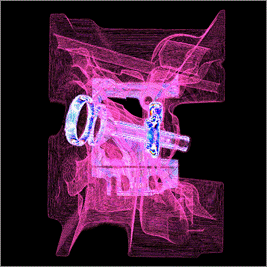Полноэкранное сглаживание в
реализации предынтегрированного
рендеринга для визуализации трехмерных скалярных
полей на GPU
Д. Боголепов, И. Бугаев, А. Белокаменская,
В. Турлапов
Нижегородский
государственный университет им. Н.И. Лобачевского
denisbogol@gmail.com, bugaevio@gmail.com, alexandra.belokamenskaya@gmail.com, vadim.turlapov@cs.vmk.unn.ru
Оглавление
2.1 Интеграл объемной визуализации
2.4 Пред- и
пост-классификация
2.6 Предынтегрированная
классификация
2.7 Упрощенное предынтегрирование
2.8 Стратегии вычисления цвета
3. РЕАЛИЗАЦИЯ АЛГОРИТМА НА ГПУ
Аннотация
В работе рассматриваются
возможные вариации GPU-алгоритма Volume Raycasting, применяемого в
научной визуализации трехмерных скалярных полей, в случае использования в нем предынтегрированной (pre-integrated) классификации визуализируемых
данных. Предложен метод генерации нескольких лучей на пиксель, позволяющий
одновременно решать задачу полноэкранного антиалиасинга (FSAA) и дополнительно улучшить качество визуализации,
достигаемое с помощью предынтегрированного рендеринга. Предложено использовать когерентность субпиксельных лучей для оптимизации вычислений (в
тестируемой версии генерируется 5 лучей на пиксель). В дополнение к порядку
трассировки front-to-back исследован порядок back-to-front, что может оказаться полезным
при необходимости трассировки всего пути без ранней остановки луча (early ray termination). Тестовая
реализация предложенных методов выполнена на шейдерном
языке высокого уровня GLSL. Производительность методов исследована на шести
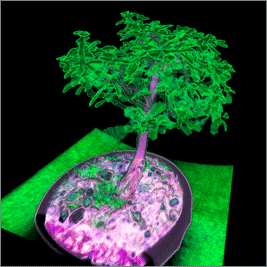
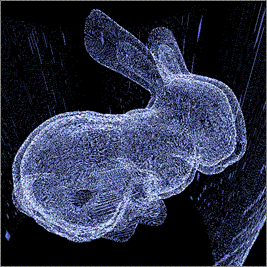
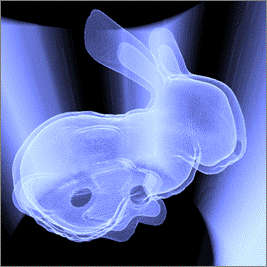
примерах данных, самым сложным из которых был Stanford Bunny (512x512x361, 16bit). Использован графический процессор NVIDIA GeForce 560 1 Гб под управлением ОС Ubuntu Linux 10.10 и видеодрайвера NVIDIA Linux Graphics Driver 275.36.
Визуализация выполнялась в режимах постклассификации
и предынтегрированной классификации, для прямого и
обратного алгоритма вычисления цвета. Обсуждаются причины эффективности предынтегрированного рендеринга.
Ключевые слова: direct volume rendering, ray casting, post-classification,
pre-integrated classification, full-screen-anti-aliasing, GPU, OpenGL, GLSL.
1. ВВЕДЕНИЕ
Объемная визуализация – метод
формирования изображения, который для трехмерного набора данных отображает не
только общий вид, но и внутреннее строение трехмерного объекта. В качестве
входного набора данных часто выступает множество плоских изображений слоев,
полученных с помощью компьютерной или магнитно-резонансной томографии. Обычно
слои имеют равную толщину и одинаковое число пикселей на каждый слой. Таким
образом, входные данные можно представить регулярной пространственной сеткой,
каждому узлу которой ставится в соответствие значение некоторого скалярного
поля.
