. 2. Вычисление контрольных сумм шинглов
Далее выполняется выборка контрольных сумм по какому-то признаку – делятся на одно число, четные и т. д. Это делается для того, чтобы значения, попавшие в выборку, были равномерно распределены по тексту. Например, выбирают самое минимальное значение из каждой строки.
Тогда на выходе имеем набор из минимальных значений контрольных сумм шинглов для каждой из хэш-функций.

Рис. 3. Случайная выборка 84 шинглов для сравнения
Затем сравниваются выборки двух текстов и определяется степень похожести текстов (рисунок 4).
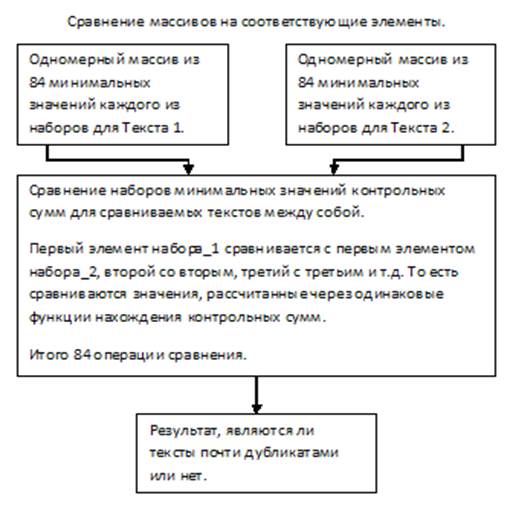
Рис. 4. Сравнение массивов на соответствующие элементы
Следует отметить, что на текущий момент времени применяются усовершенствованные алгоритмы определения дубликатов. К примеру, альтернативный алгоритм определения нечетких дубликатов был создан и разработан в Яндексе - метод супершинглов [4].
3. Метод супершинглов.
Строится ограниченный набор контрольных сумм. Над 84 шинглами строится 6 супершинглов (по 14 шинглов). Тексты считаются совпавшими при совпадении хотя бы двух супершинглов из 6.
Мегашинглы.
На практике метод супершинглов продемонстрировал, что для определения нечетких дубликатов хватает минимум двух совпадений супершинглов. Это означает, что для наилучшего поиска совпадений как минимум двух супершинглов, документ должен быть представлен различными попарными соединениями из 6 супершинглов. Такие группы называют мегашинглами. Согласно данному методу выявления дубликатов, документы являются между собой идентичными, если у них совпадает минимум один мегашингл.
Алгоритм MinHash.
Идея этого алгоритма заключается в вычислении вероятности равенства минимальных значений хеш-функций элементов множеств.
В основе метода лежит коэффициент Жаккарда
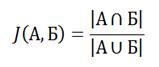 (1)
(1)
где А и Б - множества сравниваемых элементов.
То есть, коэффициент Жаккарда – это количество элементов в пересечении, делённое на количество элементов в объединении. Данный коэффициент равен нулю, когда множества не имеют общих элементов, и единице, когда множества равны, а в остальных случаях значение где-то посередине [5].
Необходимо найти пересечения и объединения данных множеств. На практике, для эффективного выполнения двух последних операций, множества представляют в виде хэш-таблицы без ассоциированных с ключами значений. В итоге выполняется 4 операции: построение двух таблиц (при сравнении двух текстов), определение пересечения и определение объединения.
Ключевая идея алгоритма MinHash заключается в следующем. Пусть есть два множества М1, М2 и хэш-функция h, которая умеет высчитывать хэши для элементов этих множеств. Далее, определяют функцию hmin(S), которая вычисляет функцию h для всех членов какого-либо множества S и возвращает наименьшее её значение. Тогда переменные в (1) имеют следующие значения: A = hmin(М1), B = hmin(M2).
Трудность заключается в том, что если мы просто вычислим hmin(М1) и hmin(М2) для наших двух фрагментов текста, а затем сравним значения, то это ничего не даст, т.к. вариантов всего два — равны или не равны. Здесь надо добыть достаточный объём статистики по нашим множествам и вычислить близкий к истине J(М1, М2). А для этого вместо одной функции h вводим несколько независимых хэш-функций, а точнее k функций:
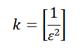 (2)
(2)
где ε — желаемая наибольшая величина ошибки.
Так например, для вычисления J(М1, М2) с ошибкой не более, чем 0.1, необходимо 100 хэш-функций. Данный алгоритм обычно используется для построения рекомендательных сервисов.
Методы, использующие семантические сети.
Семантическая сеть - информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Cемантическая сеть является одним из способов представления знаний (рисунок 5).
