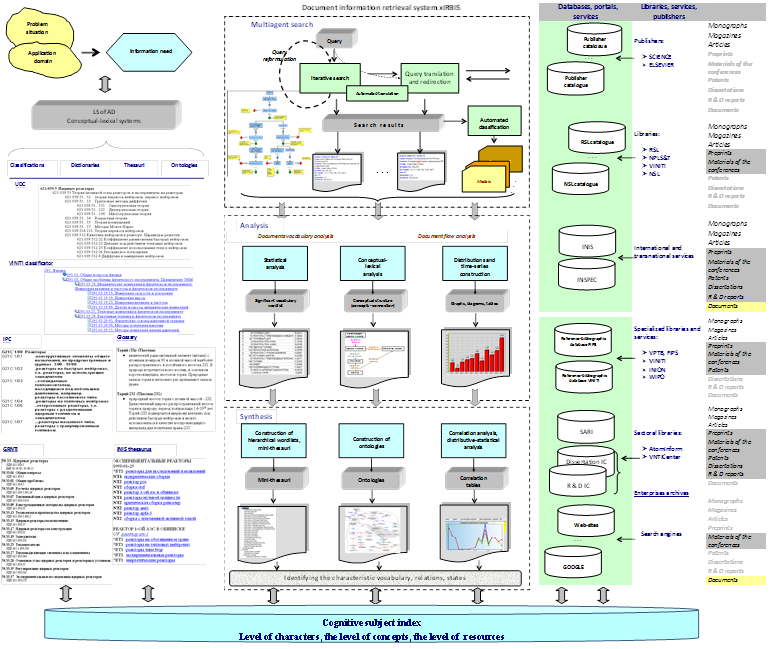
The structure and components of the operational visual space for scientific interactive information retrieval
N.V. Maksimov, O.L. Golitsyna, A.L.Usenko
National research nuclear university «MEPhI», Russia
nv-maks@yandex.ru, olgolitsina@yandex.ru, usenko_andrew@mail.ru
Contents
3. Individual in the process of cognition
4. Knowledge representation means
5. Knowledge-oriented information retrieval space
6. Interactive visual environment for information retrieval management
7. Cognitive search management. Cognitive subject index
8. CSI structure manipulation means
Abstract
The article describes the approaches to modeling and constructing of operational space of technological objects that implement the interactive iterative technology as for searching information blocks in the repositories of knowledge and building from them a new knowledge – information structures, context-consistent with the objectives and facts of a particular cognitive process. Operational space of such an environment provides the graphic elements usage that are visual representations of search and its analytical processing results as search queries and should technologically provide a construction of the self-consistent semiotic system, in which concepts represents viewpoints (paradigm), ontologies represent specific knowledge (objects and connections of a particular application domain), and the signs are operating objects in the process of "mechanical" human-system dialogue.
Keywords: information retrieval system, knowledge management, information retrieval technologies, cognitive subject index, operational visual space
1. Introduction
Any scientific, innovative or management activity, that expects gaining a novel significant result, of course, should be based on adequate information, that is almost always to be searched in different resources – traditional or digital libraries, specialized or nonspecialized data warehouses. Considering the task of scientific (innovation) retrieval it is sometimes important not only to find the documents that exactly match the query, but not to miss the boundary or similar ideas, i.e. the documents that has a little match with the query, while searching by the formal criteria, but in a particular the problem situation will be the material which will allow the user not only to extract the useful fragments from individual messages, but also to build the new knowledge. The information support of the management tasks has its own features, like defining the direction of activity, estimation its efficacy, novelty and competitive ability of one or another decision etc. This generalizes information can only be synthesized on the basis of substantive and distributive-statistical analysis of the documents flow, reflecting not only different paradigm, but also the different stages of the life cycle.
In the main activity (MA) of human knowledge, information and data exist naturally – they have the appropriate forms and stable associations with each other and with the existing set of methods and means. In the informational activity (IA) these objects (or more precisely, their images) in modern conditions of informatization will be presented in a single, semiotic nature digital form, and retain only those connections that will be considered as important during the formation of native image. That is, we can say that the unification of the presentation of any objects (objects, processes, knowledge, symbols, etc.) in a computing environment leads to anonymity: the loss of diversity of real connections transforms knowledge into separate messages that may be found, may be understood and may be appropriately used. This is the first problem of using information retrieval systems (IRS) in knowledge management tasks. The second problem is caused by the information scattering factor that is specific for all elements and stages of the life cycle of generation/utilization of knowledge. And the third – the possibilities of human information processing are severely limited, so the flow of various messages, unless they are ordered in accordance with the scheme of knowledge, will not be fully used for new knowledge creation.