Существует большое разнообразие
методов визуализации объема, однако наилучшие результаты обеспечивает алгоритм
трассировки лучей, который естественным образом вычисляет интеграл объемного рендеринга. Значительное влияние на результирующее
изображение также оказывает метод классификации, посредством которого
конкретным значениям скалярного поля ставится в соответствие набор оптических
свойств. Высокое качество обеспечивает так называемая предынтегрированная классификация, которая была предложена
в работе [1]. Однако доступная на тот момент
аппаратура не поддерживала программируемый графический конвейер, поэтому метод
был реализован с помощью техники слоев [2]. С ростом возможностей программируемых
графических процессоров появились интерактивные реализации прямого объемного рендеринга на основе метода Ray Casting [3]. В публикации [4] авторы представили программный каркас
системы объемной визуализации с использованием предынтегрированной
классификации и такими эффектами, как объемные тени и освещение, что требует
обязательного вычисления нормалей, а значит градиентов исходных данных.
Исследованию различных методов интегрирования посвящена работа [5], в которой авторы предложили использовать интерполяцию
второго порядка для предынтегрированного рендеринга.
Отметим также работы, направленные на повышение качества
визуализации, за счет гладкой интерполяции нормалей [6], и
производительности, за счет поверхностной и объемной когерентности
[7].
Настоящая работа также посвящена
улучшению качества и производительности популярного метода предынтегрированного
объемного рендеринга, в основе которого лежит метод
испускания лучей. Рассматриваются особенности реализации предынтегрированной
классификации на графическом процессоре и исследуются ее преимущества по
сравнению с традиционной пост-классификацией.
Предлагается ряд оптимизационных стратегий, направленных на улучшение качества
изображения и повышение скорости работы. Приводится сравнительный анализ
различных вариантов реализации метода.
2. ОСНОВНЫЕ МОДЕЛИ и МЕТОДЫ
2.1 Интеграл объемной визуализации
Предположим, что луч x(t) параметризован расстоянием t от объектива
виртуальной камеры, а излучаемая яркость intensity(x) и коэффициент
затухания extinction(x) могут быть
вычислены в любой точке x пространства. Интеграл объемной
визуализации [1] описывает процесс накопления яркости вдоль луча с учетом ее затухания в зависимости от расстояния до точки
наблюдения:
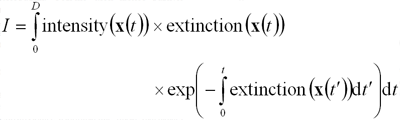 |
(1) |
Здесь через D обозначено
расстояние, на которое луч проникает в объем (в большинстве случаев
определяется временем выхода из ограничивающей оболочки).
2.2 Скалярное поле
На практике скалярное поле s(x) часто задается
регулярной трехмерной сеткой, каждому узлу vi которой ставится в соответствие
значение поля si. Для вычисления поля в
произвольной точке пространства выполняется
интерполяция. Порядок данной интерполяции существенно влияет на качество
генерируемого изображения. Современные графические процессоры аппаратно поддерживают
трилинейную фильтрацию. Лучшие результаты
обеспечивает трикубическая фильтрация, которая может
быть реализована через 8 операций трилинейной
фильтрации [8].
2.3 Передаточные функции
Преобразование скалярного поля s(x) в яркость
излучаемого света и коэффициент затухания называется классификацией. Данное
преобразование выполняется путем задания передаточных функций для вычисления
излучаемой яркости L(s) и коэффициента затухания t(s). При наличии
передаточных функций интеграл (1) записывается в виде:
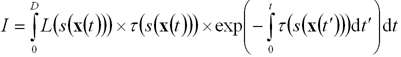 |
(2) |
В ряде случаев для вычисления
яркости L(s) в конкретной точке
луча x(t) могут
использоваться алгоритмы затенения, основанные на различных моделях освещения
(таких как модели Блинна-Фонга или Эми Гуч).