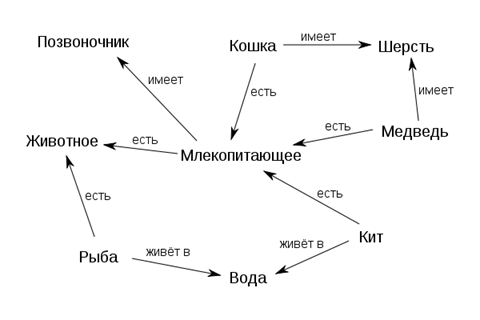
Рис. 5. Пример семантической сети
В лингвистике отношения фиксируются в словарях и в тезаурусах. В словарях в определениях через род и видовое отличие родовое понятие занимает определённое место. В тезаурусах в статье каждого термина могут быть указаны все возможные его связи с другими родственными по теме терминами. От таких тезаурусов необходимо отличать тезаурусы информационно-поисковые с перечнями ключевых слов в статьях, которые предназначены для работы дескрипторных поисковых систем [6]. Задача определения факта заимствования сводится к сравнению моделей, отражающих смысловую нагрузку текстов. Анализ ведется с использованием алгоритмов на графах, модифицированных и оптимизированных для применения в рамках данной задачи. Использование схем анализа данных в этом методе может позволить выявлять факт заимствования, даже если оригинал был определенным образом модифицирован (выполнен перевод, слова были заменены на синонимы, текст был изложен с использованием другой лексики и т.д.).
Более подробный анализ современного состояния разработок информационно-поисковых систем, выходящий за рамки данной работы, показывает, что ни один из известных в настоящий момент методов прямо не подходит для решения поставленной нами задачи.
Исходя из вышесказанного, предлагается метод решения задачи текстового поиска по сходству, имитирующий по своей сути процесс беглого просмотра текста человеком с целью определения ВИЗУАЛЬНОЙ ПОХОЖЕСТИ страниц просматриваемого текста без чтения и вникания в семантическую составляющую.
4. Концепция предлагаемого метода
В основу предлагаемого метода положено предположение о том, что сходство документов определяется близостью их изображений в виде текстов без проведения семантического исследования их содержания. Таким образом, размерность решаемой задачи снижается на несколько порядков и попадает в сферу возможного для общедоступных средств вычислительной техники (персональных компьютеров). Снижение размерности задачи достигается путем рассмотрения текстов документов поисковой базы как ряда своеобразных графических изображений, в которых пикселем является слово документа. Таким образом, в качестве результата сравнения будем рассматривать совокупность совпадений слов в исследуемом тексте документа из поисковой базы и в поисковом шаблоне с учетом их взаимного расположения или «геометрической близости».
Место в исследуемом тексте, где находятся совпадения слов искомого шаблона со словами текста, будем называть доменом, состоящим из цепочек совпадений. Основной количественной характеристикой похожести исследуемого текста и поискового шаблона будем считать релевантность, которую в рамках рассматриваемого подхода будем считать определяющейся:
1. количеством слов поискового шаблона, содержащихся в домене Qnt (от англ. quantity – количество);
2. расстоянием попавших в домен слов по отношению друг к другу суть их общей плотностью Qlt (от англ. quality – качество).
В рамках данного подхода определим их, как количественный и качественный параметры релевантности соответственно. Вклад этих параметров в функцию релевантности не является одинаковым и линейным, поэтому в общем случае, релевантность R можно описать через функцию (3), определяющую вклад каждой из этих компонент.
![]() (3)
(3)
Вид функции может быть различным, и он подлежит дальнейшему изучению, однако ясно, что значение функции, полученное в результате поиска словарного домена с поисковым шаблоном, может лежать в диапазоне от 0 (отсутствие совпадений) до 1 (полное совпадение), Рисунки 6, 7, 8 наглядно иллюстрируют предлагаемый вариант рассмотрения текстовой информации.
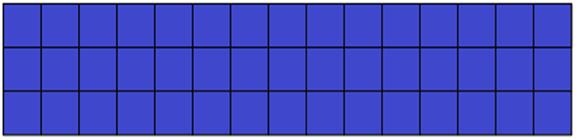
Рис. 6. Поисковый шаблон
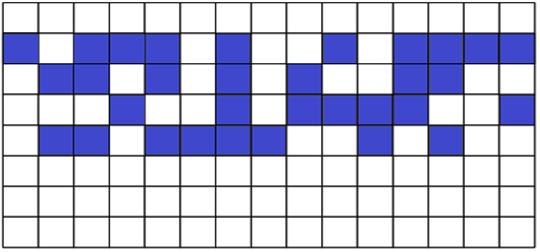
Рис. 7. Словарный домен с большим значением релевантности
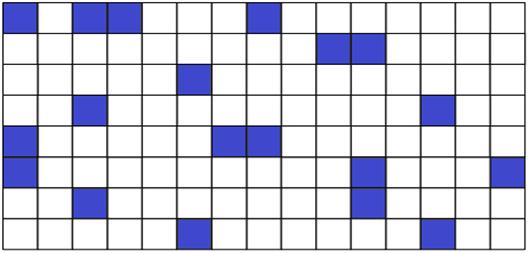
Рис. 8. Словарный домен с малым значением релевантности
Рисунок 6 представляет собой графическое изображение поискового шаблона, каждое из слов которого может принимать участие в формировании словарной цепочки, составляющей словарный домен. Один квадрат изображения соответствует одному слову запроса.
На рисунках 7 и 8 видно, каким образом могут быть геометрически расположены слова шаблона поиска (синие квадраты) в сравниваемом на сходство фрагменте документа. Еще раз отметим, что при данном подходе анализ исследуемого документа производится не с точки зрения его смыслового содержания, а только с позиции его словарного состава.
