GRAPHICAL APPROACH TO THE PROBLEM OF FINDING SIMILAR TEXTS
V.L. Yevseyev, G.G. Novikov
National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation
VLEvseev@mephi.ru, GGNovikov@mephi.ru
Contest
2. Analysis of the current state of development
4. The base concept of the proposed method
5. General review of the search algorithm.
5.1 Building a search dictionary and domain forming chains
5.2 Build Chain of words forming the domain
Abstract
This work is devoted to one of the possible approaches to the development of a system comparing texts encountered in solving the problem of comparing texts regulatory developments.
The proposed method allows to find regulatory documents, fragments of which are similar to the query entered by the user. The analysis of the state of developments in the field of fuzzy full-text search, which implies that it is possible to allocate the following search methods implemented in a retrieval system of different types: information retrieval systems and data retrieval.
For solving the problem of text search by similarity, introduced the concept of "comparison", which boils down to finding documents in information retrieval database, which to some extent is similar to the original search pattern. The basis of the proposed method based on a assumption that the similarity of documents is determined by the closeness of their images in the form of texts without performing semantic study of their content. As a result, the dimension of the tasks is reduced by several orders of magnitude and enters the realm of the possible for a public computer equipment (personal computers). Developed the overall structure of the search algorithm. To solve the problem of searching for similar texts built search dictionary, podlogar and the domain forming chains in the problem of fuzzy full-text search. This allowed to get a set of domain forming chains of words suitable to assess the relevance of the investigated text search template.
Keywords: A comparison of texts, text similarity search, query language, the search pattern, the search base, relevance, search algorithm, search dictionary, sub-vocabulary, fuzzy search.
1. Introduction
Necessity and urgency of developing a method of comparing the texts associated with the presence of modern legal basis of a large number of documents, especially taken in USSR to Russia transfer period, regulating the same relationship in different ways, and often contradictory. This creates difficulties in their classification and codification. In the proposed method comparing texts aim is not search for a specific piece of text or keyword - this is a typical problem of search engines, but pre-sorting documents on the degree of similarity to each other for further peer review. This significantly reduces the requirements for the basic characteristics of personal computers used to achieve the above goals. This paper proposes one approach to solving this problem by simulating a quick visual document viewing by human. With this, the text is not perceived as an object for reading, but rather as an image that subconsciously compared with an imaginary reference.
2. Analysis of the current state of development
Analysis of the state of developments in the field of fuzzy full text search shows that we can identify the following search methods implemented in a different types of retrieval system: information retrieval systems and data retrieval.
One of the most fundamental review of information search and information retrieval systems is presented in [1, 2]. In what follows we use the terminology adopted in these studies.
Currently, information systems, working with electronic text documents, conventionally divided into two categories: information retrieval systems and data retrieval system. This classification is arbitrary and in its context, many modern information systems combine the properties of both systems, data retrieval, and information retrieval systems. Basic differences are presented in Table 1.
Table 1 – Data and Information retrieval systems differences.
|
|
Data |
Information |
|
Compliance with these search query |
strict |
partial |
|
Documents classification |
deterministic |
probabilistic |
|
query language |
artificial |
natural |
|
Criteria for documents retrival |
Boolean relevance function |
Probability relevance function |
|
Stability data errors and requests |
unstable |
stable |
A typical example of data retrieval systems are classic relational database management system (DBMS), where a particular dialect query language SQL is used as the query language. This language is artificial and allows you to specify search queries only to find an exact match or to search for a given pattern. In modern systems, data retrieval main task is to provide a high speed of search queries, as well as reliable and efficient data storage. In turn, information retrieval systems are designed to solve the more general problem of finding than the search for an exact match, where the ultimate goal is to choose a search relevant to the search query information, the degree of relevance which can be defined as the degree of its proximity to the semantic search query. This in turn leads to that queries in such systems must be based on natural language, i.e. in the same language in which formulated the initial information. Of the sample data and information - search engines work with a collection of documents. The initial collection of documents can be viewed as a list of records (documents), where each record contains a list of some words consisting of alphanumeric characters. In real-world information systems in the original set of documents may contain additional information describing the documents, which can also be used for search.
The closest in meaning to the task are fuzzy search methods frequently used text snippets in solving the problem Antiplagiat [3]. Of these, the most well-known and widely used method is used Shingles, MinHash, Semantic Networks and a number of other.
Shingles.
The algorithm is often used for web documents and is used to combat online plagiarism.
Main steps:
1. Deformatting of the text.
Includes clean text formatting and bringing it to a normal form by means of exclusion prepositions, conjunctions, punctuation, formatting Web (HTML-tags). Sometimes deleted adjectives.
