ПРИМЕНЕНИЕ NVIDIA OPTIX ДЛЯ ПРОВЕДЕНИЯ ЧИСЛЕННЫХ ЭКСПЕРИМЕНТОВ
В.А. Дебелов
Институт вычислительной математики и математической геофизики СО РАН, Новосибирск, Россия
Оглавление
6. Ситуация “Q” – проблемы видеодрайвера
Аннотация
Достаточно много научно-исследовательских программ разрабатываются для проведения численных экспериментов во время отладки алгоритма или получения различных характеристик исследуемой компьютерной модели. Как правило, в дальнейшем на основе полученных данных модель анализируется средствами научной визуализации.
В данной работе рассматривается причина выбора системы OptiX фирмы Nvidia в качестве инструмента проведения численных экспериментов в рамках научно-исследовательской разработки при использовании графических процессоров (ГП) GeForce фирмы Nvidia.
Хотя OptiX является надстройкой над CUDA и работает на графическом процессоре, исследователь не обязан для программирования знать такие особенности, как архитектура ГП, CUDA, OpenGL, DirectX. При этом знания программирования для кластера – например, MPI (Message Passing Interface) – также не нужны.
OptiX рассматривается как инструмент для эффективного исполнения на ГП тройного цикла
i = 0 .. N
j = 0 .. M
k = 0 .. K
f(i, j, k, <дополнительные
параметры>),
где f(i, j, k, <дополнительные
параметры>) – это отлаживаемый алгоритм или тестируемая
компьютерная модель.
С точки зрения автора рассматриваемые ГП можно представить как настольный кластер, включающий несколько процессоров, работающих параллельно на общей памяти. Запустив программу на этом “кластере”, исследователь может параллельно использовать персональный компьютер по своему усмотрению.
На примере разработки простейшего рендера для сцен, состоящих из полупрозрачных оптически изотропных объектов рассматриваются побудительные мотивы к использованию OptiX и основные привлекательные характеристики OptiX. Сообщается также о неприятности, которая может случиться во время работы программы.
Ключевые слова: вычислительный эксперимент, научная визуализация, трассировка лучей, Nvidia GPU, CUDA, OptiX.
1. Введение
Достаточно много научно-исследовательских программ разрабатываются для проведения численных экспериментов во время отладки алгоритма и получения различных характеристик компьютерной модели.
Во многом выбор инструментария и среды разработки приложения определяет назначение разрабатываемой программы, например, 1) программный продукт; 2) прототип программного продукта; 3) одноразовые программы для тестирования разрабатываемого алгоритма. Излагаемый в статье подход ориентирован на последние два случая.
Во многих случаях алгоритм последовательный, но для качественной проверки требуется получить некоторую целостную картину, просчитывая его для ряда наборов связанных параметров.
- Для построения фотореалистического изображения алгоритм работает для серии пикселей.
- В научной визуализации для построения графической зависимости (графики, изоповерхности и т.д.) требуется просчитать алгоритм для нескольких наборов параметров модели.
Простой прямолинейный подход – просчитать алгоритм для всех наборов параметров последовательно – приводит к длительному затягиванию времени проведения экспериментов. Часто для параллельного расчета сразу для нескольких наборов параметров применяется MPI (Message Passing Interface), в этом случае для реального получения выгоды во времени счета требуется наличие подручного кластера. Иначе время ожидания между расчетами сводит на нет скорость вычислений, так как на корпоративных кластерах, как правило, очереди из задач.
Возросшие мощности (память и скорость вычислений) графических процессоров также привлекли к себе внимание исследователей. Линия графических процессоров (ГП) GeForce фирмы Nvidia – это платы, представляющие достаточно мощные многопроцессорные компьютеры. Разработана специализированная технология программирования CUDA для этих ГП. В последнее время стало модно программировать параллельные приложения, используя технологию CUDA. Большая часть приложений относится к научным вычислениям, о чем говорит содержание альманаха [1]. Что потребуется от исследователя для перехода на CUDA:
- Надо изучить технологию CUDA. Знать архитектуру ГП. Очень времяемкий процесс. Или приглашать программиста, которому надо будет объяснить суть алгоритма в некотором объеме.