В примере на рисунке 7 количество и плотность слов, которые окрашены в синий цвет, выше, чем в примере, проиллюстрированном на рисунке 8. Следовательно, значение релевантности, соответствующее рисунку 7, больше значения релевантности, соответствующее рисунку 8.
5. Общий вид поискового алгоритма.
Для дальнейшей разработки предложенного метода необходимо определиться с общей структурой поискового алгоритма и в первую очередь с тем методом, который позволит определять основной фактор – совпадение слов шаблона и текста из базы. Методов поиска слов в настоящий момент разработано немало [7], однако, наиболее предпочтительными являются идеи, лежащие в основе методов словарного поиска по сходству [8].
Функционально, алгоритм содержит этап предварительного процессирования поисковой базы, а именно:
создание индекса, условно называемого словарем;
подготовки запроса путем создания индекса называемого подсловарем;
процедуры построения цепочек для словарных доменов;
численной оценки величины релевантности.
5.1. Построение поискового словаря и домен образующих цепочек в задаче нечеткого полнотекстового поиска
Рассмотрим один из наиболее специфичных подготовительных этапов при решении задачи поиска похожих текстов - построение поискового словаря - индекса, призванного обеспечить быстрый поиск похожих слов в составе словарного домена. Геометрический подход к определению подобия текстов, подробно рассмотренный в работах [8,9,10,11], является основой для данной разработки. Используются понятия и терминологическая база определенная в работах [1,2,7,12,13].
Итак, на первом шаге алгоритма информация, содержащаяся в словаре, формируется путем обработки поисковой базы. В виду того, что главной направленностью настоящей работы является разработка именно алгоритма текстового поиска, а не максимально эффективная его реализация, то в качестве объекта хранения поисковой базы выбран файл текстового формата ASCII.
Данные, которые используются в ходе построения поисковых словарных цепочек на рассматриваемом этапе работы алгоритма, представляют для нас наибольший интерес. Они вычисляются для каждого слова поисковой базы с длиной, равной или превышающей 3 символа, а затем заносятся последовательно в словарь. То есть, для каждого слова хранятся:
хеш-значение слова;
точки вхождения слова в поисковую базу;
длина слова.
Хеш-значение - используется для идентификации каждого отдельного слова и используется как компактный индекс, по которому извлекается информация о множестве смещений каждого слова от начала поисковой базы. Дело в том, что одно и то же слово может встречаться не один раз, как в одном документе, так и во всей поисковой базе. Такой подход обусловлен удобством физической организацией словаря в виде хеш-таблицы. Точки вхождения слов в поисковую базу, то есть смещения относительно ее начала и длины, необходимы для вычисления расстояний между словами. Порядок действий, описанный в рамках данного шага, можно проследить на рисунке 9.
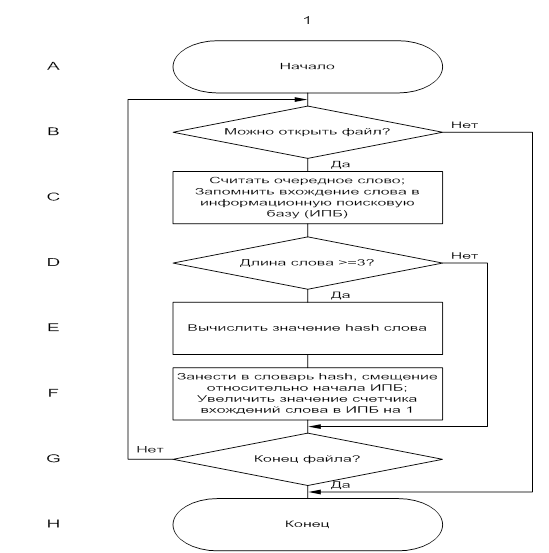
Рис. 9. Создание поискового словаря
На втором шаге работы алгоритма происходит ввод исходного поискового шаблона и построение его образа в виде, аналогичном представлению словаря поисковой базы. Назовем этот образ подсловарем. Из-за важности данного процесса в дальнейшем, следует еще раз подчеркнуть, что содержание подсловаря определяется словарным составом введенного поискового шаблона, а его структура аналогична структуре уже имеющегося в наличии словаря, созданного путем обработки поисковой базы. Это означает, что в подсловаре, так же как и в словаре, содержатся:
хеш-значение каждого слова поискового шаблона;
множество его вхождений в поисковую базу;
его длина.
Алгоритм построения подсловаря показан на рисунке 10. Следует отметить, что подсловарь строится на основе уже сформированного словаря, причем последние два пункта извлекаются из словаря в подсловарь по хеш-значению слова. При построении подсловоря не берутся в расчет слова с длиной менее трех символов.
Далее, требуется построить результативные цепочки слов составляющих словарный домен.