2. Splitting into shingles (Figure 1).
To highlight the text of shingles is first determined by the length of sequences of words the shingle is. Most often, the length of the shingles is around 2-8 words. Sequences of words are not taken joint to joint and overlapping, for example, the sentence "The cat wanted to jump on a chair, but missed," after the first stage will look like a "cat wanted to jump chair missed", and after partitioning shingles (Take the size of shingles - 3 words ) as follows: {cat wanted to jump; wanted to jump on a chair; chair missed} or so {cat wanted to jump; wanted to jump on a chair; jump chair missed}. That is, the overlap can be equal as one word, and a greater number of words [4].
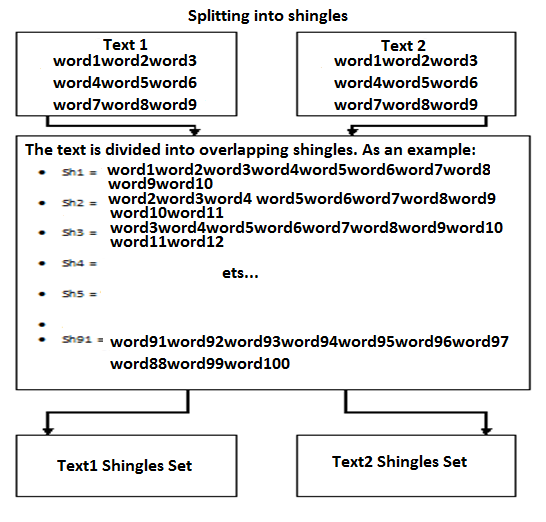
Fig. 1. Partitioning for shingles
3. W-shingling (hashes shingles, a random sample of checksums, comparison and determination result).It is necessary for each shingle to calculate the checksum. Is commonly used hashing algorithm. Calculated for each shingle 84 checksum value through the different functions (eg SHA1, MD5, CRC32, etc., only 84 functions). Thus, each of the texts will be presented in the form of two-dimensional array of 84 x rows, where each row describes a corresponding one of the 84's checksum functions (Figure 2). From these sets will be randomly selected 84 values for each of the texts and compared with each other according to the checksum function, through which each of them was calculated (Figure 3). Thus, it will be necessary to perform a comparison of 84 operations.
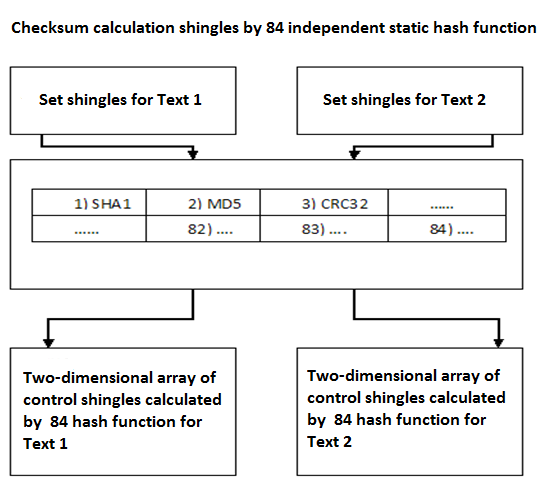
Fig. 2. Shingles checksum calculation
Further sampling is performed checksums on some basis - divided into one number, even, odd etc... This is to ensure that the values in the sample, were evenly distributed in the text. For example, choosing the most minimum value of each line.
Then the output of the set have a minimum shingles checksum values for each of the hash functions.
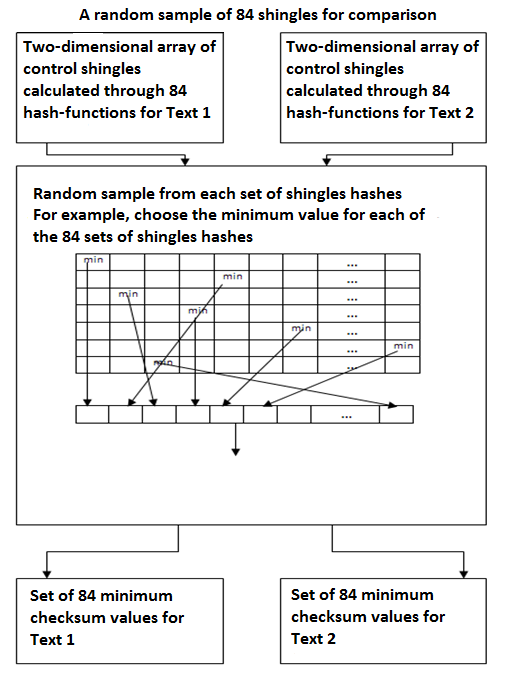
Fig. 3. A random sample of 84 shingles for comparison
Samples are then compared the two texts and to determine the degree of similarity of texts see (Figure 4).