- Имеющийся код на С/С++ необходимо значительно переделать.
- По окончанию экспериментов код на CUDA становится ненужным. Также, скорее всего, этот код не подойдет для ГП других производителей.
А требовалось всего-то отладить алгоритм.
В принципе, подход напоминает переход с языка высоко уровня на более низкий уровень, что, как правило, ведет к уменьшению производительности труда исследователя, хотя может дать значительный выигрыш в производительности программы.
В последние годы Nvidia популяризирует технологию OptiX, построенную над CUDA для создания параллельных программ для приложений, основанных на трассировке лучей [2, 3]. С точки зрения автора статьи OptiX можно охарактеризовать следующим образом:
- Хотя OptiX построена над CUDA, программист не обязан знать CUDA. Правда, для знатоков CUDA, OpenGl и DirectX возможно применение их знаний для построения более эффективных программ.
- Программист должен немного перестроить свои модули на С или С++ при переходе на OptiX. В основном это касается косметических изменений при передаче параметров и организации основного цикла.
- Очень полезная черта: исходные коды переносимы между Windows и Linux платформами.
- Большой набор примеров приложений в исходных кодах, например, программы рендеринга на основе алгоритмов Виттеда и Кука для расчета фотреалистических изображений, программа моделирующая движение без столкновений и другие.
- Для Windows обеспечивается автоматизация компиляции и сборки программ в рамках Visual Studio 2010. Для Visual Studio 2012 создан wizard приложений, создаваемых в среде OptiX.
- OptiX позволяет в одной программе использовать не только один ГП, а все, которые установлены на используемой платформе.
- Отрицательной стороной OptiX на современном этапе является ориентация на float, а не на double. Использование последних потребует определенных дополнительных усилий.
- Также представляется неудобным существующий на данный момент процесс отладки. Код части программы, расположенной на ГП, приходится отлаживать через печати. В этом смысле процесс не сильно отличается от отладки программы на кластере, правда, печати приходят оперативно.
В данной работе не приводится описание OptiX в какой-либо сокращенной форме, а просто показано, как применение OptiX сказывается на времени работы программы.
2. Структура задачи OptiX
В общем виде задача OptiX представляется как тройной цикл:
i = 0 .. N
j = 0 .. M
k = 0 .. K
f(i, j, k, <дополнительные
параметры>),
где f(i, j, k, <дополнительные
параметры>) – это отлаживаемый алгоритм или тестируемая
компьютерная модель.
Рассмотрим несколько примеров классов задач
1. Если исследователь рассчитывает физические характеристики некоторого тела (объем, момент инерции и т.п.) на основе воксельного представления, то ему удобно функцию f(i, j, k, …) рассчитывать для каждого вокселя отдельно. В этом случае он вполне может передать OptiX организацию параллельного исполнения M×N×K вычислительных процессов.
|
|
|
|
Рис. 1. Объекты в воксельном представлении.
|
|
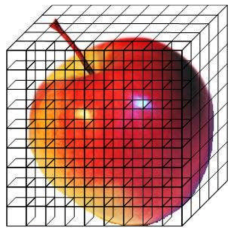
2. При обработке изображений часто тройной цикл не нужен, тогда K полагаем равным 1, а число параллельных процессов равно M×N.
|
|
|
|
Рис. 2. Слева: исходное изображение, справа: результат. |
|


3. Научная визуализация. Имеется много классических методов визуализации параметров исследуемой модели, таких как векторные поля, изолинии, изоповерхности и так далее. Например, в работе [4] (см. рис. 3) показано распределение характеристик в объеме при помощи изоповерхностей. Очевидно, что расчет характеристик проводился в узлах трехмерной сетки, т.е. это задача с тройным циклом M×N×K.