5.2 Построение цепочек слов, образующих словарный домен
Одной из самых значимых частей работы поискового алгоритма является построение цепочек слов, составляющих словарный домен. Этот процесс, согласно вышеизложенной общей концепции, подразумевает нахождение в поисковой базе слов запроса, расположенных на максимально близком расстоянии друг к другу. Близость слов рассчитывается как модуль разности позиций начала одного слова и позиции окончания предшествующего ему другого слова. Цепочки слов строятся только по тем словам, информация о которых хранится в подсловаре, т.е. по словам поискового шаблона.
Следует отметить, что позиция начала слова рассчитываются как смещение данного слова относительно начала поисковой базы, а конец - с помощью длины данного слова, которая хранится в подсловаре, т.е. позиция вхождения слова в базу плюс длина слова в символах.
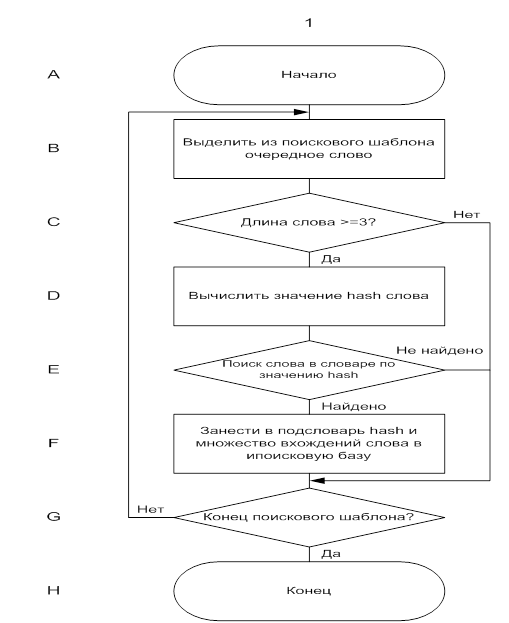
Рис. 10. Построение подсловаря из поискового запроса
Анализируя цепочки слов, важно выделить величины, участвующие в процессе их формирования. Речь о них велась выше, но все же акцентируем внимание. Такими величинами являются:
множество вхождений каждого слова в поисковую базу;
позиции конца слов;
расстояния слов относительно друг друга.
Для наглядности, представим множество этих параметров в виде графа, который будет являться отображением искомых словарных цепочек, образующих домены. Домены же, в свою очередь, определяют содержимое результата на выходе работы алгоритма.
Из теории графов известно, что граф — это совокупность объектов со связями между ними. Тогда объекты представляются как вершины или узлы графа, а связи — как дуги, или рёбра. Применительно к нашему подходу вершинами V графа будет являться множество позиций (смещений) слов запроса в информационной базе, а ребрами Е, в свою очередь, расстояния позиций разных слов относительно друг друга.
Для более подробного рассмотрения, обратимся к рисунку 11 и
дадим необходимые пояснения. Как видно из рисунка, множество овальных объектов
представляет собой множество всех позиций каждого слова запроса. Например,
элемент ![]() обозначает
одно слово запроса с позицией вхождения в поисковую базу равной 5 и позицией
конца равной 9, высчитываемой на основании его длины. Все смещения одного слова
W находятся на одном уровне (строке) L, составляемом по
хеш-значению каждого слова, которое хранится в подсловаре.
обозначает
одно слово запроса с позицией вхождения в поисковую базу равной 5 и позицией
конца равной 9, высчитываемой на основании его длины. Все смещения одного слова
W находятся на одном уровне (строке) L, составляемом по
хеш-значению каждого слова, которое хранится в подсловаре.
Для удобства каждый уровень обозначим, как Hash(W1), Hash(W2) и т.д. На каждом уровне приведена длина соответствующего слова: Length W1 = 4, Length W2 = 8 и т.д. Все позиции одного слова расположены в порядке их возрастания, например для первого слова: 5-9, 55-59, 112-116, 289-293. Последовательность уровней определяется порядком слов в поисковом шаблоне.
Связь двух элементов на соседних уровнях изображается, как ![]() и обозначает модуль
разности между концом первого слова и начало второго, в данном примере
равный 78.
и обозначает модуль
разности между концом первого слова и начало второго, в данном примере
равный 78.
Установленный флаг ![]() запрещает использование соответствующего
элемента для последующего построения новой цепочки.
запрещает использование соответствующего
элемента для последующего построения новой цепочки.
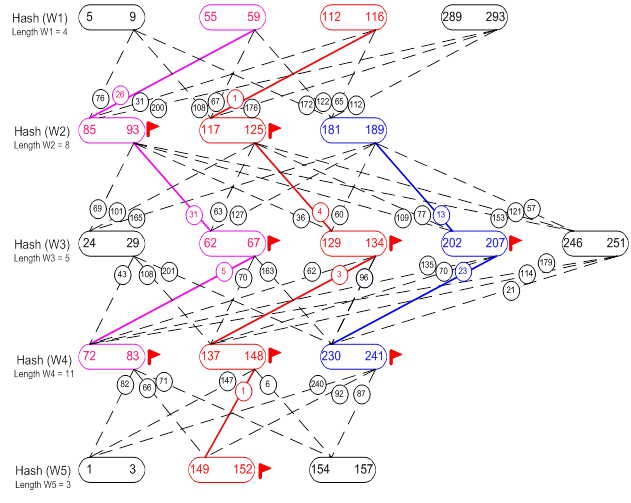
Рис. 11. Построение цепочек подсловаря
Рассмотрим последовательность действий при составлении словарных цепочек, пользуясь рисунком 11. Блок-схема работы алгоритма приведена на рисунке 12.