Fig. 4. Comparison of the corresponding elements of arrays
It should be noted that at the current time apply advanced algorithms duplicates. For example, an alternative algorithm for near-duplicate detection has been created and developed in Yandex - SuperShingl method [4].
3. SuperShingl method.
Constructed a limited set of checksums. Over 84 built Shingle 6 SuperShingl (14 shingles). Text is coincident with the concurrence of at least two SuperShingl 6.
MegaShingl.
In practice, the method SuperShingl demonstrated that for near-duplicate detection missing at least two matches SuperShingl. This means that in order to best match a minimum of two SuperShingl, the document must be submitted to different pairing of 6 SuperShingl. Such groups are called MegaShingl. According to this method to identify duplicate documents are identical to each other, if they have the same least one MegaShingl.
MinHash method.
The idea of this algorithm is to calculate the probability of equality minimum hash value sets of elements. The method is based Jaccard coefficient
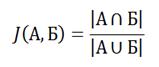 (1)
(1)
where A and B - the sets of elements compared.
That is, the Jaccard coefficient - the number of elements in the intersection, divided by the number of elements in the association. This ratio is equal to zero when the sets have no common elements, and one when the sets are equal, but in other cases the value somewhere in the middle [5].
It is necessary to find the intersection and combining data sets. In practice, for the effective performance of the last two operations, the sets are in a hash table without associated with key values. As a result, the operation is performed 4: construction of two tables (when comparing two texts), the definition and determination of the intersection of association.
The key idea of the algorithm is as follows. Suppose there are two sets M1, M2, and the hash function h, which is able to calculate the hashes for the elements of these sets. Next, determine the function hmin (S), which computes the function h for all members of a set S and returns the smallest of its value. Then variables (1) have the following meanings: A = hmin (M1), B = hmin (M2).
The difficulty lies in the fact that if we simply calculate the hmin (M1) and hmin (M2) for our two pieces of text, and then compare the values, then it will not work, because only two options - are equal or unequal. Here it is necessary to obtain a sufficient volume of statistics on our sets and compute the closest to the truth J (M1, M2). And for this purpose instead of one function h introduce several independent hash functions, but rather functions k:
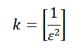 (2)
(2)
where ε - the desired maximum value of the error.
For example, to calculate J(M1, M2) with the error not more than 0.1, must have 100 hash functions. This algorithm is usually used for building services recommendation.
Methods using semantic networks.
Semantic Network - information domain model, having the form of a directed graph, whose nodes correspond to the domain objects and the arcs define the relationship between them. The Semantic Web is one of the ways of knowledge representation (Figure 5).
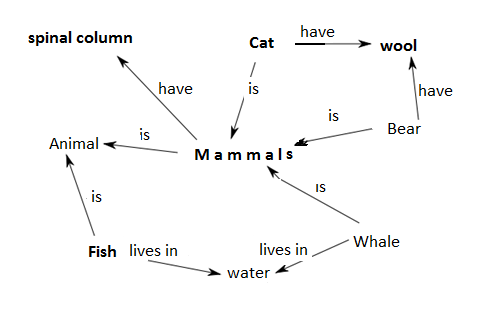
Fig. 5. Example of a Semantic Network
In linguistics relations are fixed in dictionaries and thesauri. The dictionary definitions by genus and species unlike the generic concept occupies a certain place. In thesauri in the article of each term may be listed all the possible links with other related on terms. From these thesauri must be distinguished thesauri information retrieval with lists of keywords in articles that are designed to work descriptor search engines [6]. The task of determining the borrowing is reduced compared to models that reflect the meaning of texts. The analysis is carried out using graph algorithms, modified and optimized for use within a given task. Use of the data analysis scheme in this method may allow to detect drawing fact, even if the original has been modified in a certain way (translation is made, the words are replaced by synonyms text was described using a different language etc.).
A more detailed analysis of the current state of development of information retrieval systems that goes beyond the scope of this paper shows that none of the currently known methods is not directly suitable for the solution of our problem.
Based on the foregoing, we propose a method for solving the problem of text similarity search simulating inherently a process of text skimming by human person in order to determine the visual similarity of the pages you are viewing the text without reading and understanding a semantic component.
4. The base concept of the proposed method
The basis of the proposed method on the assumption that the similarity of documents determined by the proximity of their images in the form of texts without a semantic study of their content. Thus, the dimension of the problem to be solved is reduced by several orders of magnitude, and falls within the scope of opportunities for public computer equipment (personal computers). Reducing the dimension of the problem is achieved by considering the texts searchable database as a number of original graphics, in which a pixel is the word of document. Thus, as a result of the comparison set of matches will be considered in the test words from the document database, and the search template with regard to their mutual arrangement or "geometric proximity".