2.4 Пред- и
пост-классификация
В зависимости от способа
вычисления воздействия передаточных функций (transfer function, TF) выделяют различные типы
классификации. В случае постклассификации TF
применяются после интерполяции скалярного поля s(x). В случае предклассификации излучаемая яркость и коэффициент
затухания вычисляются на этапе препроцессирования для
каждого узла сетки vi и используются для
интерполяции в произвольной точке пространства. На практике данный подход
практически не применяется по двум причинам: 1) мы заменяем каждое скалярное
значение векторным (RGB или индексированным цветом и прозрачностью) и,
как следствие, вынуждены значительно
увеличить память; 2) теряем возможность вычислять
градиент скалярного поля (для компенсации этого нужно дополнительно держать в
памяти исходный массив данных). Метод постклассификации
свободен от недостатков предклассификации, но имеет
свои не менее серьезные недостатки.
Главным недостатком постклассификации являются искажения цвета, часто хорошо
видимые глазом в виде колец или полос. Эти артефакты возникают в местах значительного
изменения скалярного поля при переходе луча на 1 воксель.
Все интерполированные значения скалярного поля получат цвет и прозрачность из TF, то есть результаты интерполяции
будут промодулированы в том
числе не имеющими отношения к реальности цветами и прозрачностями,
установленными в TF. Чем более сложной будет функция трансформации, тем сильнее будут
артефакты. Именно от этой проблемы в значительной мере и спасает предытегрированный рендеринг.
2.5 Численное интегрирование
В большинстве случаев для оценки
интеграла (2) используется простой метод прямоугольников. Будем считать, что
отрезок интегрирования разбивается на n элементарных отрезков равной
длины d = D / n. Тогда справедливы
следующие квадратурные формулы:
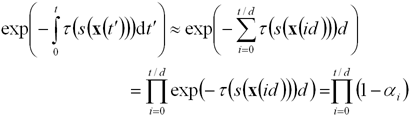 |
(3) |
Здесь через αi обозначена непрозрачность i-ого сегмента луча.
Разложение экспоненты в ряд Тейлора позволяет дополнительно упростить
выражение:
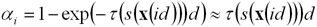 |
(4) |
Данная формула предпочтительна в
задачах визуализации реального времени, поскольку вычисление экспоненциальной
функции существенно снижает производительность. Аналогичную оценку можно
получить для яркости, излучаемой i-ым
сегментом луча:
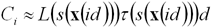 |
(5) |
В результате, получаем следующую
аппроксимацию для интеграла (2):
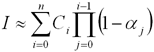 |
(6) |
Полученная аппроксимация сходится
при d → 0.
На практике для точной оценки непрерывного подынтегрального выражения
необходимо рационально выбрать шаг дискретизации. Для понимания сути проблемы
уместно обратиться к теореме отсчетов (Котельникова-Найквиста), согласно
которой корректное восстановление аналогового сигнала возможно только по
дискретным отсчетам, взятым с частотой строго большей удвоенной верхней частоты
сигнала (или частоты Найквиста). Модуляция
интерполированных значений поля передаточной функцией приводит к
значительному повышению частоты дискретизации, поскольку частота Найквиста у
подынтегрального выражения в худшем случае оценивается произведением данных
частот у поля s(x) и передаточных
функций L(s) и t(s). Хотя только
механическое дробление шага не устранит проблему, а лишь сделает ее менее
заметной.
2.6 Предынтегрированная
классификация
Предынтегрированная классификация,
которая является эффективным способом борьбы с высокими частотами Найквиста,
подробно рассматривается в работе [1]. Основная идея сводится к декомпозиции вычислений на
интегрирование скалярного поля s(x) и интегрирование
передаточных функций L(s) и t(s). Для этого на этапе препроцессирования
генерируются таблицы, с помощью которых можно получить яркость и непрозрачность
произвольного сегмента луча во время визуализации. В общем случае для обращения
к таблицам используется три аргумента: значение поля в начальной точке сегмента
sf = s(x(id)), значение поля в
конечной точке сегмента sb = s(x(id + d)) и длина сегмента d. Если же лучи разбиваются
на сегменты равной длины, то число аргументов сокращается до двух.