Для облегчения понимания процесса будем считать, что поисковая база имеет длину 300 символов. Это означает, что все смещения слов лежат в пределах от 1 до 300 включительно. В качестве используемых символов берутся все печатаемые символы кодовой таблицы ASCII: любая буква алфавита, строчная и заглавная, знаки препинания, скобки, кавычки, пробельный символ, все цифры от 0 до 9, специальные символы «-», «\», «/», «’», «”», «№» и т.д. Введем величину Lim обозначающую максимально возможную удаленность двух слов друг от друга в пределах которой мы будем продолжать рассмотрение элемента для построения цепочки. Пусть значение Lim для данного примера будет равно 60.
Начнем работу с первой вершины первого уровня. Заносим в цепочку в качестве первого элемента вершину 5-9, обозначим ее Vs. Запоминаем текущий уровень Hash (W1), обозначим его Lc. Теперь нам нужно выяснить, какая из вершин второго уровня находится ближе всего к вершине 5-9. Для этого, во-первых, приравняем нулю некоторую переменную Еmin. Еmin будет хранить текущую минимальную длину ребра. Во-вторых, вычислим длины ребер между вершиной 5-9 и всеми незанятыми (не помеченными флагом) вершинами Vn (следующий) второго уровня Hash (W2): 85-93, 117-125, 191-199. Назовем эту операцию прямой расчет. При прямом расчете будет вычисляться расстояние между элементом текущего уровня и всеми элементами нижеследующего уровня. Минимальную длину ребра сохраняем в Emin, после чего проверяем, не равно ли Emin 0. Т.е. нашлись ли такие позиции слова второго уровня, которые бы были удалены от позиции 5-9 - слова первого уровня, не более чем на Lim. Если таких позиций нет, то смотрим, сколько элементов уже занесено в цепочку. Если занесен один элемент, то удаляем его и проверяем, остались ли на текущем уровне еще вершины. Если элементов больше одного, то сразу переходим к проверке. Если Emin не равно 0, то заносим в цепочку вершину следующего за текущим уровня такую, которая соответствует минимальному ребру. Назовем ее Vnmin. Для нашего примера это будет вершина 85-93. Пометим Vnmin флагом занятости для того, чтоб уже не использовать ее при построении других цепочек. Теперь нам необходимо произвести расчет, позволяющий выявить вершину первого уровня, расположенную на максимально близком расстоянии к найденной вершине второго уровня Vnmin. Назовем такой расчет обратным. В ходе обратного расчета будем искать ребро минимальной длины между элементом 85-93 Vnmin (Hash (W2)) и всеми элементами Hash(W1): 55-59, 112-116, 289-293, за исключением уже рассмотренной вершины 5-9. Необходимость прямого и обратного расчета в алгоритме построения домен образующих цепочек обуславливается следующими соображениями.
Во-первых, обратный расчет, применяемый только для нахождения первых двух элементов цепочки, дает нам возможность отыскать устойчивое словосочетание, являющееся основой последующего построения (развития) цепочки. В нашем примере видно, что для элемента второго уровня 85-93 ближайшим будет элемент первого уровня 55-59, найденный в процессе обратного расчета. Следовательно, мы исключаем из цепочки первый элемент 5-9 Vs, заменив его на элемент 55-59 Vp, и меняем текущий уровень Lc на следующий Lc+1 , т.е. тот, где расположен элемент Vnmin и, если он не является последним, повторяем цикл прямого расчета .
Отметим еще раз, что замена возможна только при условии, что найдется элемент Vp, расположенный ближе к Vnmin, чем Vs и находящийся в пределах Lim.