Place in the text, where the words match the desired pattern with the words of the text, we will call “domain” consisting of chains of coincidences. The main quantitative characteristic of the similarity of the test text, and a search pattern, we assume the relevance of that in our approach we assume is determined by:
1. the number of words the search pattern contained in the
domain
Qnt (- quantity);
2. distance caught in the domain words in relation to each other are their overall density Qlt (- quality).
Under this approach, define them as Quantitative and Qualitative parameters of relevance respectively.
The contributions of these parameters to the Relevance Function is not the same and linear, however generally relevant R can be described by the function (3) determining the contribution of each of these components.
R = F (Qnt, Qlt) (3)
Form of the function may be different, and it is for further study, but it is clear that the value of the function of the search results domain to the search pattern must be in range from 0 (no match) to 1 (complete coincidence), Figures 6, 7 8 illustrate the suggested consideration of textual information.
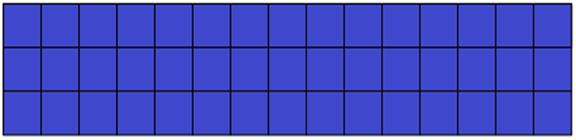
Fig. 6. The search template
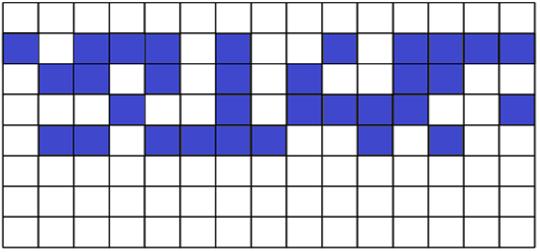
Fig. 7. Vocabulary domain with high relevance value
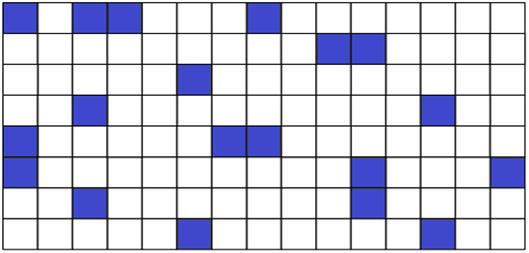
Fig. 8. Vocabulary domain with low relevance value
Figure 6 is a graphical representation of the search pattern, each of the words that can participate in the formation of lexical chains constituting the domain. One square image corresponds to one word query.
Figures 7 and 8 show how the can be geometrically arranged word search pattern (blue squares) in the comparison of the similarity of the document fragment. Once again, we should note that in this approach the analysis of the test document are not in terms of its semantic content, but only from the standpoint of its vocabulary.
In Figure 7 the number and density of the words, which are colored blue, is higher than in the example illustrated in Figure 8. Consequently, the relevance value corresponding to figure 7, greater relevance value corresponding to figure 8.
5. General review of the search algorithm.
For the further development of the proposed method is necessary to determine the general structure of the search algorithm in the first place with the method that will identify the main factor - Match the words and text template from the database. Search methods currently developed many [7], however, the most preferred are the ideas underlying the methods of vocabulary similarity search [8].
Functionally, the algorithm comprises the preliminary design searchable database, as follows:
index creation, conventionally called a dictionary;
Preparation of requests by creating an index called sub-vocabulary;
procedures for constructing chains of word domain;
Numerical estimates of relevancy.
5.1 Building a search dictionary and domain forming chains
Consider one of the most specific preparatory steps in solving the problem of finding similar texts - the construction of exploratory dictionary - an index designed to provide a quick search of similar words in the domain. A geometric approach to the determination of the similarity of texts discussed in detail in [8, 9, 10, 11], is the basis for this development. Use the concepts and terminology database defined in [1, 2, 7, 12, 13].
In the begin of the algorithm information contained in a dictionary, is formed by search engine treating the input base. In view of the fact that the main thrust of this work is to develop method of text search, instead of the maximum efficiency of its implementation, for searchable database file was selected as ASCII format plain text.
Entries that are used in the construction the dictionary search strings are the point of interest. They are calculated for each word in database having a length equal to or greater than 3 symbols and then sequentially recorded in the dictionary. That is, for each word are stored:
the hash value of the word;
the point of occurrence of the word in a searchable database;
word length.
Hash value - is used to identify each individual and used as a word index is compact, by which information is extracted for each set of offsets from the beginning of the search word database. The fact that the same word may occur more than once as a single document, and throughout the search database. This approach is due to the convenience of the physical organization of the dictionary as a hash table. Points of occurrences of words in a searchable database, that is offset from its beginning and length required to calculate distances between words. The procedure described in the framework of this step can be seen in Figure 9.