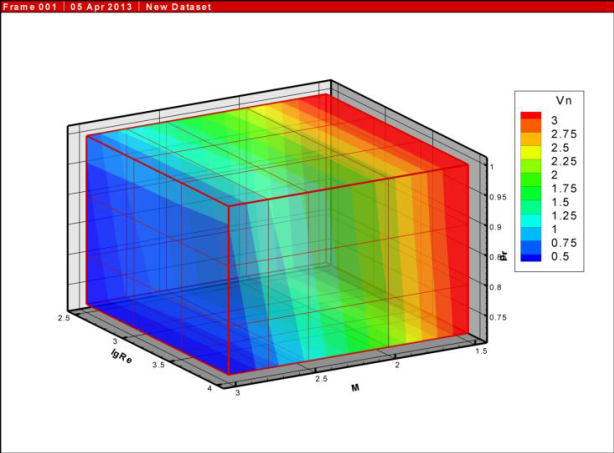
Рис. 3. Зависимость критической скорости от чисел Маха, Рейнольдса и
Прандтля.
Следующий пример на рис. 4. Из работы [5] – это показ неупорядоченных наборов многомерных данных с применением метода главных компонент. Здесь можно воспользоваться только одиночным циклом M×1×1.
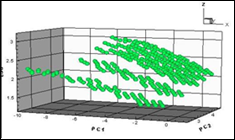
Рис. 4. Представление многомерного объема в пространстве трех первых главных компонент.
Больший сервис Optix предоставляет приложениям, которые в качестве основного инструмента используют трассировку лучей (путей) в некоторой двумерной или трехмерной геометрии (сцене). В этом случае можно применить несколько алгоритмов OptiX ускорения расчетов пересечения луча с объектами сцены.
4. Самыми известными приложениями данного типа являются программы рендеринга, рассчитывающие фотореалистические изображения трехмерных сцен. Научная визуализация накладывает дополнительные требования, например, как в работе [6], когда исследователю требуется в каждой видимой точке показать значение некоторого параметра (параметров) при помощи цвета. В данном примере – это карта степени поляризации света и карта эллиптичности поляризованного света (см. рис. 5).
|
|
|
|
|
|
Рис. 5. Слева направо: полноцветное изображение, монохромное изображение (580нм), карта поляризации (580нм), карта эллиптичности (580нм). |
|||




3. Структура сцены OptiX
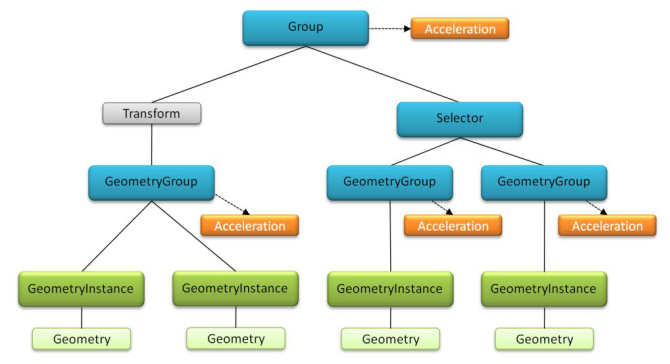
Рис. 6. Граф сцены OptiX (рисунок взят из [3]).
- Group – вся сцена или ее подграф.
- Transform, Selector – способ включения подграфа в данный узел – через преобразование координат или как выбор из альтернативы.
- GeometryGroup – геометрия некоторого, возможно осмысленного, объекта сцены.
- Geometry – геометрия, набор однотипных геометрических примитивов. Может быть только один примитив.
- GeometryInstance – геометрия Geometry, специфицированная одним или несколькими материалами.
- Acceleration – способ организации геометрии подграфа, предназначенный для ускорения операции пересечения луча с геометрией, заданной данным подграфом на основе габаритных боксов сыновних узлов данного узла. Из схемы понятно, что разным узлам можно назначить свой алгоритм ускорения. Очевидно, что приложения, которые не базируются на трассировке лучей в некоторой геометрии, данный инструмент не используют.