IRS, that "links" the subject of knowledge with the stored knowledge, performs "mediator" function usually through a visual hard/software interface. With the rapid growth of visualization and operational capabilities of the used means and the general expansion of the MA automation field, the possibility of the IRS are increasing, leading to a complication of the interface and increase the requirements for the user. Interaction with the IRS converts to a much more complex scenarios that implements not only familiar to everybody "request/response" function, but also analytical processing, until the functions of maintaining the linguistic support.
Such circumstances predetermine the necessity of the high level of organization of the interface and system interaction scenarios, especially in the case of information support of scientific research tasks, education and management.
In [1, 2, 3] approaches to creating visual representation of application domain objects are presented, the so-called visualization metaphors, that performs a comparison of application domain objects with visualization objects. It also introduces the evaluation of such transformations – informativity, i.e. the ability to extract useful information, that is based on the visual expressiveness of the visualization language. This indicates, first of all, that visualization means should be apparent to the user and be able to reflect the change of the objects of the domain. In the tasks of scientific search support and knowledge management, that are not static, most logical way of visualization of developing application domain of research could be its ontological description. However, due to the complexity and ambiguity of construction and utilization of network structures that in particularly is discussed in [4], a preferred method of the visual representation, that are similar to the description of the established knowledge – in the form of the classification structure.
For creation and effective use of knowledge-oriented IRS, it is necessary to reveal common properties and specificities of the basic objects and processes and define forms and develop technologies for their "natural" utilization in the interactive visual operating environment. The authors in this study relied on a number of previously obtained results, which main provisions with the purpose of completeness of the problems presentation are listed below.
2. Cognitive process
Generally, given the outlined in [5] thesis, knowledge creation is based on the following assumptions.
· Knowledge appears in the interaction between man and available (in the general case provided) for him environment. At the same time created knowledge that was initially oriented on the study of a particular application domain (AD), eventually leads to the transformation of this environment.
· The incentives for knowledge are contradictions that can be resolved by structuring the obtained knowledge from the position realized accepted knowledge or a new individual’s point of view.
· The technological basis for the cognition process is that getting as the facts the elements of realized, proven theory and practice, knowledge, due to its decomposition and ordering in accordance with its own methodological scheme, the subject of knowledge forms the personal knowledge, a new, at least for himself and which, in turn, becomes the object of inspection, research and application.
The syntheses of new knowledge, as part of the evolution of an inhomogeneous environment, belongs to the class of self-organizing, i.e. largely determined by the notion of "deterministic chaos": a randomness in such systems exists, but it is limited. This means, that there is a predominant (potentially selected) direction of the process development, and an element of randomness provides the possibility of new, which somehow leads to a violation of the established system, it completing or output beyond itself [6]. So the "mechanism" of generation of new knowledge, when as a result of accidental or purposeful combination of information objects, synthesizes combinations, having novel properties, includes:
- Identification of the "mating" generality and differences of combinations;
- Selection and "inscribing" of novelty signs, which in aggregation generates a new quality;
- Assessment of constructability (value) of combination and, possibly, generation the fact of evaluation of the effectiveness of information received (and also, perhaps, the facts – related or new problems generated as a result of the synthesis process).
This approach is methodologically binds relatively independent and, at the same time, self-determined objects MA and IA – documents and classifications. That is, in the fragmented nature of the cognition process, ensures the integrity and stability of its development. In general, this evolving process can be presented as a double helix, in which the evolution of facts (hypotheses, methods, results) are represented by documents, that are synchronized with the evolution of the system point of view (paradigms, knowledge organization and science), presented in classifications and conceptual and terminological systems.
3. Individual in the process of cognition
The basis of cognitive processes, are the special properties of the individual – the actor of cognition process, particularly the following [7] abilities:
- to receive and compress the information about the cognizable object;
- to provide synchronization of knowledge;
- to perform classical logic and classical calculus of probabilities calculations; ability to discover mathematical truths;
- to have a variety, surpassing the compressed variety of cognizable object.
We cannot ignore such a human trait, as the inability to clearly specify (express using available linguistic and conceptual tools) the cognitive information need, especially if it is associated with the initial stage of knowledge. Moreover, a person knows more than he “publish" ("non-verbalized" component). It is an iterative interaction between man and information system that will "pull" the information about the object of study, not only from the information system, but also from the human mind: the system, by fixing the search path and information images used (perhaps generated by the system, but selected by the person), not only allows you to return to any information object, and use a different trajectory, but also verbalizes implicit knowledge of the person.