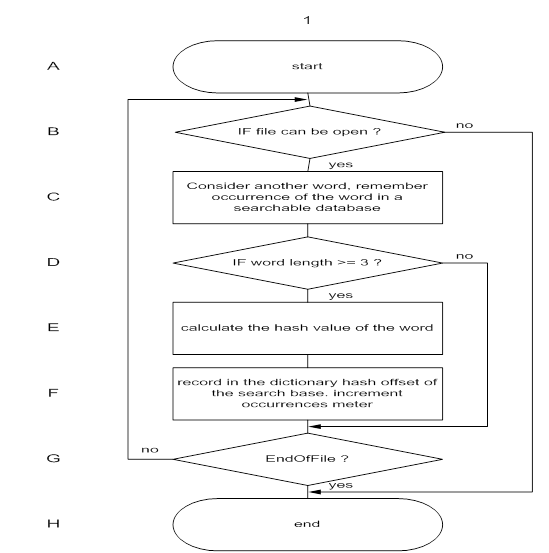
Fig. 9. Creating a search dictionary
In the second step is entered initial search template and build its image in a form similar to the representation of the dictionary search base. We call this image Sub-Dictionary. Because of the importance of this process in the future, it should again be emphasized that the content of sub-dictionary is determined by the vocabulary of the introduction of a search pattern, and its structure is similar to existing available dictionaries created by processing the search base. This means that the sub-vocabulary, as well as in a dictionary, containing:
-hash value of each word search template;
-the set of its occurrences in a searchable database;
-its length.
Constructing of a sub-dictionary is shown in Figure 10. It should be noted that the sub-dictionary is based on the already formed the dictionary, the latter two items are retrieved from the dictionary in the sub- dictionary for the hash value of the word. When building sub- dictionary not taken into account with the words of less than three characters.
5.2 Build Chain of words forming the domain
One of the most important parts of the search algorithm is to build a chain of words that make up the vocabulary of the domain. The process according to the above general concept implies finding in the search database query words located as close to each other. The proximity of words is calculated as the absolute difference of positions beginning of one word and the position of the end of the preceding another word. Strings of words are built only by those words, information is stored in the sub-dictionary.
It should be noted that the position of beginning of the word is calculated as the offset relative to the beginning of the search word database, and the end - using word length that is stored in the sub-dictionary, i. e. position of occurrences of the word in the database plus the length of the words in characters.
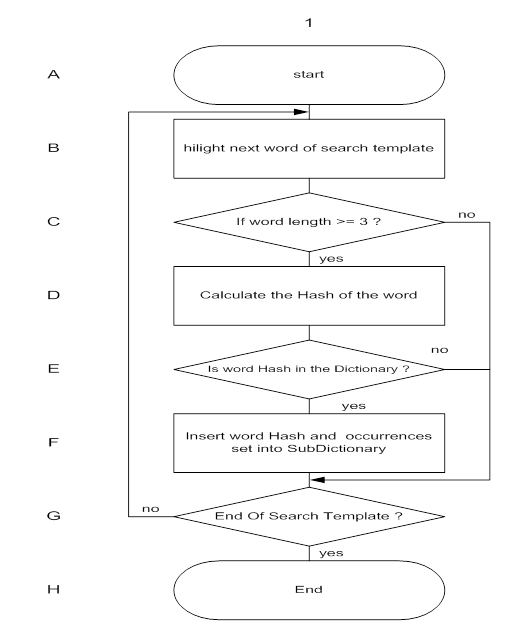
Fig. 10. Building a sub-dictionary
Analyzing strings of words, it is important to highlight the value of participating in the process of their formation. It was carried out above them, but still emphasize. These values are:
the set of occurrences of each word in a searchable database;
position at the end of words;
distance words to each other.
For clarity, we represent the set of these parameters in the form of a graph, which will be the display of the required chains of matched words forming domains.
Domains characteristics determine the value of the result at the output.
From graph theory known that graph - a collection of objects with links between them. Then the objects are represented as nodes in the graph, and communications - as arcs. With respect to our approach graph nodes V will be a plurality of positions (displacements) of query words in the information database, and the arcs E different distance positions relative to the words of each other.
For a more detailed discussion, refer to 11 and give the
necessary explanations. As can be seen from the figure, a plurality of ellipse
is the set of all positions of each word in a query. For example, the element ![]() represents a
single word query with the position of entry into a searchable database of 5
and the position of the end of 9, is calculated on the basis of its length. All
offset one word W are on the same level (row) L, is at the hash value of each
word that is stored in sub-dictionary.
represents a
single word query with the position of entry into a searchable database of 5
and the position of the end of 9, is calculated on the basis of its length. All
offset one word W are on the same level (row) L, is at the hash value of each
word that is stored in sub-dictionary.