Структура описания сцены вполне естественная, поэтому здесь переход на OptiX не вызывает трудности. Явно ни один из геометрических примитивов не является в OptiX стандартным. Для каждого используемого примитива программист должен предоставить две процедуры: 1) вычисление габаритов примитива; 2) вычисление точки (точек) пересечения произвольного луча с примитивом. Здесь надо отметить, что богатый набор примерных приложений, поставляемых с OptiX, содержит большое число требуемых процедур, запрограммированных с высоким качеством. Отметим наличие процедур пересечения луча с традиционными примитивами: треугольник, куб, сфера, сетка высот, сетка треугольников (mesh) и другие.
Еще один очень полезный механизм предлагается в OptiX – это Callable программы, которые, по сути, С/С++ функции, вызываемые в модулях, работающих на ГП. Получается, что нет ощутимых ограничений на стиль программирования.
4. О тестовом приложении
|
|
|
|
Рис. 7. Слева: простая сцена, справа: усложненная сцена. |
|


Описываемое экспериментальное приложение программировалось для отладки расчета взаимодействия луча поляризованного света с границей двух оптически изотропных сред, например, с границей воздуха или воды с кристаллом алмаза или объектом из стекла. Для того чтобы проверить большое количество вариантов такого взаимодействия тестовое приложение по сути – это рендер, рассчитывающий фотореалистическое изображение. Расчет всех пикселей картинки можно проводить параллельно.
Алгоритм расчета взят из работы [7] и вычислительно является очень трудоемким. Тестовая сцена (см. рис. 7,слева) включает 27 прозрачных кубов и излучающий квадратный многоцветный источник света. Воображаемая охватывающая сцену сфера излучает освещенность 40% стандартного источника CIE D65. Как и в работе [7] применяется обратная рекурсивная трассировка лучей и спектральный рендеринг для 81 длины волны в видимом диапазоне от 380 до 780 нм. Все кубы идентичны, для простоты их коэффициент преломления положен равным 1.2 и не зависит от длины волны. На рис. 7,справа представлена усложненная сцена – вместо трех этажей кубов сделаем девять, то есть 81 куб.
Вся сцена организована как единая Geometry, состоящая из 27 или 81 примитива типа куб. Рассчитываемые изображения имеют размеры 768х768 пикселей.
Задача трехмерная, так как спектральный рендеринг, то есть основной модуль программы выглядит как
f(i пикселя, j пикселя, k-ая длина волны, <дополнительные параметры>).
5. Эксперименты
Итак, для отладки последовательного алгоритма, предназначенного для вычисления одного пересечения луча с границей двух сред, пишем последовательный рендер-П для расчета изображения сцены. Используется технология программирования MS Visual Studio 2010 и C++. Второй рендер-О программируем с применением OptiX. За день добиваемся того, чтобы все обрабатывающие модули имели идентичный код за исключением способа передачи параметров. В принципе не требуется никакого знания о используемом ГП, кроме того, что он разработан Nvidia и имеет сколько-то CUDA-ядер и его compute capability SM_NM (например, SM_21, SM_50). Последнее надо указать в параметрах сборки приложения.
Основная платформа для экспериментов – ноутбук: Intel® Core i7-3630QM @ 2.40GHz, Win 8.1, x64, VS2010, CUDA 5.5, OptiX 3.5.1. ГП1: GeForce GT 650M, 384 CUDA Cores.
ГП2: GeForce GTX 560 Ti, 448 CUDA Cores. ГП2 стоит в десктопе: Intel® Core 2 Quad @ 2.50GHz, Win 8.1, x64, VS2010, CUDA 5.5, OptiX 3.5.1.
Таблица 1. Рендеринг простой сцены (время в секундах)
|
Глубина трассировки |
Рендер-П |
Рендер-О, ГП1, 384 ядра |
Рендер-О, ГП2, 448 ядер |
|
6 |
204 |
23 |
10 |
|
8 |
298 |
47 |
22 |
В табл. 1 приводятся времена расчета простой сцены. Из нее видно, что количество CUDA-ядер сказывается на времени выполнения программы. Для себя автор принял следующую модель (структуру) ГП типа Nvidia GeForce. В CUDA есть понятие варпов (warp) из 32-х ядер CUDA. Давайте считать, что ГП1 – это Np1 = 384/32 = 12 «виртуальных процессоров», а ГП2 – это Np2 = 448/32 = 14. Таким образом, считаем, что ГП1 – это кластер с общей памятью и 12-ю виртуальными процессорами, работающими почти независимо. Часть из них занимает под менеджмент сам OptiX, а на остальных он запускает параллельную обработку трассировки лучей. Таблица показывает, что применение OptiX существенно ускоряет расчеты, а исследователь получает подручный вычислительный кластер. Пользователь во время счета его OptiX-программы занимается на этом же компьютере другими делами. И это без знания деталей конструкции ГП, CUDA, OpenGl, DirectX и шейдерного программирования. Заметим, что игровые ноутбуки в настоящее время имеют 1536 CUDA- ядер (1536/32 = 48 виртуальных процессоров) и более.