4. Knowledge representation means
In the base of knowledge synthesis model as a self-organizing process [8] is a structural feature of the system – the possibility of its expansion into relatively independent subsystems. That is, a complex system can be described by a set of relatively independent aspect representations (contexts, built over the "net" of the basic concepts and relationships). Every such description provides only a partial knowledge about the system in a whole, but complete with respect to the aspect. It is essential that during the process of decomposition, the components are not only distinguished, but also a decomposition scheme – a system of characteristic features, in accordance with which the decomposition is carried out, is formed.
Generated and accumulated knowledge (as well as the cognition process) is usually can be sufficiently adequate represented by hierarchical structures: classification schemes, application domain subject index, etc. Classification type structure reflects the mechanics of cognitive process: knowledge specialization increasing is usually realized by dividing the whole into parts according to the values of the selected division feature. Reflecting the systematic organization of science, and fixing the accepted view on the structure and relationships of individual sections and areas of research, they forms and maintain methodological knowledge. However, it should be noted that this division will be valid only for a fixed, already realized knowledge, and not for that which can be in the future: extracting the certain areas of research and, thus, determining the "principal directions", we also have implicitly "imaginary" area, which are not in the process of cognition. I.e. for developing AD such division should be dynamic.
Moreover, in the base of representation of AD a hierarchical division scheme of the information space is commonly used, that reflects different points of view. Hence, in particular follows, that for every aspect of the AD informative elements must be found independently.
In general, this technique is inherently an implementation of a system approach that allows, on the one hand, to present the object as a set of homogeneous (typed) elements connected by some relations, forming in aggregate a unity, and on the other – represent the system of homogenous objects in the form of classification that, in turn, makes it possible to explicitly allocate new characteristic features, define methods for extracting subsystems, and based on the properties of compliance and symmetry detect relations (including antagonisms) with other classification systems [9].
5. Knowledge-oriented information retrieval space
Abilities and effectiveness of the information system that are focused on retrieval of scientific information is affected by several significant factors arising from the nature and features of interacting sides – the person and the system.
1. IRS in a generalized man-machine system MA/IA plays a substitute role and therefore the search of potentially useful information can be considered as the process of constructing a new system of knowledge where the IRS performs the role of "mixing layer": by shaping and arranging unequal combinations of information components (retrieved documents and terms), search engines are prepared alternatives, and classification and logging means set (or, more precisely, fix) the direction of development, that user selects (not generate) as preferred for the subsequent synthesis of knowledge.
2. Search – is a process that leads to selection through the comparison of the searched with stored in the array, and the objects are not compared themselves, but their well-structured formal descriptions – search patterns (SP). Such images should include the concepts that are characterized the document, but the concepts also have to be rather generalized and well-known. In the class of search tasks such "generality" achieved by reducing detail of the concepts and typing (simplification) of the connections, as well as the normalization of vocabulary. As independent information objects, SP are not initially created for the problems of analysis and synthesis of knowledge – they are an identification equivalent of the object (or its description) in the tasks of extraction/identification of object among the others.
For constructing the SP that would identify the document content, typically one or another terminological system is used, that is an integral collection of semantically related concepts that are exist, for example, in the form of thesaurus and ontologies. Both thesaurus and ontologies are network structures, where nodes contain the concepts, and arcs are setting substantial for the context connections. But for all that, the typology of relations in the ontology similar to the relationship in the application domain, but the main type of relations in the thesaurus are genus-species, which meet the basic method for defining concepts – by genus and species differences. Thesaurus is a model cognition instrument that reflects, primarily, the structure of the sign system, usually at the level of knowledge branch. Ontology in its turn, is the model of the specific, and represents the situational knowledge about the application domain, reflecting the diversity of the main entities, characteristic relationships between them, usually at the level of single decision or compact AD.
3. In any IS the conversion of information is sequential reflection of the content, and in essence – filtering: reduction the degree of expression freedom (and, correspondingly, the subsequent perception) of semantic content by the fixing the expression method, i.e., the transmission of the meaning in context or metainformation component. For example, the scientific report suggests that proper domain is known to the receiver (i.e., just enough to call it); document – fixation the representation way of object’s essence through the selection and linguistic binding of concepts, which meaning is defined in the corresponding, existing quite independently conceptual-terminological system (glossaries, ontologies), the search pattern – the fixation of the meaning of terms, which usage specificity for a given application domain are defined in thesaurus.