For convenience, each level is denoted as Hash (W1), Hash (W2), etc. At each level, see the corresponding word length: Length W1 = 4, Length W2 = 8, etc. All positions are located in one word ascending order, such as the first word: 5-9, 55-59, 112-116, 289-293. The sequence of levels determined by the order of words in the search template.
Connection of two adjacent elements ![]() at levels depicted, as is
the module of the difference between the first end and the beginning of the
second word, in this example equal to 78.
at levels depicted, as is
the module of the difference between the first end and the beginning of the
second word, in this example equal to 78.
Flag ![]() set prohibits the use of the corresponding
element for future construction of a new chain.
set prohibits the use of the corresponding
element for future construction of a new chain.
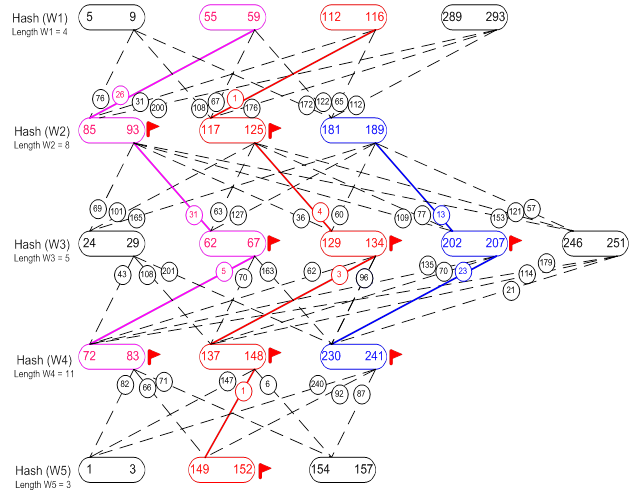
Fig. 11. Building word chains by sub-dictionary
Consider the sequence of steps in the preparation of word chains, using Figure 11. The algorithm is shown in Figure 12.
To simplify the understanding of the process, we assume that the search base has a length of 300 characters. This means that all the words of the displacement range from 1 to 300 inclusive. As used symbols taken all printable characters code table ASCII: any letter of the alphabet, uppercase and lowercase, punctuation marks, parentheses, quotation marks, white space, all the numbers from 0 to 9, special characters "-", "\", "/" , «'», «" »,« № »etc. We introduce the quantity Lim is the maximum possible distance between the two words of each other within which we will continue consideration of the item for chaining. Let Lim value for this example is equal to 60.
Start with the first node of the first level. Entered in the chain as the first element node 5-9, which we denote Vs. Remember the current level of Hash (W1), which we denote by Lc. Now we need to figure out which of the nodes of the second level is closest to the node 5-9. To do this, firstly, equate some variable Emin. Emin will store the current minimum arc length. Second, calculate the lengths of the arcs between the node 5-9 and all unoccupied (not flagged) units Vn (next) second-level Hash (W2): 85-93, 117-125, 191-199. We call this operation a “direct calculation”. In the direct calculation the distance between the element of the current level and all elements of following levels will be calculated. The minimum length of the arc store in Emin, then check to see whether the same Emin 0. If the ones found whether such word position of the second level, which would have been removed from the position 5-9 - the first word level, not more than Lim. If such a position is not present, look how many items already entered in the chain. If one item is listed, then remove it and check if there are any at the current level is still tops. If more than one element, then immediately proceed to out. If Emin is not 0, then put in the top of the chain following the current level such that meets the minimum arc. We call it Vnmin. For our example, this would be a node 85-93. Vnmin mark the busy flag in order to no longer use it in the construction of other chains. Now we need to calculate, which allows to identify the node of the first level, located as close as possible to found a second level node Vnmin. We call this calculation “reversed” or “back calculation”. During the calculation of the inverse arc will seek the minimum length between the element 85-93 Vnmin (Hash (W2)) and all elements Hash (W1): 55-59, 112-116, 289-293, already discussed except the node 5-9. The need for direct and inverse determined by the following considerations.
Note again that the replacement is possible only under the condition that there is an element Vp, located closer to Vnmin, than Vs and located within Lim.
Secondly, this action enables putting flags on all elements of the employment chain, starting with the second, which allows us to significantly reduce the number of chains by banning the construction of such chains that have already been built and were parts of chains. This is possible due to the fact that this algorithm involves lexical chains construction, since not only the elements of the first but lower levels and those for which the condition D ≥ 80% where D - the ratio of the current level Lc to the number of the last level LN determined by the total number of words a template N.
Thus, assuming the absence of reverse operation is based on the first step of the construction chain, except that we are deprived of the possibility of putting the flags of employment and for a large volume dictionary (hundreds or thousands of MB), we obtain a combinatorial explosion of overlapping chains.