Непрозрачность i-ого сегмента выражается
формулой:
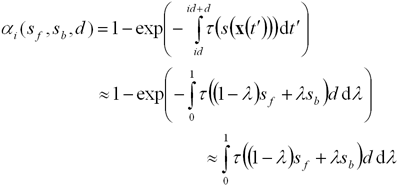 |
(7) |
Аналогично оценивается яркость i-ого сегмента луча:
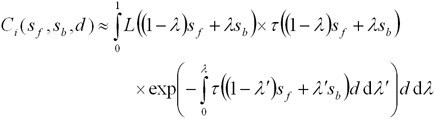 |
(8) |
Таким образом, предынтегрированная классификация позволяет не увеличивать
частоту дискретизации для скачкообразных передаточных функций. В итоге имеется
потенциал для улучшения качества визуализации и уменьшения числа интервалов
дискретизации на этапе визуализации объема.
2.7 Упрощенное предынтегрирование
Основной недостаток предынтегрированной классификации связан с необходимостью
вычисления таблиц, с помощью которых каждому набору параметров sf, sb и d ставится в соответствие яркость сегмента и его
непрозрачность. Указанные таблицы зависят от передаточных функций, поэтому
требуют повторного построения при их модификации. Данное построение может быть
эффективно выполнено на графическом процессоре, что позволит модифицировать
передаточные функции в реальном времени.
Альтернативным вариантом является
аппроксимированная предынтегрированная классификация [1], которая без видимого снижения качества позволяет
ограничиться быстрым предварительным вычислением двух первообразных
функций:
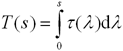 |
(9) |
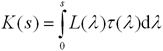 |
(10) |
С использованием данных функций формулы
(7) и (8) могут быть преобразованы следующим образом:
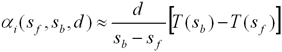 |
(11) |
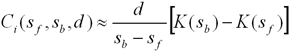 |
(12) |
Выражение (12) предполагает
отсутствие затухания в пределах одного сегмента луча, что оправданно при малом
интервале дискретизации.
2.8 Стратегии вычисления цвета
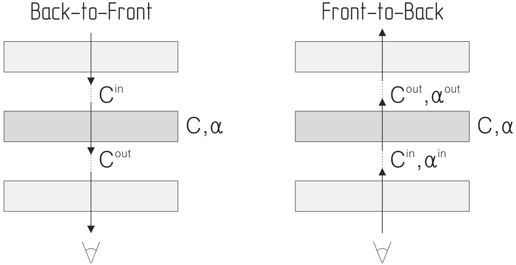
Рис. 1: Стратегии накопления цвета.
На основе аппроксимации (6)
строится алгоритм обратного (back-to-front) вычисления цвета
пикселя:
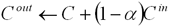 |
(13) |
Алгоритм прямого
(front-to-back) вычисления цвета
также возможен, однако требует дополнительных ресурсов для поддержки
коэффициента непрозрачности:
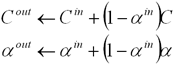 |
(14) |
Несмотря на использование
дополнительных регистров и большее число операций в цикле трассировки, алгоритм
прямого вычисления цвета часто более предпочтителен за счет возможности ранней
остановки луча (early ray termination). В настоящей работе реализованы
обе стратегии трассировки.
2.9 Стратегии генерации лучей
В типовой реализации метода
объемного рендеринга цвет каждого пикселя вычисляется
с помощью одного первичного луча, для оценки яркости которого используется S интервалов
дискретизации. В качестве альтернативного подхода можно предложить генерацию R лучей на пиксель,
начальные точки которых последовательно смещаются в пределах интервала
дискретизации, а число интервалов сокращается до S / R. Очевидно, что
вычислительные затраты в обоих случаях одинаковы, однако второй подход имеет
ряд преимуществ.
Во-первых, программный код имеет
большую степень параллелизма, поскольку лучи в пределах пикселя обрабатываются
независимо. Шейдерный компилятор получает возможность
эффективного распараллеливания инструкций, что ведет к более полному
использованию ресурсов ГПУ.