Приведенные выше времена получены программой без всяких установок, ускоряющих работу программы на ГП, так называемый режим NoAccel (без структур ускорения). OptiX предлагает с десяток различных алгоритмов ускорения операции пересечения луча с геометрическими объектами сцены. Здесь будут рассмотрены не все они. Рассмотрим некоторые и то, как они влияют на время решения задачи. Каждый программист должен посвятить определенное время и подобрать подходящий алгоритм ускорения для его задачи, для его геометрии.
При создании GeometryInstance необходимо назначить ту или иную стратегию ускорения: NoAccell – без ускорения; Lbvh, Tbvh – алгоритмы OptiX. Проведем эксперименты на усложненной сцене из 81 куба. В дальнейшем применяется только Рендер-О, то есть на основе применения OptiX.
Таблица 2. Рендеринг усложненной сцены (время в секундах)
|
Глубина трассировки |
Алгоритм |
Рендер-О, ГП1, 384 ядра |
Рендер-О, ГП2, 448 ядер |
|
6 |
NoAccel |
114 |
29 |
|
8 |
NoAccel |
279 |
80 |
|
10 |
NoAccel |
635 |
Q |
Из приведенных цифр становится ясно, что на ГП2 под собственно трассировку выделено больше виртуальных процессоров, чем на ГП1. Менеджмент OptiX, скорее всего, и там и там занимает одно число процессоров. Символом Q отмечена ситуация, рассмотренная ниже.
Рассмотрим времена счета (см. Табл. 3), полученные на ГП2 для разных глубин трассировки и разных алгоритмов ускорения.
Таблица 3. Рендеринг усложненной сцены (время в секундах)
|
Глубина трассировки |
Алгоритм |
Рендер-О, ГП1, 384 ядра |
Рендер-О, ГП2, 448 ядер |
|
6 |
NoAccel |
116 |
29 |
|
6 |
Lbvh |
113 |
35 |
|
8 |
NoAccel |
275 |
80 |
|
8 |
Lbvh |
277 |
89 |
|
10 |
NoAccel |
635 |
222 |
|
10 |
Lbvh |
645 |
212 |
|
12 |
NoAccel |
- |
643 |
|
12 |
Lbvh |
- |
552 |
Видим, что для глубины 6 и режима NoAccel в Табл. 2 стоит 114 сек., а в Табл, 3 – 116 сек. Это объясняется тем, что общая загрузка компьютера отличается во время замеров времени, а время счета в таблицах астрономическое.
По цифрам в Табл.3 можно сделать вывод, что для такой простой сцены выигрыш от применения алгоритмов ускорения начинает проявляться только при больших глубинах трассировки, то есть когда число операций пересечения луча со сценой превысит некоторую величину. Этого порога мы не стали дожидаться. Сравнение ГП1 и ГП2 опять показывает, что скорость расчета приложения OptiX зависит от числа ядер CUDA на используемом ГП.
Теперь рассмотрим ту же сцену, но каждый куб опишем при помощи 12-ти треугольников, то есть создадим треугольную сетку из 972 треугольников. Число примитивов увеличилось в 12 раз.