If the finding of the first and the second element to exclude the operation of direct calculation, you might encounter a situation where the top of the first level will remain completely excluded from the overall calculation. Consequently, the direct calculation of the first stage of the construction chain is as necessary and the first element of any chain is not flagged employment.
Apply the inverse calculation when processing the remaining elements of the chain, starting from the third, it is impractical. This is explained by the fact that, as mentioned above, all the bias of one word are arranged in order of increasing energy, and for the whole set position (displacement) of one word can highlight some intervals within which all positions will be located all the words. In our case, as an example, it is possible to allocate slots to one symbol 100, 101 to 200 and 201 to 300.
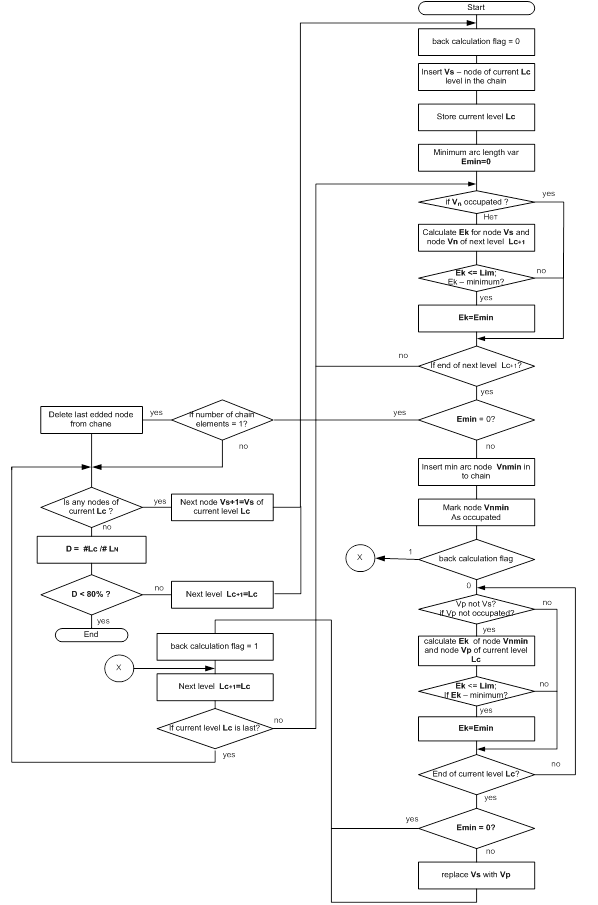
Fig. 12. Schematic diagram of the word chains preparation algorithm
It should be noted that the flag back-calculation makes it possible to track how the order element of the chain we're looking for, and to include or exclude the operation of back-calculation. The Ones. Looking at the first and second chain element flag is equal to zero and we produce inverse calculation, and the search of the third and subsequent elements of the chain flag value is changed to 1 and the inverse calculation is not performed.
Construction of new chains being first on the elements of the first level, following the order of the first elements, then, as stated above, not all of the people employed in the construction of other chains of elements of lower levels for which D ≥ 80%.
In the end, we get the set of strings that do not duplicate each other, either totally or partially. In addition, it is important to note once again, that any string can start with any level for which D ≥ 80%, and end at any level, and input search pattern can also be represented as a chain of words, the distance between them is minimal.
Thus, we have a lot of domain forming chains of words suitable for further evaluation of relevance in the development of application software.
5.3 Verification
Experimental verification of the proposed method was carried out on a case study of the administrative law section, exported from the legal information system "Consultant +" on PC-class Intel Core i5 2.5 RAM 8.0. The experiment showed how performance of the method, and it is acceptable for the practice of timing, lying in the 30 second range query processing on a selection of documents for a given value of relevance. The samples used in the search template documents up to 1-2 pages of text. [14] Detailed explanations used in the software implementation of the method of data structures and methods for optimizing the time parameters are outside the scope of this article and subject of a separate publication.
6. Software implementation
For the above-mentioned method was developed application software for special purposes.
The practical implementation of the proposed method is protected by state registration certificate program [15, 16, 17, 18, 19] and partially presented in [9, 14].
7. Conclusion
At present, the task of developing methods of search implemented in a retrieval system, is important. To solve it, was an original method, in which the concept of "comparison" is reduced to finding documents in information retrieval based, part of which, in one way or another, visually similar to the original search pattern.
The basis of the proposed method on the assumption that the similarity of documents determined by the proximity of page images of their texts, and without a semantic study of their content. As a result, the dimension of the problem to be solved is reduced by several orders of magnitude, and falls within the scope of opportunities for public computer equipment (personal computers). Reducing the dimension of the problem is achieved by considering the texts searchable database as a number of original graphics, in which a pixel is the word document. Thus, in the proposed method, as the result of the comparison is considered in the totality of the words matches the test text search of a document database and a search template with regard to their mutual arrangement or "geometric proximity".