Во-вторых, данный подход
позволяет реализовать практически бесплатное полноэкранное сглаживание (FSAA). Для этого каждый
из R лучей необходимо
дополнительно смещать в пределах пикселя экранной плоскости. При этом
эффективно устраняется не только эффект ступенчатости изображения, но и мелкие
(сопоставимые с размерами пикселя) артефакты визуализации.
В-третьих, лучи в пределах
пикселя характеризуются высокой пространственной когерентностью, что позволяет
дополнительно повысить быстродействие. Трассировка первого луча через центр
пикселя в качестве побочного результата дает оценку расстояния, которое луч
преодолел в пустом пространстве. Данная информация позволяет трассировать
остальные лучи сразу со значимой области исследуемого объема. В ряде случаев
такая оптимизация увеличивает скорость работы в несколько раз, поскольку
значительно сокращается число наиболее трудоемких операций – выборок из
трехмерной текстуры скалярного поля (оценки производительности приводятся
далее).
3. РЕАЛИЗАЦИЯ АЛГОРИТМА НА ГПУ
Несмотря на широкую доступность
таких универсальных инструментов программирования ГПУ как NVIDIA CUDA и OpenCL, в настоящей работе
для этой цели использовался интерфейс OpenGL и его шейдерный
язык GLSL (OpenGL Shading Language). Богатый набор
встроенных типов данных и широкие функциональные возможности позволяют в
естественном виде записывать алгоритм испускания лучей. К достоинствам подхода
следует также отнести поддержку графических ускорителей от различных
производителей. Интерфейс OpenGL и его язык шейдеров
являются межплатформенным стандартом, что позволяет использовать единый
программный код для поддержки самых различных платформ.
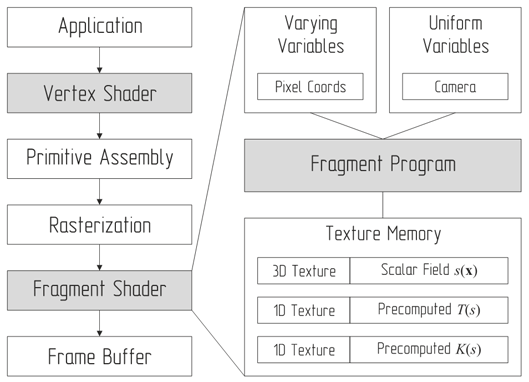
Рис. 2: Схема работы алгоритма визуализации.
Существует стандартный подход к
отображению алгоритма испускания лучей на программируемый графический конвейер.
Для инициирования вычислений следует установить параллельную проекцию и
нарисовать прямоугольник, заполняющий всю область видимости в окне размера N × M пикселей. На этапе
растеризации данного прямоугольника будет сгенерировано ровно N × M фрагментов,
соответствующих пикселям в буфере кадра. Каждый сгенерированный фрагмент
обрабатывается фрагментным шейдером,
на вход которому передаются координаты пикселя и данные для визуализации.
Располагая всей необходимой информацией, фрагментный шейдер
генерирует первичный луч (несколько лучей) и трассирует его через объем
согласно изложенному выше алгоритму. Шейдерный язык GLSL поддерживает
директивы препроцессора, с помощью которых можно быстро переключаться между
блоками кода, реализующими различные методы визуализации. В тестовой версии
программы пользователь может выбирать между пост-классификацией и предынтегрированной
классификацией, а также между прямым и обратным алгоритмом прохода по лучу.
4. АНАЛИЗ
РЕЗУЛЬТАТОВ
Для оценки качества и скорости
работы рассмотренных алгоритмов использовались широко известные данные для
объемной визуализации [9]. Расчеты производились на графическом процессоре начального уровня NVIDIA GeForce 560 1 Гб под управлением ОС Ubuntu Linux 10.10 и видеодрайвера NVIDIA Linux Graphics Driver 275.36.