4. The feature of interactive information retrieval is that a search request typically includes 3-5 concepts, though, in the general case, the need couldn’t be reduced to the form of a question in principle (except monosyllabic), and a in the query it is necessary, as mentioned above, to use conventional and well-known concepts. This approach obviously cannot provide a construction of issue, ideally corresponding to the real information need, predetermining the need for subsequent estimation of the real value of each issued document by user. Until recently, this technology was quite rational, because it provides the necessary recall of selection at a reasonable amount of viewing. The situation changes significantly when the search is conducted in the global polythematic warehouses or even in specialized historical databases containing hundreds of millions of documents: in that case issuing redundancy significantly surpasses human capabilities. On the other (structural and semantic) point of view, the result of scientific research (usually presented in the document) – is a set of interrelated conceptual blocks (corresponding, for example, with the components of development), each image presents with a set of more or less specific concepts (as illustrated, in particular, by dynamics of query search in specific subject area, as shown in Fig. 1.). The assumption about complexity of application domain determines the need to identify possible "blocks" that are implemented in the search through the use of linguistic and statistical relationships, reflected, for example, in the thesaurus, glossary topic word-list or ontologies of AD.
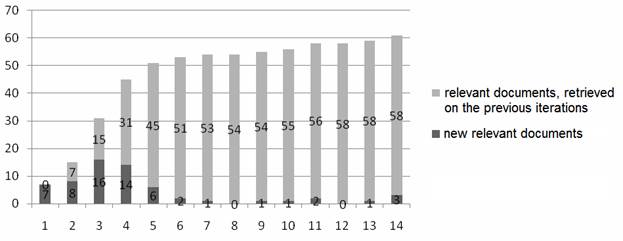
Fig. 1. Example of search dynamics
The growth of the efficiency of selection may be achieved through the use in the search patterns more accurate and specific concepts, which symbolic constructions will obviously be more cumbersome (verbose), syntactically and semantically more complex, and because of that – perhaps of little use in the traditional query-response mode: during the preparation of the request is hard enough to not only remember the exact "construction" of the term, but even type it in query expression line. However, due to the high specificity, they will certainly be used not only in assessing the potential usefulness of retrieved document, but during the search with query reformulating based on relevance feedback.
6. Interactive visual environment for information retrieval management
From a technology perspective the search process can be defined as a sequence of steps, whose tasks – removal of uncertainties of different types (linguistic, semantic, etc.) that is the result from information changes in the aggregate information system [10]. I.e. the process is complex (compound, not one-acted, iterative) and typically implemented as the row of cycles as shown in Fig. 2, where the inner cycle ensuring the bringing the users vocabulary to the vocabulary of the information resource (IR), and then – reflection of a formalized presentation of information need on the application domain (AD) of the resource, and the outer cycle – the ability to reformulate the problem as gathering knowledge from IR.
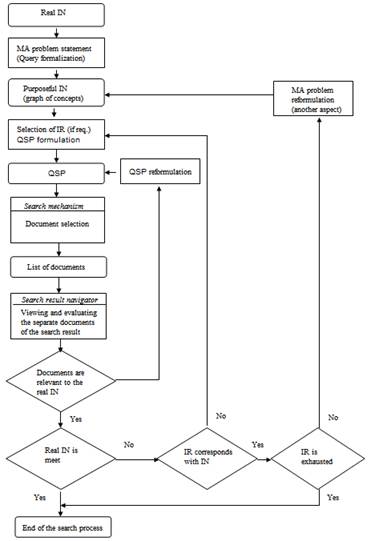
Fig. 2. Generalized algorithm of automated information retrieval (given as in [10])
Shown in Fig. 2 generalized flow diagram of the search process using the different search mechanism [11] and with the difference in structure and the nature of use of interface means for query representation reflects the following essential feature of information retrieval.
Due to the information scattering, the user is unable to know in advance the resource content and, accordingly, the response. Also, usually, the search object is not specified as a sample, which can be "mechanically" compared with the result found. I.e. the task of search process organizing has an optimization nature – with time constraints given, the task is to maximize (although, in essence – subjective) confidence in the quality of a search by providing user during the dialogue alternative directions, as well as quantitative and qualitative assessment of their compliance with the request. The proof of recall, which value cannot really be formally evaluated (due to the fundamental impossibility of complete knowledge about existing or creating solutions), compensate by confirmability – the results that are obtained in other way, such as entering the database information space through information objects of different nature and/or the use of search mechanisms of different types.