Таблица 4. Рендеринг сетки треугольников (время в секундах)
|
Глубина трассировки |
Алгоритм |
Рендер-О, ГП1, 384 ядра |
Рендер-О, ГП2, 448 ядер |
|
6 |
NoAccel |
666 |
433 |
|
6 |
Lbvh |
99 |
37 |
|
6 |
Tbvh |
99 |
41 |
|
8 |
NoAccel |
1623 |
Q |
|
8 |
Lbvh |
246 |
121 |
|
8 |
Tbvh |
247 |
121 |
|
10 |
NoAccel |
- |
- |
|
10 |
Lbvh |
582 |
271 |
|
10 |
Tbvh |
585 |
273 |
Судя по цифрам в Табл. 4, оба алгоритма ускорения работают примерно одинаково. Скорее всего это связано с тем, что рассматривается очень простая ситуация – статическая сцена с одинаковыми по размерам примитивами.
6. Ситуация “Q” – проблемы видеодрайвера
В приведенных выше таблицах символ “Q” информирует о том, что задача снялась аварийно. Windows 8.1 сообщает об этом как “Видеодрайвер перестал отвечать и был успешно восстановлен” (“Display driver has stopped working and has recovered”). Поиск по сети показал, что аналогичные сообщения возникают и в игровых программах при работе в Windows. Имя механизму – Timeout Detection and Recovery (TDR). В сети предлагается ряд способов обхода этого механизма. В моих экспериментах не все случаи удалось просчитать. Возможно возникновение ситуации Q связано с большим объемом вычислений в алгоритме из работы [5] в каждом узле дерева трассировки.
7. Заключение
В данной работе сделана попытка ознакомить читателя с некоторыми экспериментами по применению OptiX для разработки приложения, базирующегося на трассировке лучей (путей). OptiX может оказаться полезным и для исследователей, задача которых не базируетс на трассировке лучей (примеры на рис. 2, 3, 4) и которым необходимо иметь подручный кластер для проведения численных экспериментов. Правда, в этом случае структуры ускорения операции пересечения луча с геометрией сцены, чему в OptiX уделено много внимания, не будут востребованы.
· OptiX оказался удобным инструментом для приложений, базирующихся на трассировке лучей.
· Появляется возможность превратить свой десктоп или ноутбук в небольшой кластер.
· Поскольку вполне достаточное подмножество API OPtiX (без прямого использования DirectX и CUDA) ориентировано на создание достаточно широкого класса приложений, то можно ожидать, что кто-нибудь реализует OptiX на других типах ГП.
· При возникновении непонятных ситуаций и для получения достаточно оперативных консультаций полезен форум для общения с пользователями и разработчиками OptiX [8].
В целом, автор постарался обосновать полезность применения OptiX в противовес CUDA и MPI, исходя из следующих рассуждений:
· Время изучения CUDA плюс время отладки алгоритма может значительно превышать время отладки алгоритма при помощи программы, написанной на основе OptiX.
· Использование удаленного кластера не всегда рационально, имея возможность организовать подручный кластер на рабочем месте, если учесть, что мощность ГП ежегодно возрастает.
· Чем разнообразнее набор инструментов, тем гибче можно организовать процесс.
8. Благодарности
Исследование выполнено при финансовой поддержке РФФИ в рамках разработки научного проекта № 12-07-00386 а.
Список литературы
[1] Альманах Nvidia CUDA. Available at: http://www.nvidia.ru/object/cuda-parallel-computing-almanac-ru.html.
[2] Parker S.G. OptiX: A General Purpose Ray Tracing Engine. Siggraph 2010.
[3] NVIDIA® OptiX™ ray tracing engine, Programming_Guide. Available at: https://developer.nvidia.com/optix.
[4] Bondarev A.E., Galaktionov V.A. Parametric optimizing analysis of unsteady structures and visualization of multidimensional data, Int. J. Model. Simul. Sci. Comput. 04, Iss. Supp01, pp. 1341004-1 – 1341004-13, Aug. 2013, DOI: 10.1142/S1793962313410043. Available at: http://www.worldscientific.com/doi/abs/10.1142/S1793962313410043.
[5] Бондарев А, Галактионов В., Шапиро Л., Анализ и визуализация многомерных данных в задачах вычислительной газовой динамики, Труды 24-й Международной конференции по компьютерной графике и зрению ГрафиКон’2014, с. 146–149. Available at: http://2014.graphicon.sfedu.ru/res/Trudi_GraphiCon_2014.pdf.