Визуализация выполнялась в режимах пост-классификации
и предынтегрированной классификации, при этом
сравнивались прямой и обратный алгоритм вычисления цвета. Для обработки каждого
пикселя генерировалось 5 лучей, каждый из которых разбивался не более чем на
120 интервалов. Таким образом, общее число дискретных отсчетов на пиксель не
превышало 600, что является скромным показателем для современной графической
аппаратуры. Для каждого режима визуализации выполнялось два замера: без
использования и с использованием когерентности субпиксельных
лучей. В следующей таблице представлены характеристики входных
данных и результаты эксперимента.
Таблица 1: Результаты замера производительности
(кадров / секунду, окно 512 × 512 пикселей).
|
Description |
Dimensions Bits |
Post-classification |
Pre-integrated classification |
||
|
Front-to-Back |
Back-to- Front |
Front-to-Back |
Back-to- Front |
||
|
Bucky |
32 × 32 × 32 |
120 / 142 |
82 / 119 |
150 / 152 |
75 / 140 |
|
Daisy |
192 × 180 × 168 |
59 / 100 |
58 / 98 |
66 / 108 |
66 / 112 |
|
Engine |
256 × 256 × 256 |
71 / 118 |
67 / 130 |
74 / 110 |
71 / 130 |
|
Bonsai |
512 × 512 × 154 |
61 / 128 |
63 / 89 |
66 / 114 |
51 / 90 |
|
Stanford |
512 × 512 × 361 |
36 / 92 |
38 / 79 |
38 / 47 |
34 / 44 |
|
Orange |
256 × 256 × 64 |
61 / 86 |
75 / 98 |
84 / 100 |
60 / 120 |
Экспериментальные данные
показывают, что предынтегрированная классификация
практически не вносит дополнительных затрат на этапе визуализации по сравнению
с пост-классификацией. В
данном случае скорость работы ограничивается производительностью текстурных
модулей, которые интенсивно используются для выборки и фильтрации значений
скалярного поля. Во всех режимах работы число данных операций остается
неизменным.
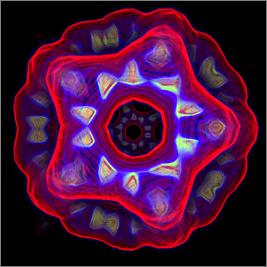
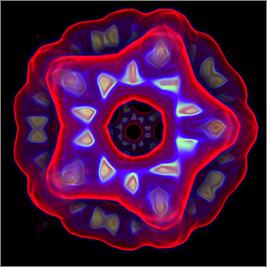
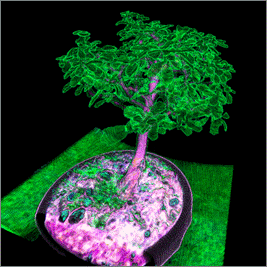
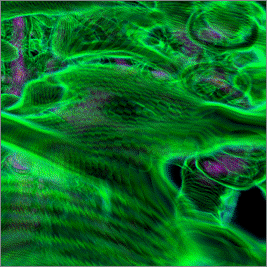
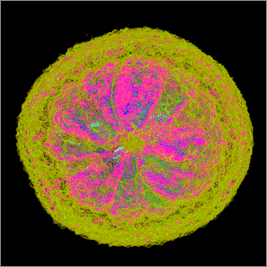
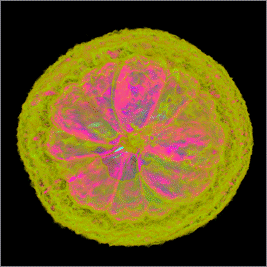
Предынтегрированная классификация (рис.
3) обеспечивает значительно более высокое качество изображения при
использовании всего 600 интервалов дискретизации на каждый пиксель. Таким образом,
в особо трудных случаях (при работе с высокочастотными передаточными функциями
и скалярным полем) остается значительный ресурс повышения качества за счет
увеличения числа интервалов (вплоть до нескольких раз при сохранении реального
времени).