For algorithmic implementation of the method the key points
are to build chains of coincidences forming domain, the density of which is a
measure of relevance, as well as search dictionaries needed to build a chain of
coincidences forming domain.
Thus, within the framework of this paper, to solve the problem of comparing
texts regulatory developments made the construction of exploratory dictionary,
sub-vocabulary - carrying information about the location of matching words in
the text, and the domain forming chains. It is possible to obtain a set of
domain forming chains of words suitable for further quantitative assessment of
relevance.
References
- C. J. Van Rijsbergen. -Dept. of Computer Science, University of Glasgow. Newton MA, USA : Butterworth-Heinemann, 1979.-208 pages.
- K. D. Manning, P. Raghavan, H. schütze Vvedenie v informacionnyj poisk [Introduction to information retrieval]. - M.; Williams, 2013. - 528 p.
- Electronic journal "Spamtest". 2013. No. 27 - Electronic resource URL: http://subscribe.ru/archive/inet.safety.spamtest/200312/02121841.html (date of access: 25.11.13).
- Poisk nechetkih dublikatov. Algoritm shinglov dlja veb-dokumentov. [Search for fuzzy duplicates. The algorithm shingles for web documents] - Electronic resource URL: http://habrahabr.ru/post/65944/ (date of access: 25.11.13).
- MinHash – vyjavljaem pohozhie mnozhestva [MinHash - identify similar sets]. Electronic resource URL: http://habrahabr.ru/post/115147/ (date of access: 27.11.13).
- Semanticheskaja set' [Semantic network] - Electronic resource URL: http://ru.wikipedia.org/wiki/Семантическая_сеть (date of access: 20.12.13).
- Graham A. Analiz strok [Analysis of strings]. Translation Galkina, edited by P. N. Dubner M: 2000 - 315 p.
- Novikov G. G., Graficheskij podhod k probleme nechetkogo poiska fragmenta teksta [Graphical approach to the problem of fuzzy search text]. - Scientific session MEPhI 2010, collection of scientific papers. Volume 3, 2010 p. 32 - 32.
- Novikov G. G., Identifikacija lichnosti v uslovijah real'nogo vremeni [Identification of a person in real time]. - Scientific session MEPhI 2006, collection of scientific papers. Volume 12, 2006, p. 56 - 62.
- Novikov G. G., Vybor metriki dlja nechetkogo poiska v strukturirovannoj informacii [the Choice of metrics for fuzzy search in structured information]. - Scientific session MEPhI 2007, collection of scientific papers. Volume 12, 2007, p. 126 - 127.
- Novikov G.G., Geometricheskij podhod k zadache nechetkogo polnotekstovogo poiska [Geometric approach to the problem of fuzzy full-text search]. - Scientific session MEPhI 2013, abstracts. 2013 p. 10 - 10.
- Gurov V.V., Gurov, D.V., Novikov G.G. Razrabotka metodiki obuchenija bezopasnomu programmirovaniju [The Development of teaching secure programming]. - Safety of information technology. No. 1, 2012, p. 91 - 93.
- Aleksandrovich A.E., Novikov G.G., Chukanov, V.O., Yadykin I.M. Obespechenie funkcional'noj bezopasnosti specializirovannyh JeVM s kombinirovannym rezervirovaniem po kontrol'nym tochkam [The functional safety of specialized computers with a combined booking at check points]. - Safety of information technology. No. 1, 2012, p. 75 - 77.
- Novikov G.G., Yadykin I.M. Geometricheskij podhod k probleme nechetkogo poiska fragmenta teksta v konture informacionnoj bezopasnosti predprijatija. Bezopasnost' informacionnyh tehnologij [Geometric approach to the problem of fuzzy search text in the outline information security company]. Security of information technologies. №4, 2014, p. 83-85.
- Novikov G.G., Yadykin I.M. Program function evaluation relevance fuzzy full-text search, which implements a geometric approach. The certificate of state registration. No. ITN No. 4 2014
- Novikov G.G., Yadykin I.M. Program automatic transliteration for family-registered groups in French, English and Latin notation. The certificate of state registration №2013618048 Bulletin No. 3 2013
- Novikov G.G., Yadykin I.M. Program fuzzy search in the databases of names and surnames. The certificate of state registration №2013662371. Bulletin No. 3 2014
- Novikov G.G., Yadykin I.M. Program to determine the degree of visual paging relevance of the text for realizing the method zametaya curve. The certificate of state registration №2014660638 Bulletin No. 4 2014
- Novikov G.G., Yadykin I.M. the Program determine the similarity of texts that implements the method of semantic normalization. The certificate of state registration №2014660502. Bulletin No. 4 2014