[6] Debelov V. A., Kozlov D. S. Visualization of light polarization to debug ray tracing algorithms. Scientific Visualization, vol. 5, № 5, 2013, pp. 71–87. Available at: http://www.sv-journal.org/2013-4/059ed2.html?lang=en.
[7] Debelov V. A., Kozlov D. S., A Local Model of Light Interaction with Transparent Crystalline Media," IEEE Transactions on Visualization and Computer Graphics – 2013. – Vol. 19, No. 8, pp. 1274-1287.
[8] Nvidia OptiX Forum. Available at: https://devtalk.nvidia.com/default/board/90/optix/1/.
APPLICATION OF NVIDIA OPTIX TO CARRY OUT NUMERICAL EXPERIMENTS
V.A. Debelov
Institute of Computational Mathematics and Mathematical Geophysics SB RAS, Novosibirsk, Russia
Abstract
A lot of research programs are implemented in order to carry out numerical experiments while debugging of an algorithm or obtaining different data of an investigated computer model. As a rule the data are visualized by means of scientific visualization tools. In these paper the author considers reasons to apply Nvidia OptiX as a tool to carry out numerical experiments using graphical processing units (GPU) GeForce.
Although OptiX is built on CUDA and runs on a graphical unit, a researcher does not have to know programming elements such as an architecture of GPU, CUDA, OpenGL, DirectX. By the way, a knowledge of programming for a cluster – for example, MPI (Message Passing Interface) – is also not needed.
OptiX is considered as an effective tool to control a run of a loop
i = 0 .. N
j = 0 .. M
k = 0 .. K
f(i, j, k, <additional parameters >),
where f(i, j, k, < additional parameters >)
is an algoritm being debugged or tested computer model.
From the author’s point of view GPU considered can be imagined as a desktop cluster including multiple processors working in parallel on shared memory. A researcher can use a PC in parallel at his discretion while his program runs on GPU.
To justify a suggested approach the author shows with several tests a speedup rate of an OptiX program in comparison with a sequential program.
Key words: numerical experiment, scientific visualization, ray tracing, Nvidia GPU, CUDA, OptiX.
References
[1] Nvidia CUDA Almanac. Available at: http://www.nvidia.ru/object/cuda-parallel-computing-almanac-ru.html.
[2] Parker S.G. OptiX: A General Purpose Ray Tracing Engine. Siggraph 2010.
[3] NVIDIA® OptiX™ ray tracing engine, Programming_Guide. Available at: https://developer.nvidia.com/optix.
[4] Bondarev A.E., Galaktionov V.A. Parametric optimizing analysis of unsteady structures and visualization of multidimensional data, Int. J. Model. Simul. Sci. Comput. 04, Iss. Supp01, pp. 1341004-1 – 1341004-13, Aug. 2013, DOI: 10.1142/S1793962313410043. Available at: http://www.worldscientific.com/doi/abs/10.1142/S1793962313410043.
[5] Bondarev A, Galaktionov V., Shapiro L., Analiz i vizualizacija mnogomernyh dannyh v zadachah vychislitel'noj gazovoj dinamiki [Analysis and visualization of multidimensional data in problems of computational fluid dynamics], Proceedings of Graphicon’2014, pp. 146–149. Available at: http://2014.graphicon.sfedu.ru/res/Trudi_GraphiCon_2014.pdf.
[6] Debelov V. A., Kozlov D. S. Visualization of light polarization to debug ray tracing algorithms. Scientific Visualization, vol. 5, № 5, 2013, pp. 71–87. Available at: http://www.sv-journal.org/2013-4/059ed2.html?lang=en.
[7] Debelov V. A., Kozlov D. S., A Local Model of Light Interaction with Transparent Crystalline Media," IEEE Transactions on Visualization and Computer Graphics – 2013. – Vol. 19, No. 8, pp. 1274-1287.
[8] Nvidia OptiX Forum. Available at: https://devtalk.nvidia.com/default/board/90/optix/1/.