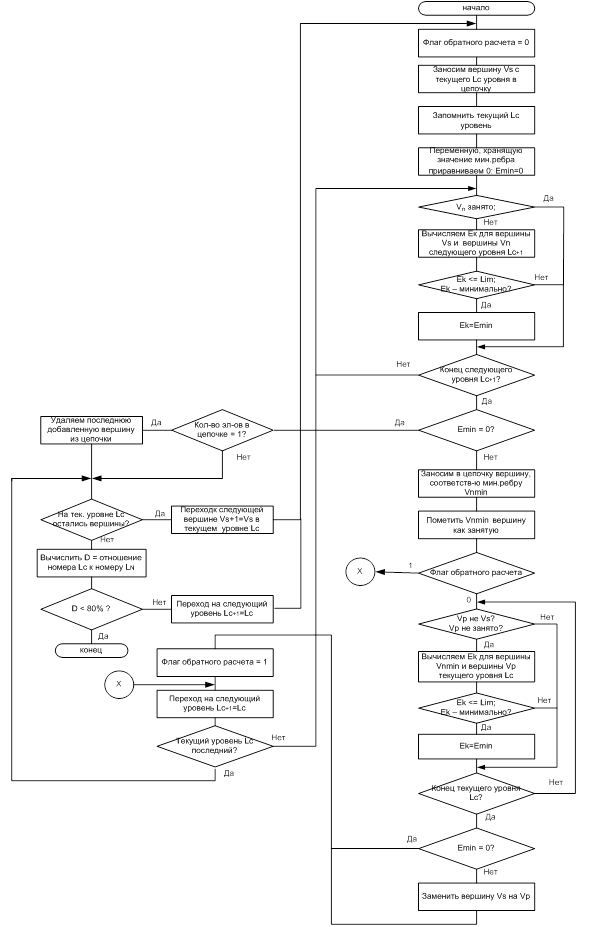
Рис. 12. Блок схема алгоритма построения словарных цепочек
Во-вторых, данное действие, дает возможность проставления флагов занятости на всех элементах цепочки, начиная со второго, что позволяет нам в значительной степени сократить количество цепочек путем запрета построения таких цепочек, которые бы являлись частями уже построенных цепочек. Это возможно ввиду того, что данный алгоритм предполагает построение словарных цепочек, начиная с элементов не только первого, но и нижележащих уровней таких, для которых сохраняется условие D ≥ 80%, где D – отношение текущего уровня Lc к номеру последнего уровня LN, определяемого общим количеством слов шаблона N.
Таким образом, предположив отсутствие операции обратного расчета на первом шаге построения цепочки, кроме того, что мы лишаемся возможности проставления флагов занятости и при значительном объеме словаря (сотни и тысячи Мб), получаем комбинаторный взрыв частично дублирующих друг друга цепочек.
Если при отыскании первого и второго элемента исключить операцию прямого расчета, то можно столкнуться с ситуацией, когда останутся вершины первого уровня полностью исключенные из общих расчетов. Вследствие этого, прямой расчет на первом шаге построения цепочек так же необходим и первый элемент любой цепочки не помечается флагом занятости.
Применять обратный расчет при обработке остальных элементов цепочки, начиная с третьего, нецелесообразно. Объясняется это тем, что, как было указанно выше, все смещения одного слова расположены в порядке их возрастания и для всего множества позиций (смещений) одного слова можно выделить некоторые интервалы в пределах которых будут располагаться все позиции всех слов. Для нашего случая, в качестве примера, можно выделить интервалы с 1 по 100 символ, с 101 по 200 и с 201 по 300.
Следует отметить, что флаг обратного расчета дает возможность отследить, какой по порядку элемент цепочки мы ищем, и включить, либо исключить операцию обратного расчета. Т.е. при поиске первого и второго элемента цепочки флаг равен нулю и мы производим обратный расчет, а при поиске третьего и последующих элементов цепочки значение флага меняется на 1 и обратный расчет не производится.
Построение новых цепочек ведется сначала от элементов первого уровня, следующих по порядку за первым элементов, потом, как было выше указано, от всех не занятых в построении других цепочек элементов нижних уровней, для которых D ≥ 80%.
В конечном итоге, мы получим множество цепочек, которые не будут дублировать друг друга ни полностью, ни частично. Кроме того, важно еще раз отметить, что любая цепочка может начинаться с любого уровня, для которого D ≥ 80%, и заканчиваться на любом уровне, а вводимый поисковый шаблон можно так же представить в виде цепочки слов, расстояние между которыми будет минимально.
Таким образом, получено множество домен образующих цепочек слов, пригодное для дальнейшей оценки релевантности при разработке прикладного программного обеспечения.
5.3 Проверка метода
Экспериментальная проверка предложенного метода была проведена на примере исследования раздела административного права, экспортированного из информационно - правовой системы «Консультант+» на персональном компьютере класса Intel Core i5 2.5 RAM 8.0. Эксперимент показал как работоспособность метода, так и вполне приемлемые для практики временные параметры, лежащие в 30 секундном диапазоне обработки запроса на подборку документов при заданном значении релевантности. В качестве образцов поискового шаблона использовались документы размером в 1-2 страницы текста [14]. Детальные пояснения используемых при программной реализации метода структур данных и методов оптимизации временных параметров выходят за рамки настоящей статьи и достойны отдельной публикации.
6. Практическая реализация
Для вышеуказанного метода было разработано прикладное программное обеспечение специального назначения,
Практическая реализация предложенного метода защищена Свидетельствами Государственной Регистрации Программ [15,16,17,18,19] и частично изложена в работах [9,14].
7. Заключение
В настоящее время задача разработки методов поиска, реализуемых в информационно-поисковых системах, является актуальной. Для ее решения был предложен оригинальный метод, в котором понятие «сравнение» сводится к отысканию документов, находящихся в информационно-поисковой базе, части которых, в той или иной мере, визуально сходны с исходным поисковым шаблоном.
В основу предлагаемого метода положено предположение о том, что сходство документов определяется близостью изображений страниц их текстов, причем без проведения семантического исследования их содержания. В результате, размерность решаемой задачи снижается на несколько порядков и попадает в сферу возможного для общедоступных средств вычислительной техники (персональных компьютеров). Снижение размерности задачи достигается путем рассмотрения текстов документов поисковой базы как ряда своеобразных графических изображений, в которых пикселем является слово документа. Таким образом, в предложенном методе, в качестве результата сравнения рассматривается совокупность совпадений слов в исследуемом тексте документа из поисковой базы и в поисковом шаблоне с учетом их взаимного расположения или «геометрической близости».