Practically, the estimation of completion degree (convergence) of the search process can be carried out by the criteria of exhaustion of the vocabulary growth and/or documents on the reformulation iterations (see Fig. 1).
Natural presentation of search results as a set of documents also has its own features, related to the post-processing of results in a cyclical search process.
First, the use of different search mechanism (coincidental terms search, analogues search, search of "similar" document, retrieval using relevance feedback) determines the "diversity" of the quality of search results by the precision, recall, issue volume, that requires ranking and limitations of issue.
Secondly, for the initiation of new search cycles, the documents obtained at the current stage of search process can be used, for example, either by direct inclusion of the documents vocabulary in in search query or by reformulating the query based on relevance feedback.
Third, each stage of the search cycle, by filling the user’s documents collection, should ideally thereby forming personal subject area. This means that all users’ results must be accessible to for him, at least as the set of documents, that provides by a protocol of the search. I.e. results became the same elements for making the request (as the terms) during the next search cycle.
Revealing in terms of a no single step, but quite effective search technology example of using external feedback that was implemented in IAS Irbis [15], is an algorithm, comprising the following steps:
1. Search query formulation and conducting a prior search.
2. Viewing results and the highlighting of really (subjectively) relevant documents.
3. Formation a wordlist of relevant documents.
4. Viewing wordlist and extraction of new terms.
5. Building clusters of documents.
6. Viewing cluster and formation of the resulting issuance
Fig. 3 shows a fragment of the relevant documents vocabulary. In the further process of forming the context field and automatic clustering will participate terms that are only marked by user. It is essential that the selection process thereby providing the ability to include the low-frequency (statistically insignificant) terms in the search.

Fig. 3. Relevant documents wordlist
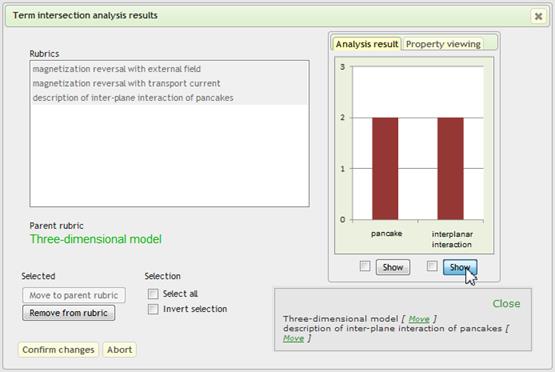
Context-specific document clusters (Fig. 4) are included in the overall system protocol and after that they are available not for viewing only, but also for iterative use as an independent result (e.g., participation in search operations).
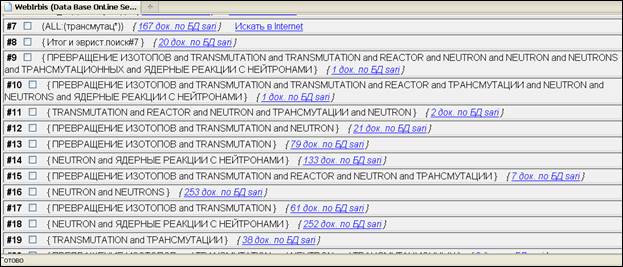
Fig. 4. Context-specific document clusters
For viewing context-specific clusters visual means for representation result such as graphs and quantitative distributions can be used, when the documents are grouped together not on the basis of semantic similarity, but by formal accessories, for example, one team, the period of creation, classification code, etc. Such distribution built for the profiled documentary flows and related conceptual-lexical systems, firstly, allows to obtain a quantitative assessment of the state and development trends of AD, and, secondly, without additional selection provide the transition from graphic element (segment histogram, points in the time series) to view the relevant documents, where each document may be used as the query for subsequent searches. A graphical representation of the result allows you to clearly position the subject of the own MA and (implementing the principle of feedback), if necessary, reasonably and consistently to reformulate the real IN, including restructuring the problem or task.
Fig. 5 shows the time series of the publication activity (Fig. 5a) and use of specialized vocabulary (Fig. 5b), illustrating the dynamics of research direction development.