Для алгоритмической реализации предложенного метода ключевыми моментами являются построение цепочек совпадений образующих домен, плотность которого является мерой релевантности, а так же поисковые словари, необходимые для построения цепочек совпадений образующих домен.
Таким образом, в рамках настоящей работы, для решения задачи сравнения текстов нормативно-правового характера произведено построение поискового словаря, подсловаря - несущих информацию о расположении совпадающих слов в тексте, и домен образующих цепочек. Это позволило получить множество домен образующих цепочек слов, пригодное для дальнейшей количественной оценки релевантности.
Список литературы
1. C. J. Van Rijsbergen. -Dept. of Computer Science, University of Glasgow. Newton MA, USA : Butterworth-Heinemann, 1979.-208 pages.
2. Маннинг К.Д., Рагхаван П., Шютце Х. Введение в информационный поиск. – М.; Вильямс, 2013. – 528 с.
3. Электронный журнал «Спамтест». 2013. № 27 – Электронный ресурс URL: http://subscribe.ru/archive/inet.safety.spamtest/200312/02121841.html (да-та обращения: 25.11.13).
4. Поиск нечетких дубликатов. Алгоритм шинглов для веб-документов – Электронный ресурс URL: http://habrahabr.ru/post/65944/ (дата обращения: 25.11.13).
5. MinHash – выявляем похожие множества – Электронный ресурс URL: http://habrahabr.ru/post/115147/ (дата обращения: 27.11.13).
6. Семантическая сеть – Электронный ресурс URL: http://ru.wikipedia.org/wiki/Семантическая_сеть (дата обращения: 20.12.13).
7. Грахам А. Анализ строк. Перевод Галкиной под редакцией П.Н. Дубнера М: 2000 – 315 с.
8. Новиков Г.Г., Графический подход к проблеме нечеткого поиска фрагмента текста. - Научная сессия МИФИ 2010, сборник научных трудов. Том 3, 2010 г. С. 32 – 32.
9. Новиков Г.Г., Идентификация личности в условиях реального времени. - Научная сессия МИФИ 2006, сборник научных трудов. Том 12, 2006 г. С. 56 – 62.
10. Новиков Г.Г., Выбор метрики для нечеткого поиска в структурированной информации. - Научная сессия МИФИ 2007, сборник научных трудов. Том 12, 2007 г. С. 126 – 127.
11. Новиков Г.Г., Геометрический подход к задаче нечеткого полнотекстового поиска. - Научная сессия МИФИ 2013, аннотации докладов. 2013 г. С. 10 – 10.
12. Гуров В.В., Гуров Д.В., Новиков Г.Г. Разработка методики обучения безопасному программированию. - Безопасность информационных технологий. №1, 2012 г, С. 91 – 93.
13. Александрович А.Е., Новиков Г.Г., Чуканов В.О., Ядыкин И.М. Обеспечение функциональной безопасности специализированных ЭВМ с комбинированным резервированием по контрольным точкам. - Безопасность информационных технологий. №1, 2012 г. С. 75 – 77.
14. Новиков Г.Г. Ядыкин И.М. Геометрический подход к проблеме нечеткого поиска фрагмента текста в контуре информационной безопасности предприятия. Безопасность информационных технологий. №4, 2014 г., С. 83-85
15. Новиков Г.Г. Ядыкин И.М. Программа вычисления функции релевантности для нечеткого полнотекстового поиска, реализующая геометрический подход. Свидетельство о государственной регистрации. №2014660638Бюллетень №4 2014 г.
16. Новиков Г.Г. Ядыкин И.М. Программа автоматической транслитерации для фамильно-именных групп во французской, английской и латинской нотации. Свидетельство о государственной регистрации №2013618048 Бюллетень №3 2013 г.
17. Новиков Г.Г. Ядыкин И.М. Программа нечеткого поиска в базах имен и фамилий. Свидетельство о государственной регистрации №2013662371. Бюллетень №3 2014 г.
18. Новиков Г.Г. Ядыкин И.М. Программа определения степени визуальной постраничной релевантности текста, реализующая метод заметающей кривой. Свидетельство о государственной регистрации №2014660638 Бюллетень №4 2014 г.
19. Новиков Г.Г. Ядыкин И.М. Программа определения степени подобия текстов, реализующая метод семантической нормализации. Свидетельство о государственной регистрации №2014660502. Бюллетень №4 2014 г.
GRAPHICAL APPROACH TO THE PROBLEM OF FINDING SIMILAR TEXTS
V.L. Yevseyev, G.G. Novikov
National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation
VLEvseev@mephi.ru, GGNovikov@mephi.ru
Abstract
This work is devoted to one of the possible approaches to the development of a system comparing texts encountered in solving the problem of comparing texts regulatory developments.
The proposed method allows to find regulatory documents, fragments of which are similar to the query entered by the user. The analysis of the state of developments in the field of fuzzy full-text search, which implies that it is possible to allocate the following search methods implemented in a retrieval system of different types: information retrieval systems and data retrieval.
For solving the problem of text search by similarity, introduced the concept of "comparison", which boils down to finding documents in information retrieval database, which to some extent is similar to the original search pattern. The basis of the proposed method based on a assumption that the similarity of documents is determined by the closeness of their images in the form of texts without performing semantic study of their content. As a result, the dimension of the tasks is reduced by several orders of magnitude and enters the realm of the possible for a public computer equipment (personal computers). Developed the overall structure of the search algorithm. To solve the problem of searching for similar texts built search dictionary, podlogar and the domain forming chains in the problem of fuzzy full-text search. This allowed to get a set of domain forming chains of words suitable to assess the relevance of the investigated text search template.
Keywords:
Comparison of texts, text similarity search, query language, the search pattern, the search base, relevance, search algorithm, search the dictionary sub-vocabulary.
References
- C. J. Van Rijsbergen. -Dept. of Computer Science, University of Glasgow. Newton MA, USA : Butterworth-Heinemann, 1979.-208 pages.
- K. D. Manning, P. Raghavan, H. schütze Vvedenie v informacionnyj poisk [Introduction to information retrieval]. - M.; Williams, 2013. - 528 p.
- Electronic journal "Spamtest". 2013. No. 27 - Electronic resource URL: http://subscribe.ru/archive/inet.safety.spamtest/200312/02121841.html (date of access: 25.11.13).
- Poisk nechetkih dublikatov. Algoritm shinglov dlja veb-dokumentov. [Search for fuzzy duplicates. The algorithm shingles for web documents] - Electronic resource URL: http://habrahabr.ru/post/65944/ (date of access: 25.11.13).
- MinHash – vyjavljaem pohozhie mnozhestva [MinHash - identify similar sets]. Electronic resource URL: http://habrahabr.ru/post/115147/ (date of access: 27.11.13).
- Semanticheskaja set' [Semantic network] - Electronic resource URL: http://ru.wikipedia.org/wiki/Семантическая_сеть (date of access: 20.12.13).
- Graham A. Analiz strok [Analysis of strings]. Translation Galkina, edited by P. N. Dubner M: 2000 - 315 p.
- Novikov G. G., Graficheskij podhod k probleme nechetkogo poiska fragmenta teksta [Graphical approach to the problem of fuzzy search text]. - Scientific session MEPhI 2010, collection of scientific papers. Volume 3, 2010 p. 32 - 32.
- Novikov G. G., Identifikacija lichnosti v uslovijah real'nogo vremeni [Identification of a person in real time]. - Scientific session MEPhI 2006, collection of scientific papers. Volume 12, 2006, p. 56 - 62.
- Novikov G. G., Vybor metriki dlja nechetkogo poiska v strukturirovannoj informacii [the Choice of metrics for fuzzy search in structured information]. - Scientific session MEPhI 2007, collection of scientific papers. Volume 12, 2007, p. 126 - 127.
- Novikov G.G., Geometricheskij podhod k zadache nechetkogo polnotekstovogo poiska [Geometric approach to the problem of fuzzy full-text search]. - Scientific session MEPhI 2013, abstracts. 2013 p. 10 - 10.
- Gurov V.V., Gurov, D.V., Novikov G.G. Razrabotka metodiki obuchenija bezopasnomu programmirovaniju [The Development of teaching secure programming]. - Safety of information technology. No. 1, 2012, p. 91 - 93.
- Aleksandrovich A.E., Novikov G.G., Chukanov, V.O., Yadykin I.M. Obespechenie funkcional'noj bezopasnosti specializirovannyh JeVM s kombinirovannym rezervirovaniem po kontrol'nym tochkam [The functional safety of specialized computers with a combined booking at check points]. - Safety of information technology. No. 1, 2012, p. 75 - 77.
- Novikov G.G., Yadykin I.M. Geometricheskij podhod k probleme nechetkogo poiska fragmenta teksta v konture informacionnoj bezopasnosti predprijatija. Bezopasnost' informacionnyh tehnologij [Geometric approach to the problem of fuzzy search text in the outline information security company]. Security of information technologies. №4, 2014, p. 83-85.
- Novikov G.G., Yadykin I.M. Program function evaluation relevance fuzzy full-text search, which implements a geometric approach. The certificate of state registration. No. ITN No. 4 2014
- Novikov G.G., Yadykin I.M. Program automatic transliteration for family-registered groups in French, English and Latin notation. The certificate of state registration №2013618048 Bulletin No. 3 2013
- Novikov G.G., Yadykin I.M. Program fuzzy search in the databases of names and surnames. The certificate of state registration №2013662371. Bulletin No. 3 2014
- Novikov G.G., Yadykin I.M. Program to determine the degree of visual paging relevance of the text for realizing the method zametaya curve. The certificate of state registration №2014660638 Bulletin No. 4 2014
- Novikov G.G., Yadykin I.M. the Program determine the similarity of texts that implements the method of semantic normalization. The certificate of state registration №2014660502. Bulletin No. 4 2014