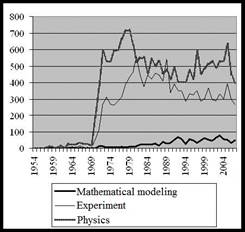
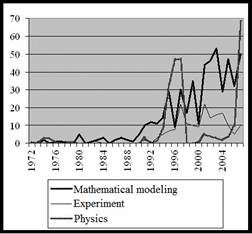
Fig. 5. Publication time series (a) and publications that uses term TRANSMUTATION (b)
From the point of target application of IRS in the search process, the two major operating objects are available for user – query and document, that by using language means represent semantically integral fragment of application domain. Other operating object – technological – is somehow derived from the basic. Such objects are, in particular, frequency dictionaries and word-lists, subject indexes, thesaurus, ontologies, etc. Their purpose – is to give an ability to remove of fix the uncertainty of a particular type.
Operating objects of linguistic support of information retrieval in relation to the subject of the search are divided into two types – static and dynamic.
Static objects include classification systems (UDC, BBK, GRNTI etc.), industrial information retrieval thesauri, frequency dictionaries of the IR. Their availability in the search process can solve the problem of correlating the terminology in the information resource, the accepted terminology of the problem domain and the user’s terminology.
But equally important are the dynamic objects that reflect the current state of the documentary space of the search subject.
On the basis of the frequency word-lists of relevant vocabularies of the retrieved document a mini-thesaurus of the theme can be formed, genus-species connections are presented with links of "part-whole" type, built on the lexicographic attributes.

Fig. 6. Mini-thesaurus fragment
Mini thesaurus can be used as an instrument not only for lexical expansion of query expression, but also as a separate technological object (Fig. 6). Thus, structural-linguistic models of an application domain of search are dynamically created, reflecting not only the conventional, but also actual characteristic for the problem situation feature of representation of IR (including, perhaps, innovative approach of the user for its solving problem).
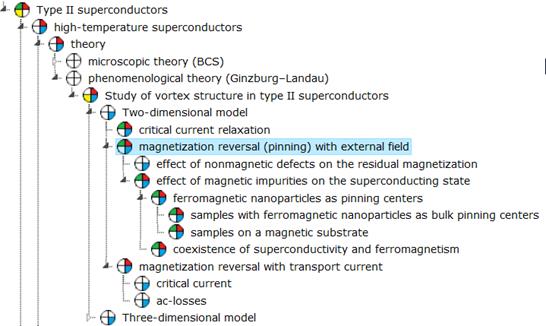
Whereas the sectorial thesaurus provides a "navigation" on the conceptual system and gives an insight into the extent of possible recall, precision and specificity of the conventional (in the corresponding sector) terms, that are selected for describing and searching the object, ontology (Fig. 7) provides "navigation" in the subject area and provides a presentation about the role and significance of terms and relations held in a particular description. As a reflection of the particular situation, ontology, constructed, for example, on the set of relevant to the search subject documents will, also, capture a personal view of the problem of search. According to its possible change in time, the change of sight on the problem situation can be seen.
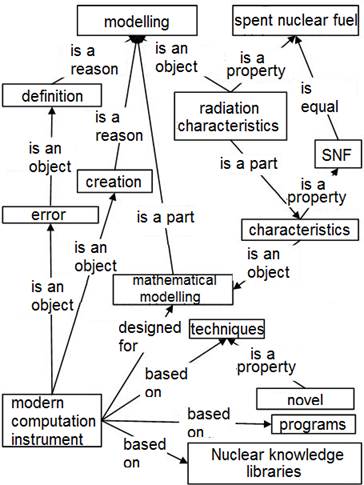
Fig. 7. Example of graph of functionally interrelated concepts
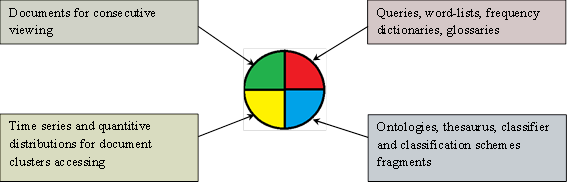
In general, a variety of resources, reference components of linguistic support, search technology and information processing as illustrated in Fig. 8.
In that case no one object or technology can separately provide the full and valuable result. Each of the mentioned above objects in its structure and behavior are quite obvious. But for all that, each of them has its specific construction technology and "element base", whereby they cannot be integrated analytically. A promising approach, that are based on man-machine complementarity, is to create an environment which interactivity is based on thematically synchronized (firstly from the point of view of the user) visualization ensured by the completeness of the set and the diversity of technological objects, the possibility of constructing an objective assessment of the state of the search process and the choice of its development means (as shown in Fig. 8).